 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Driven Representational Geometry Modularization Predicts Brain Alignment in Language Models
Feb 07, 2026How large language models (LLMs) align with the neural representation and computation of human language is a central question in cognitive science. Using representational geometry as a mechanistic lens, we addressed this by tracking entropy, curvature, and fMRI encoding scores throughout Pythia (70M-1B) training. We identified a geometric modularization where layers self-organize into stable low- and high-complexity clusters. The low-complexity module, characterized by reduced entropy and curvature, consistently better predicted human language network activity. This alignment followed heterogeneous spatial-temporal trajectories: rapid and stable in temporal regions (AntTemp, PostTemp), but delayed and dynamic in frontal areas (IFG, IFGorb). Crucially, reduced curvature remained a robust predictor of model-brain alignment even after controlling for training progress, an effect that strengthened with model scale. These results links training-driven geometric reorganization to temporal-frontal functional specialization, suggesting that representational smoothing facilitates neural-like linguistic processing.
InteractEdit: Zero-Shot Editing of Human-Object Interactions in Images
Mar 12, 2025

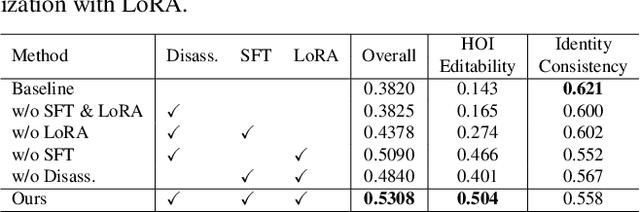

This paper presents InteractEdit, a novel framework for zero-shot Human-Object Interaction (HOI) editing, addressing the challenging task of transforming an existing interaction in an image into a new, desired interaction while preserving the identities of the subject and object. Unlike simpler image editing scenarios such as attribute