 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Electrolaryngeal Speech Enhancement Through Speech-Text Representation Learning
Jun 01, 2026Objective: laryngectomees depend on an electromechanical device to generate electrolaryngeal (EL) speech. Compared with normal speech, EL speech suffers from severe distortion, limited phonetic variation, unnatural prosody, and temporal shifts, degrading naturalness and intelligibility. Although sequence-to-sequence (seq2seq) voice conversion (VC) based EL-speech-to-normal-speech conversion (EL2SP) is promising, substantial mismatches between EL and normal speech inevitably cause cumulative mapping errors that limit performance. To address this, we describe a novel representation learning framework integrating speech and text representations to improve mapping and reconstruction quality within a seq2seq VC model. Methods: our methodology comprises two main stages: 1) representation integration and learning, and 2) reconstruction training. A network capable of incorporating auxiliary text information is first constructed with pretrained modules to learn speech--text-based integrated representations. Then, an autoencoder-style reconstruction strategy finalizes EL2SP model to inherit these representations without increasing model complexity. We introduce three fusion strategies including middle-, input-, and hybrid-level fusion strategies that progressively enhance learning. Moreover, besides standard seq2seq VC objectives, an additional reconstruction loss on the integrated representation is introduced to refine representation transfer. Results: experiments under different EL2SP datasets consistently demonstrate that our methods, combined with data augmentations, outperform baselines relying solely on speech representations. Furthermore, progressive improvements with system design depth validate the effectiveness of our methods. Significance: the proposed methods provide an extensible and practical methodology for EL speech enhancement and assistive communication technologies.
* 15 pages, 7 figures. Accepted to IEEE TBME
Electrolaryngeal Speech Intelligibility Enhancement Through Robust Linguistic Encoders
Sep 18, 2023



We propose a novel framework for electrolaryngeal speech intelligibility enhancement through the use of robust linguistic encoders. Pretraining and fine-tuning approaches have proven to work well in this task, but in most cases, various mismatches, such as the speech type mismatch (electrolaryngeal vs. typical) or a speaker mismatch between the datasets used in each stage, can deteriorate the conversion performance of this framework. To resolve this issue, we propose a linguistic encoder robust enough to project both EL and typical speech in the same latent space, while still being able to extract accurate linguistic information, creating a unified representation to reduce the speech type mismatch. Furthermore, we introduce HuBERT output features to the proposed framework for reducing the speaker mismatch, making it possible to effectively use a large-scale parallel dataset during pretraining. We show that compared to the conventional framework using mel-spectrogram input and output features, using the proposed framework enables the model to synthesize more intelligible and naturally sounding speech, as shown by a significant 16% improvement in character error rate and 0.83 improvement in naturalness score.
AAS-VC: On the Generalization Ability of Automatic Alignment Search based Non-autoregressive Sequence-to-sequence Voice Conversion
Sep 15, 2023



Non-autoregressive (non-AR) sequence-to-seqeunce (seq2seq) models for voice conversion (VC) is attractive in its ability to effectively model the temporal structure while enjoying boosted intelligibility and fast inference thanks to non-AR modeling. However, the dependency of current non-AR seq2seq VC models on ground truth durations extracted from an external AR model greatly limits its generalization ability to smaller training datasets. In this paper, we first demonstrate the above-mentioned problem by varying the training data size. Then, we present AAS-VC, a non-AR seq2seq VC model based on automatic alignment search (AAS), which removes the dependency on external durations and serves as a proper inductive bias to provide the required generalization ability for small datasets. Experimental results show that AAS-VC can generalize better to a training dataset of only 5 minutes. We also conducted ablation studies to justify several model design choices. The audio samples and implementation are available online.
