 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reward Supervisions for Tuning Text-to-Image Diffusion Models
Paper and Code
May 01, 2024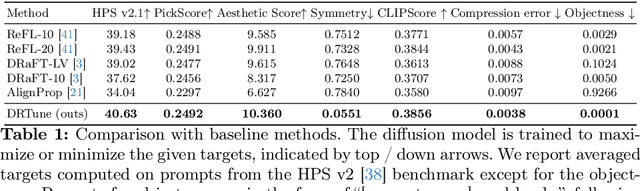
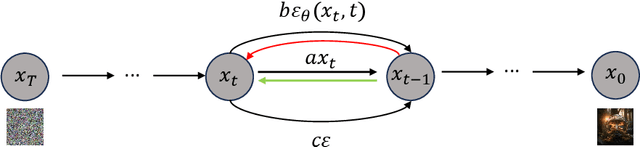
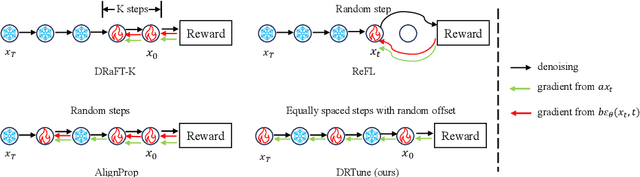

Optimizing a text-to-image diffusion model with a given reward function is an important but underexplored research area. In this study, we propose Deep Reward Tuning (DRTune), an algorithm that directly supervises the final output image of a text-to-image diffusion model and back-propagates through the iterative sampling process to the input noise. We find that training earlier steps in the sampling process is crucial for low-level rewards, and deep supervision can be achieved efficiently and effectively by stopping the gradient of the denoising network input. DRTune is extensively evaluated on various reward models. It consistently outperforms other algorithms, particularly for low-level control signals, where all shallow supervision methods fail. Additionally, we fine-tune Stable Diffusion XL 1.0 (SDXL 1.0) model via DRTune to optimize Human Preference Score v2.1, resulting in the Favorable Diffusion XL 1.0 (FDXL 1.0) model. FDXL 1.0 significantly enhances image quality compared to SDXL 1.0 and reaches comparable quality compared with Midjourney v5.2.