manipulation, object replacement or style transfer, HOI editing involves complex spatial, contextual, and relational dependencies inherent in humans-objects interactions. Existing methods often overfit to the source image structure, limiting their ability to adapt to the substantial structural modifications demanded by new interactions. To address this, InteractEdit decomposes each scene into subject, object, and background components, then employs Low-Rank Adaptation (LoRA) and selective fine-tuning to preserve pretrained interaction priors while learning the visual identity of the source image. This regularization strategy effectively balances interaction edits with identity consistency. We further introduce IEBench, the most comprehensive benchmark for HOI editing, which evaluates both interaction editing and identity preservation. Our extensive experiments show that InteractEdit significantly outperforms existing methods, establishing a strong baseline for future HOI editing research and unlocking new possibilities for creative and practical applications. Code will be released upon publication.
An Evaluation of Three-Stage Voice Conversion Framework for Noisy and Reverberant Conditions
Jun 30, 2022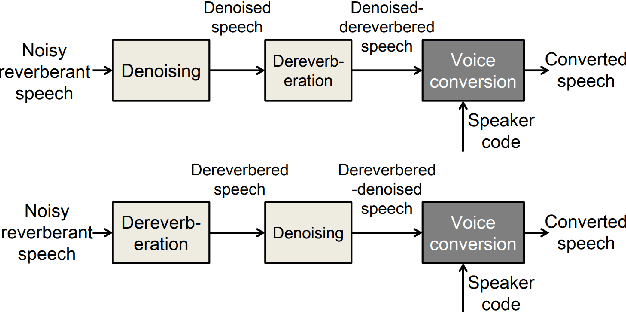
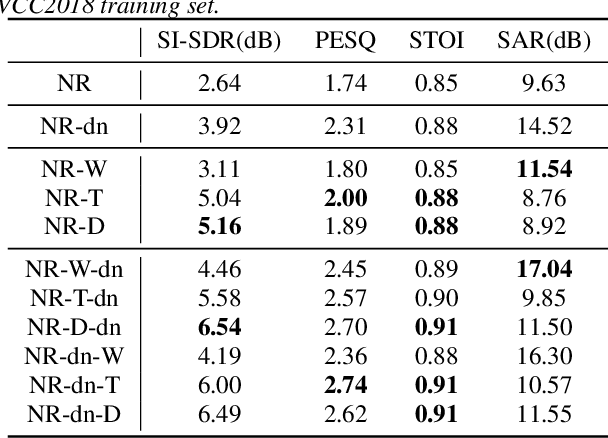
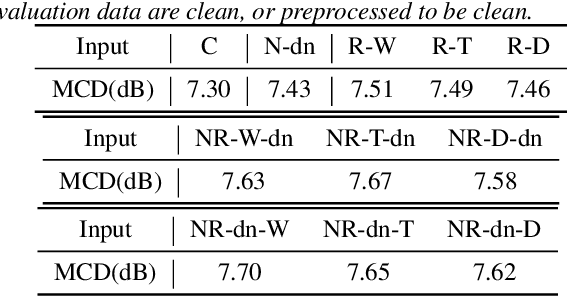
This paper presents a new voice conversion (VC) framework capable of dealing with both additive noise and reverberation, and its performance evaluation. There have been studied some VC researches focusing on real-world circumstances where speech data are interfered with background noise and reverberation. To deal with more practical conditions where no clean target dataset is available, one possible approach is zero-shot