Two-stage training method for Japanese electrolaryngeal speech enhancement based on sequence-to-sequence voice conversion
Oct 19, 2022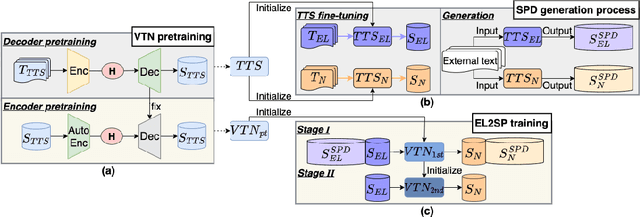
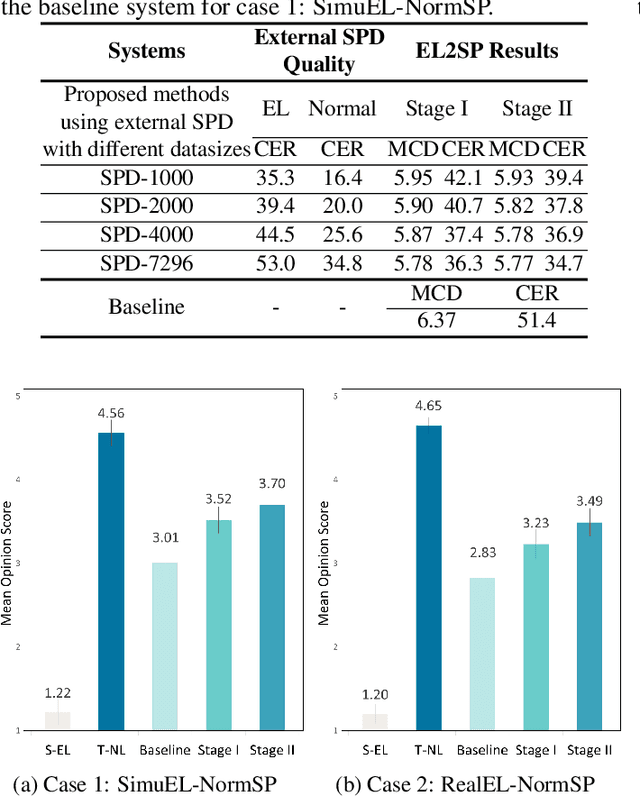

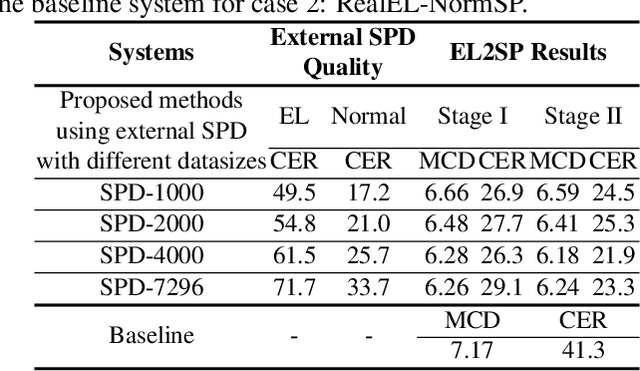
Sequence-to-sequence (seq2seq) voice conversion (VC) models have greater potential in converting electrolaryngeal (EL) speech to normal speech (EL2SP) compared to conventional VC models. However, EL2SP based on seq2seq VC requires a sufficiently large amount of parallel data for the model training and it suffers from significant performance degradation when the amount of training data is insufficient. To address this issue, we suggest a novel, two-stage strategy to optimize the performance on EL2SP based on seq2seq VC when a small amount of the parallel dataset is available. In contrast to utilizing high-quality data augmentations in previous studies, we first combine a large amount of imperfect synthetic parallel data of EL and normal speech, with the original dataset into VC training. Then, a second stage training is conducted with the original parallel dataset only. The results show that the proposed method progressively improves the performance of EL2SP based on seq2seq VC.
