 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwin Co-Adaptive Dialogue for Progressive Image Generation
Paper and Code
Apr 21, 2025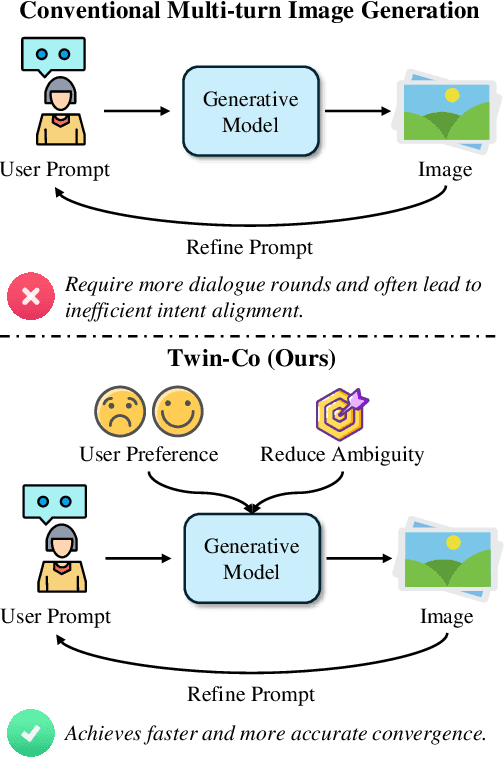
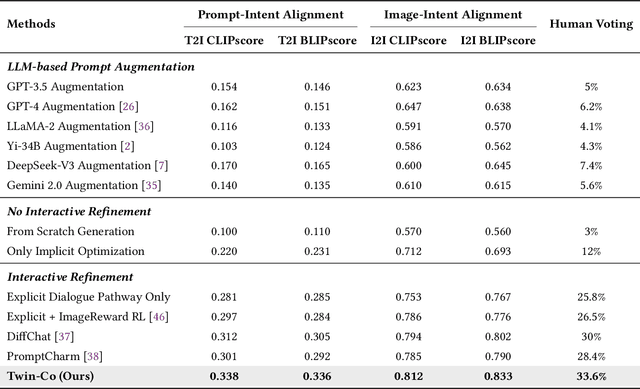
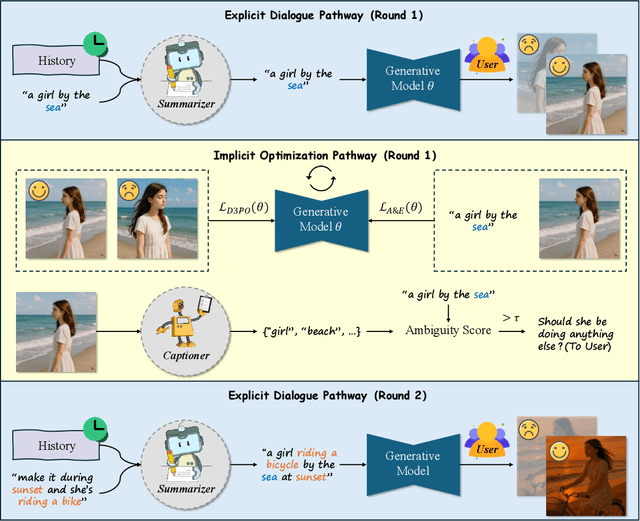

Modern text-to-image generation systems have enabled the creation of remarkably realistic and high-quality visuals, yet they often falter when handling the inherent ambiguities in user prompts. In this work, we present Twin-Co, a framework that leverages synchronized, co-adaptive dialogue to progressively refine image generation. Instead of a static generation process, Twin-Co employs a dynamic, iterative workflow where an intelligent dialogue agent continuously interacts with the user. Initially, a base image is generated from the user's prompt. Then, through a series of synchronized dialogue exchanges, the system adapts and optimizes the image according to evolving user feedback. The co-adaptive process allows the system to progressively narrow down ambiguities and better align with user intent. Experiments demonstrate that Twin-Co not only enhances user experience by reducing trial-and-error iterations but also improves the quality of the generated images, streamlining the creative process across various applications.