 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum latent distributions in deep generative models
Aug 27, 2025Many successful families of generative models leverage a low-dimensional latent distribution that is mapped to a data distribution. Though simple latent distributions are commonly used, it has been shown that more sophisticated distributions can improve performance. For instance, recent work has explored using the distributions produced by quantum processors and found empirical improvements. However, when latent space distributions produced by quantum processors can be expected to improve performance, and whether these improvements are reproducible, are open questions that we investigate in this work. We prove that, under certain conditions, these "quantum latent distributions" enable generative models to produce data distributions that classical latent distributions cannot efficiently produce. We also provide actionable intuitions to identify when such quantum advantages may arise in real-world settings. We perform benchmarking experiments on both a synthetic quantum dataset and the QM9 molecular dataset, using both simulated and real photonic quantum processors. Our results demonstrate that quantum latent distributions can lead to improved generative performance in GANs compared to a range of classical baselines. We also explore diffusion and flow matching models, identifying architectures compatible with quantum latent distributions. This work confirms that near-term quantum processors can expand the capabilities of deep generative models.
BESS: Balanced Entity Sampling and Sharing for Large-Scale Knowledge Graph Completion
Nov 22, 2022
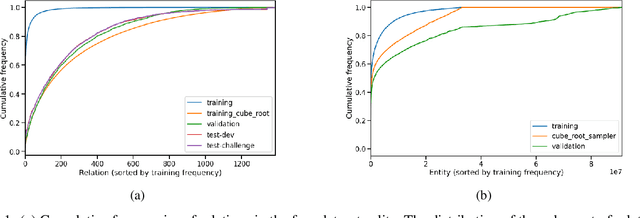

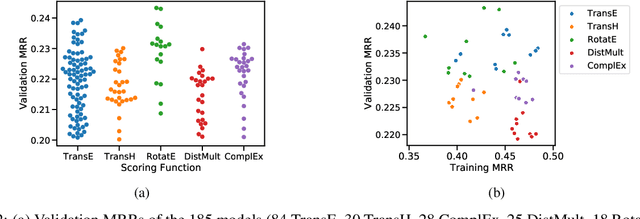
We present the award-winning submission to the WikiKG90Mv2 track of OGB-LSC@NeurIPS 2022. The task is link-prediction on the large-scale knowledge graph WikiKG90Mv2, consisting of 90M+ nodes and 600M+ edges. Our solution uses a diverse ensemble of $85$ Knowledge Graph Embedding models combining five different scoring functions (TransE, TransH, RotatE, DistMult, ComplEx) and two different loss functions (log-sigmoid, sampled softmax cross-entropy). Each individual model is trained in parallel on a Graphcore Bow Pod$_{16}$ using BESS (Balanced Entity Sampling and Sharing), a new distribution framework for KGE training and inference based on balanced collective communications between workers. Our final model achieves a validation MRR of 0.2922 and a test-challenge MRR of 0.2562, winning the first place in the competition. The code is publicly available at: https://github.com/graphcore/distributed-kge-poplar/tree/2022-ogb-submission.
WakeUpNet: A Mobile-Transformer based Framework for End-to-End Streaming Voice Trigger
Oct 06, 2022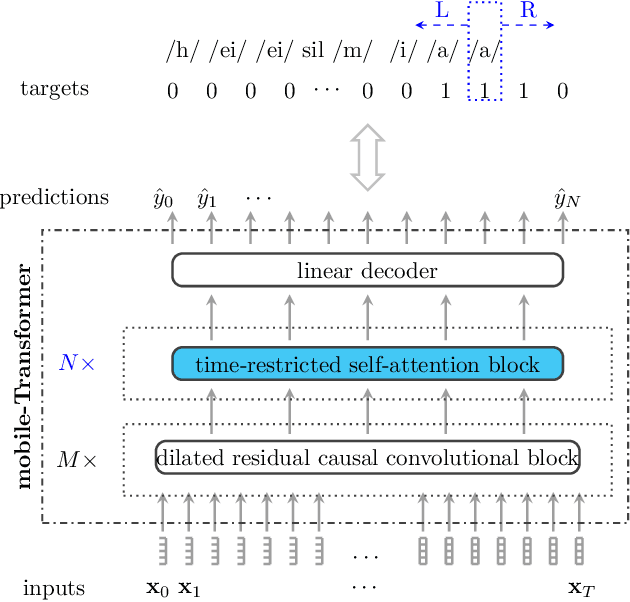
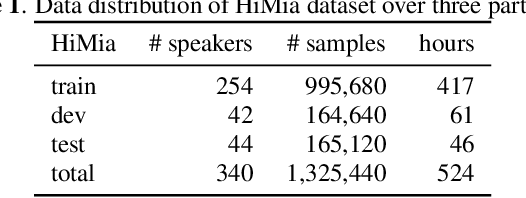
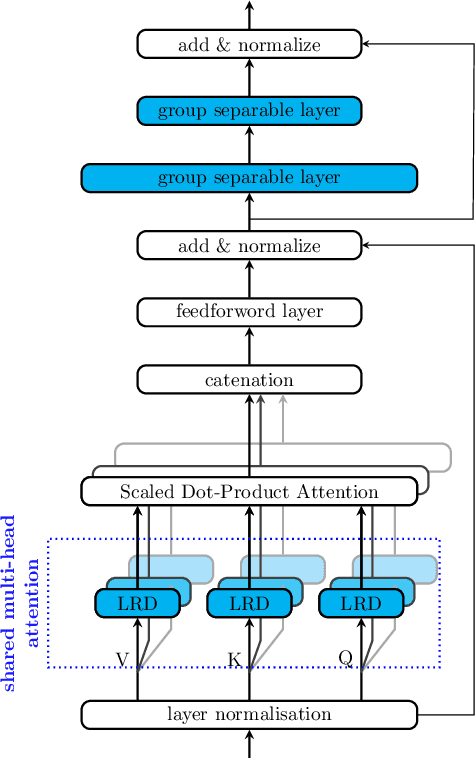
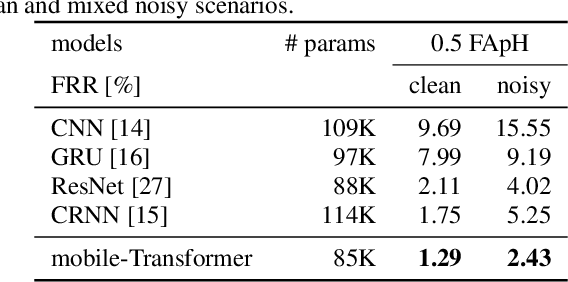
End-to-end models have gradually become the main technical stream for voice trigger, aiming to achieve an utmost prediction accuracy but with a small footprint. In present paper, we propose an end-to-end voice trigger framework, namely WakeupNet, which is basically structured on a Transformer encoder. The purpose of this framework is to explore the context-capturing capability of Transformer, as sequential information is vital for wakeup-word detection. However, the conventional Transformer encoder is too large to fit our task. To address this issue, we introduce different model compression approaches to shrink the vanilla one into a tiny one, called mobile-Transformer. To evaluate the performance of mobile-Transformer, we conduct extensive experiments on a large public-available dataset HiMia. The obtained results indicate that introduced mobile-Transformer significantly outperforms other frequently used models for voice trigger in both clean and noisy scenarios.