A Preliminary Study of a Two-Stage Paradigm for Preserving Speaker Identity in Dysarthric Voice Conversion
Jun 02, 2021


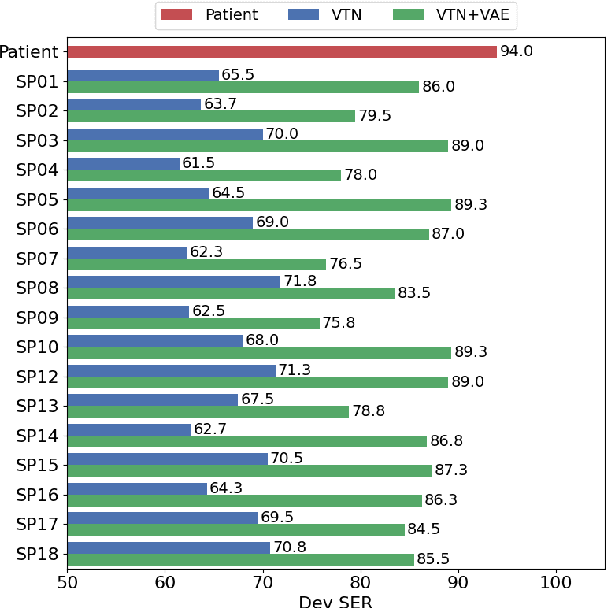
We propose a new paradigm for maintaining speaker identity in dysarthric voice conversion (DVC). The poor quality of dysarthric speech can be greatly improved by statistical VC, but as the normal speech utterances of a dysarthria patient are nearly impossible to collect, previous work failed to recover the individuality of the patient. In light of this, we suggest a novel, two-stage approach for DVC, which is highly flexible in that no normal speech of the patient is required. First, a powerful parallel sequence-to-sequence model converts the input dysarthric speech into a normal speech of a reference speaker as an intermediate product, and a nonparallel, frame-wise VC model realized with a variational autoencoder then converts the speaker identity of the reference speech back to that of the patient while assumed to be capable of preserving the enhanced quality. We investigate several design options. Experimental evaluation results demonstrate the potential of our approach to improving the quality of the dysarthric speech while maintaining the speaker identity.
Non-autoregressive sequence-to-sequence voice conversion
Apr 14, 2021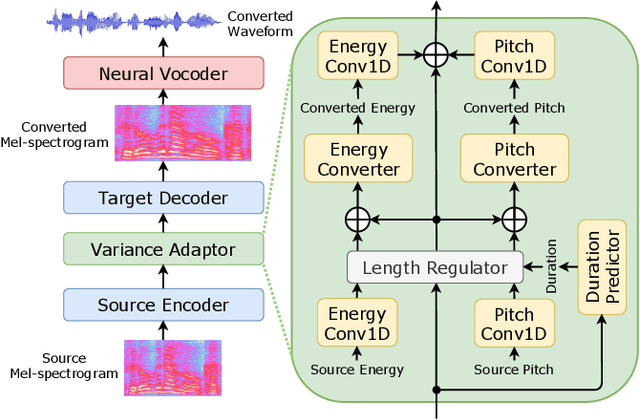
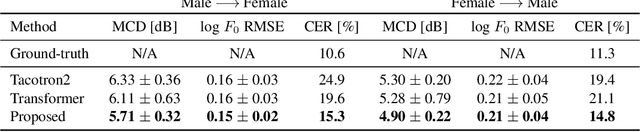
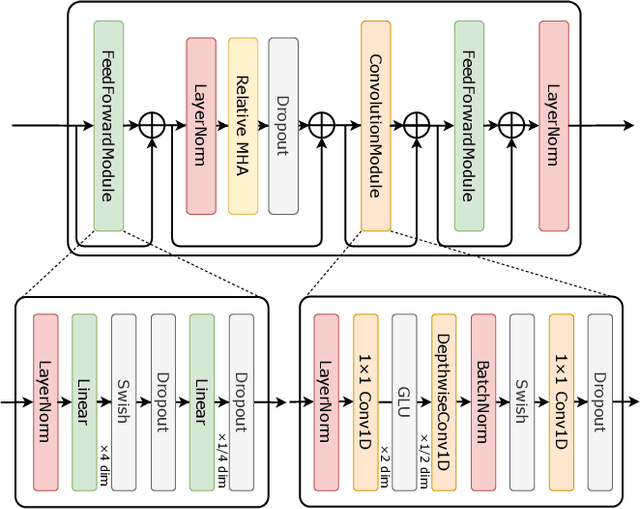

This paper proposes a novel voice conversion (VC) method based on non-autoregressive sequence-to-sequence (NAR-S2S) models. Inspired by the great success of NAR-S2S models such as FastSpeech in text-to-speech (TTS), we extend the FastSpeech2 model for the VC problem. We introduce the convolution-augmented Transformer (Conformer) instead of the Transformer, making it possible to capture both local and global context information from the input sequence. Furthermore, we extend variance predictors to variance converters to explicitly convert the source speaker's prosody components such as pitch and energy into the target speaker. The experimental evaluation with the Japanese speaker dataset, which consists of male and female speakers of 1,000 utterances, demonstrates that the proposed model enables us to perform more stable, faster, and better conversion than autoregressive S2S (AR-S2S) models such as Tacotron2 and Transformer.
