 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressive Machine Dubbing Through Phrase-level Cross-lingual Prosody Transfer
Jun 21, 2023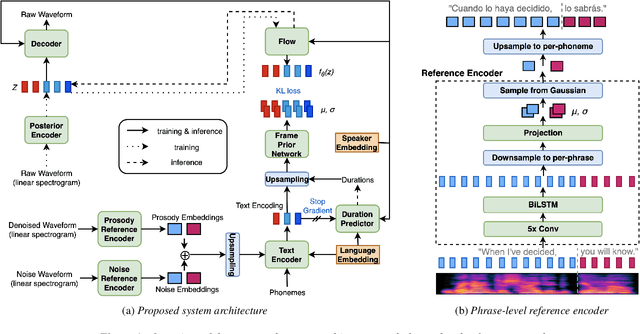
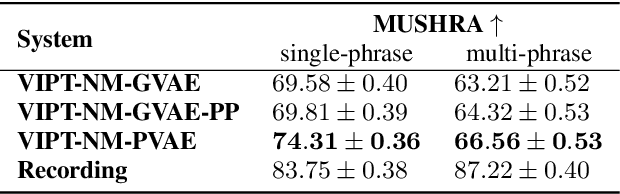
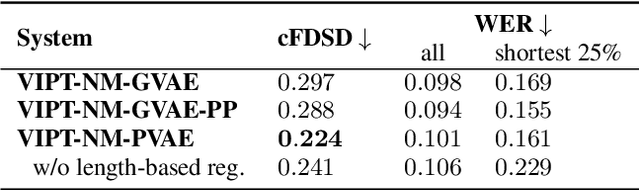
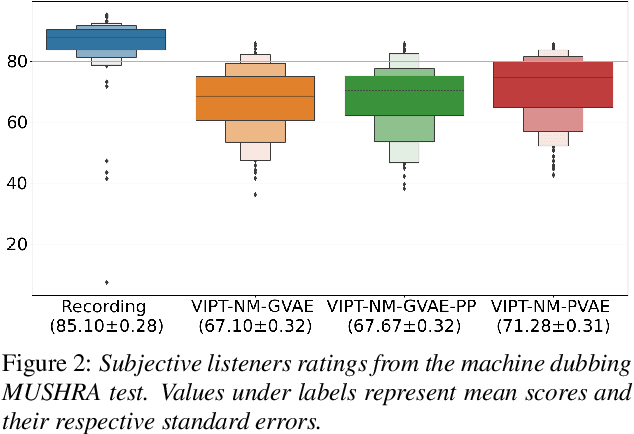
Speech generation for machine dubbing adds complexity to conventional Text-To-Speech solutions as the generated output is required to match the expressiveness, emotion and speaking rate of the source content. Capturing and transferring details and variations in prosody is a challenge. We introduce phrase-level cross-lingual prosody transfer for expressive multi-lingual machine dubbing. The proposed phrase-level prosody transfer delivers a significant 6.2% MUSHRA score increase over a baseline with utterance-level global prosody transfer, thereby closing the gap between the baseline and expressive human dubbing by 23.2%, while preserving intelligibility of the synthesised speech.
Cross-lingual Prosody Transfer for Expressive Machine Dubbing
Jun 20, 2023



Prosody transfer is well-studied in the context of expressive speech synthesis. Cross-lingual prosody transfer, however, is challenging and has been under-explored to date. In this paper, we present a novel solution to learn prosody representations that are transferable across languages and speakers for machine dubbing of expressive multimedia contents. Multimedia contents often contain field recordings. To enable prosody transfer from noisy audios, we introduce a novel noise modelling module that disentangles noise conditioning from prosody conditioning, and thereby gains independent control of noise levels in the synthesised speech. We augment noisy training data with clean data to improve the ability of the model to map the denoised reference audio to clean speech. Our proposed system can generate speech with context-matching prosody and closes the gap between a strong baseline and human expressive dialogs by 11.2%.
Voice Cloning: a Multi-Speaker Text-to-Speech Synthesis Approach based on Transfer Learning
Feb 10, 2021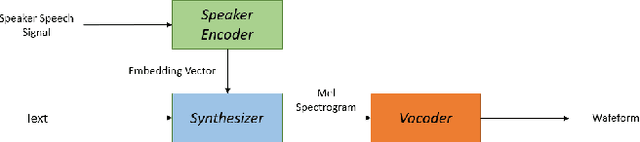
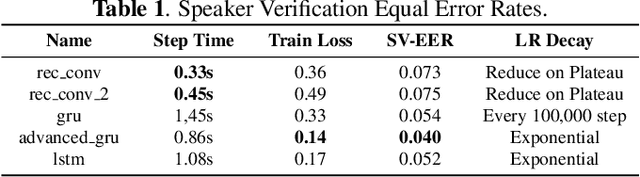
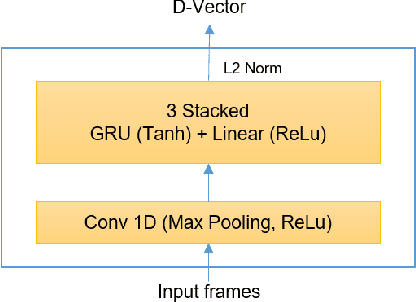
Deep learning models are becoming predominant in many fields of machine learning. Text-to-Speech (TTS), the process of synthesizing artificial speech from text, is no exception. To this end, a deep neural network is usually trained using a corpus of several hours of recorded speech from a single speaker. Trying to produce the voice of a speaker other than the one learned is expensive and requires large effort since it is necessary to record a new dataset and retrain the model. This is the main reason why the TTS models are usually single speaker. The proposed approach has the goal to overcome these limitations trying to obtain a system which is able to model a multi-speaker acoustic space. This allows the generation of speech audio similar to the voice of different target speakers, even if they were not observed during the training phase.