crank: An Open-Source Software for Nonparallel Voice Conversion Based on Vector-Quantized Variational Autoencoder
Mar 04, 2021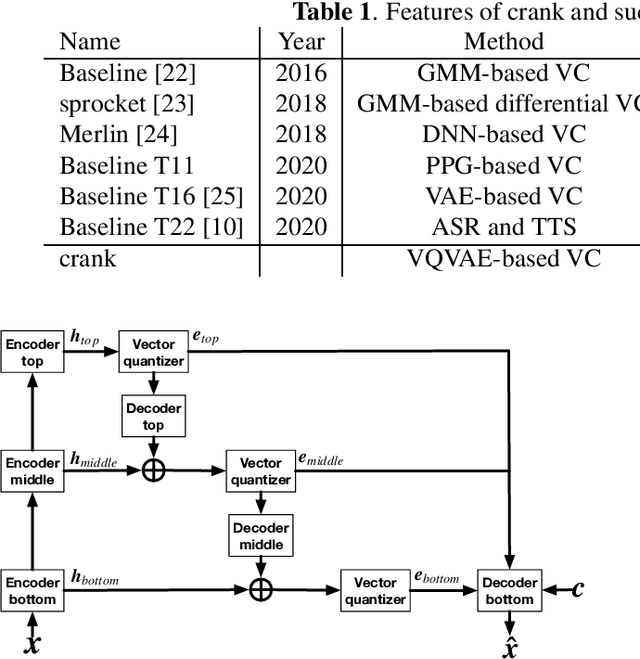

In this paper, we present an open-source software for developing a nonparallel voice conversion (VC) system named crank. Although we have released an open-source VC software based on the Gaussian mixture model named sprocket in the last VC Challenge, it is not straightforward to apply any speech corpus because it is necessary to prepare parallel utterances of source and target speakers to model a statistical conversion function. To address this issue, in this study, we developed a new open-source VC software that enables users to model the conversion function by using only a nonparallel speech corpus. For implementing the VC software, we used a vector-quantized variational autoencoder (VQVAE). To rapidly examine the effectiveness of recent technologies developed in this research field, crank also supports several representative works for autoencoder-based VC methods such as the use of hierarchical architectures, cyclic architectures, generative adversarial networks, speaker adversarial training, and neural vocoders. Moreover, it is possible to automatically estimate objective measures such as mel-cepstrum distortion and pseudo mean opinion score based on MOSNet. In this paper, we describe representative functions developed in crank and make brief comparisons by objective evaluations.
The NU Voice Conversion System for the Voice Conversion Challenge 2020: On the Effectiveness of Sequence-to-sequence Models and Autoregressive Neural Vocoders
Oct 09, 2020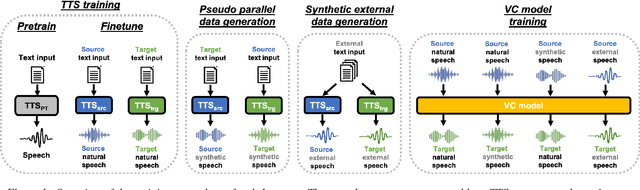

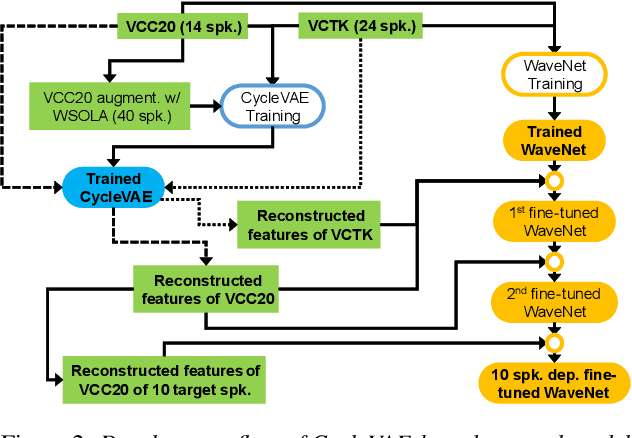
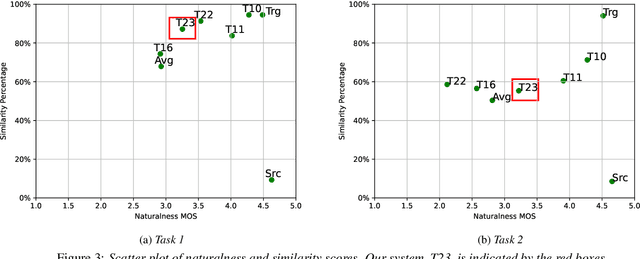
In this paper, we present the voice conversion (VC) systems developed at Nagoya University (NU) for the Voice Conversion Challenge 2020 (VCC2020). We aim to determine the effectiveness of two recent significant technologies in VC: sequence-to-sequence (seq2seq) models and autoregressive (AR) neural vocoders. Two respective systems were developed for the two tasks in the challenge: for task 1, we adopted the Voice Transformer Network, a Transformer-based seq2seq VC model, and extended it with synthetic parallel data to tackle nonparallel data; for task 2, we used the frame-based cyclic variational autoencoder (CycleVAE) to model the spectral features of a speech waveform and the AR WaveNet vocoder with additional fine-tuning. By comparing with the baseline systems, we confirmed that the seq2seq modeling can improve the conversion similarity and that the use of AR vocoders can improve the naturalness of the converted speech.
Non-Parallel Voice Conversion with Cyclic Variational Autoencoder
Jul 24, 2019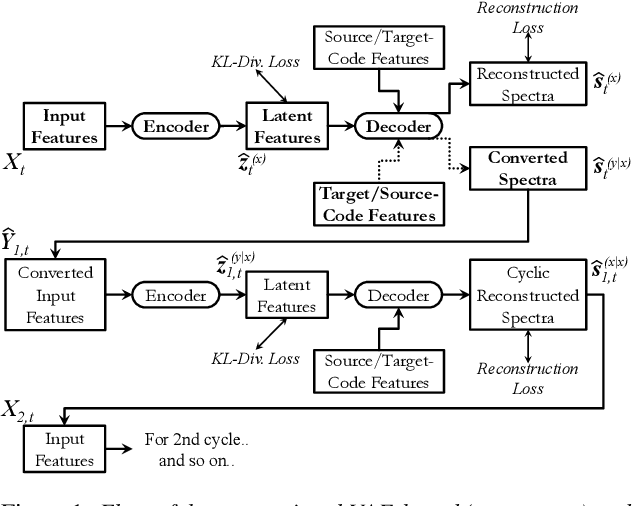
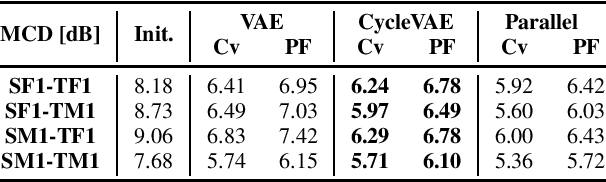

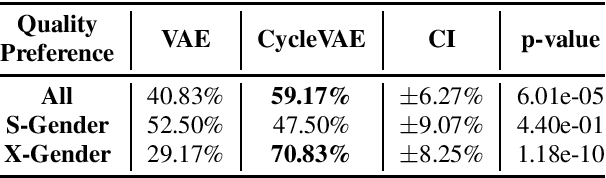
In this paper, we present a novel technique for a non-parallel voice conversion (VC) with the use of cyclic variational autoencoder (CycleVAE)-based spectral modeling. In a variational autoencoder(VAE) framework, a latent space, usually with a Gaussian prior, is used to encode a set of input features. In a VAE-based VC, the encoded latent features are fed into a decoder, along with speaker-coding features, to generate estimated spectra with either the original speaker identity (reconstructed) or another speaker identity (converted). Due to the non-parallel modeling condition, the converted spectra can not be directly optimized, which heavily degrades the performance of a VAE-based VC. In this work, to overcome this problem, we propose to use CycleVAE-based spectral model that indirectly optimizes the conversion flow by recycling the converted features back into the system to obtain corresponding cyclic reconstructed spectra that can be directly optimized. The cyclic flow can be continued by using the cyclic reconstructed features as input for the next cycle. The experimental results demonstrate the effectiveness of the proposed CycleVAE-based VC, which yields higher accuracy of converted spectra, generates latent features with higher correlation degree, and significantly improves the quality and conversion accuracy of the converted speech.
Refined WaveNet Vocoder for Variational Autoencoder Based Voice Conversion
Nov 27, 2018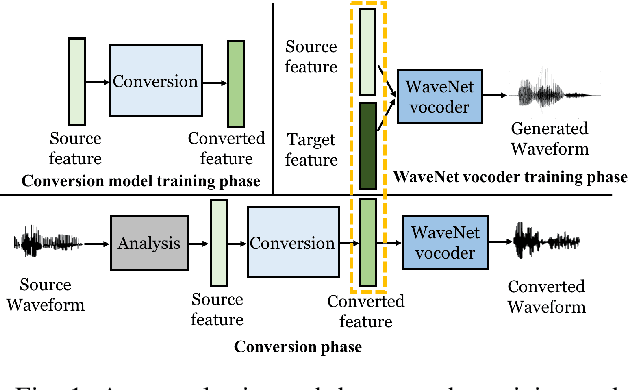
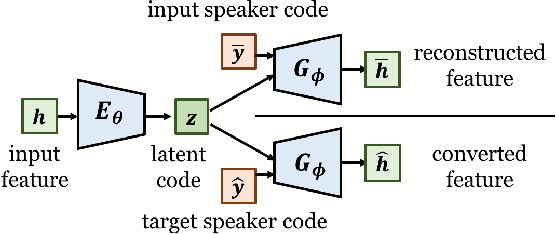
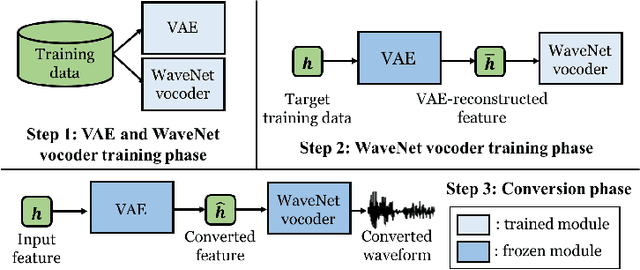
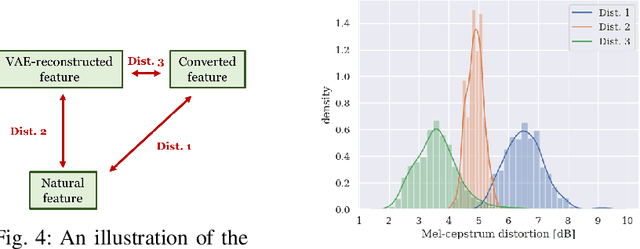
This paper presents a refinement framework of WaveNet vocoders for variational autoencoder (VAE) based voice conversion (VC), which reduces the quality distortion caused by the mismatch between the training data and testing data. Conventional WaveNet vocoders are trained with natural acoustic features but condition on the converted features in the conversion stage for VC, and such mismatch often causes significant quality and similarity degradation. In this work, we take advantage of the particular structure of VAEs to refine WaveNet vocoders with the self-reconstructed features generated by VAE, which are of similar characteristics with the converted features while having the same data length with the target training data. In other words, our proposed method does not require any alignment. Objective and subjective experimental results demonstrate the effectiveness of our proposed framework.