VC, but its performance tends to degrade compared with VC using sufficient amount of target speech data. To leverage large amount of noisy-reverberant target speech data, we propose a three-stage VC framework based on denoising process using a pretrained denoising model, dereverberation process using a dereverberation model, and VC process using a nonparallel VC model based on a variational autoencoder. The experimental results show that 1) noise and reverberation additively cause significant VC performance degradation, 2) the proposed method alleviates the adverse effects caused by both noise and reverberation, and significantly outperforms the baseline directly trained on the noisy-reverberant speech data, and 3) the potential degradation introduced by the denoising and dereverberation still causes noticeable adverse effects on VC performance.
Direct Noisy Speech Modeling for Noisy-to-Noisy Voice Conversion
Nov 13, 2021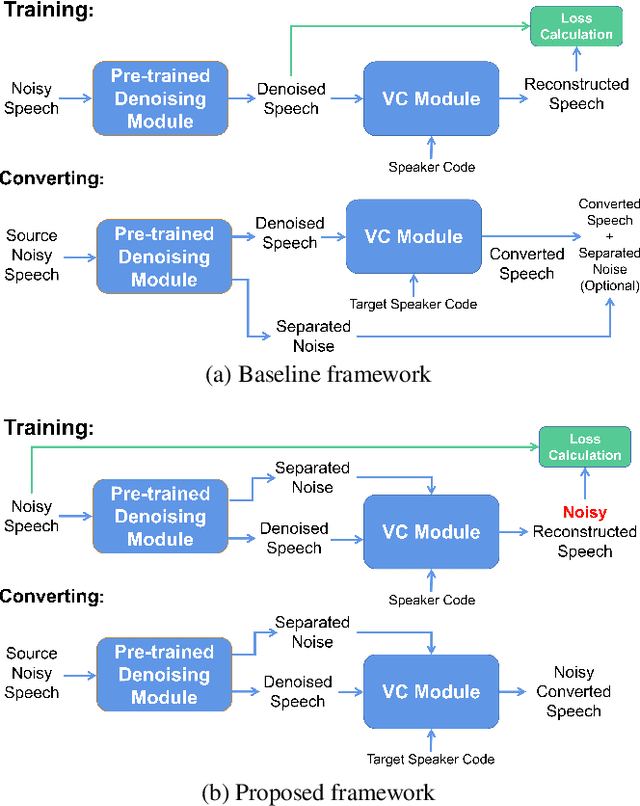
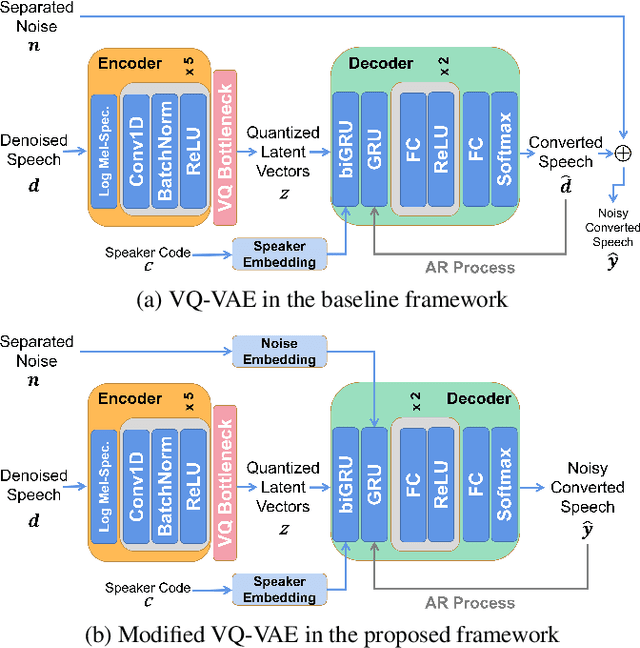
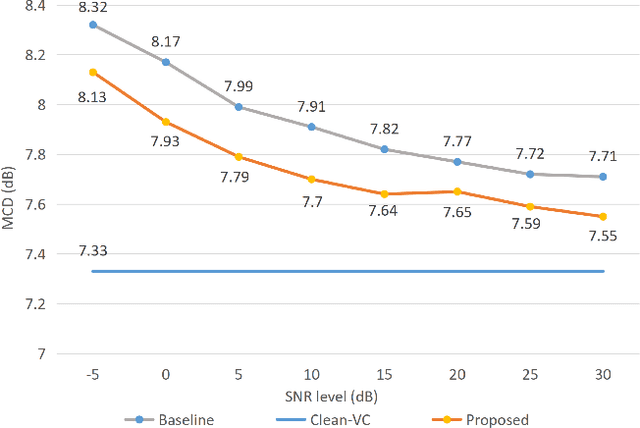
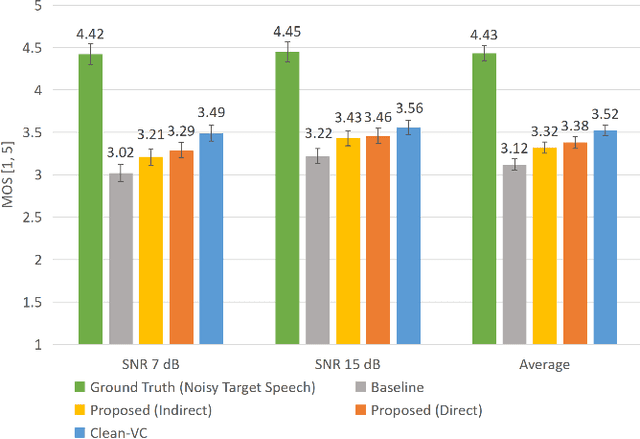
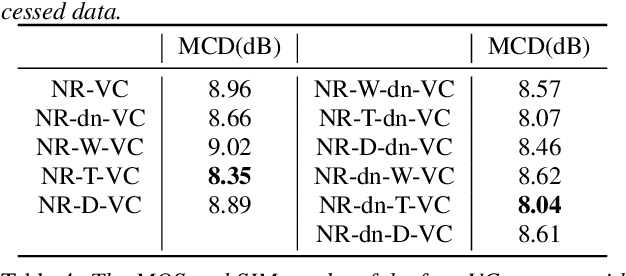
Beyond the conventional voice conversion (VC) where the speaker information is converted without altering the linguistic content, the background sounds are informative and need to be retained in some real-world scenarios, such as VC in movie/video and VC in music where the voice is entangled with background sounds. As a new VC framework, we have developed a noisy-to-noisy (N2N) VC framework to convert the speaker's identity while preserving the background sounds. Although our framework consisting of a denoising module and a VC module well handles the background sounds, the VC module is sensitive to the distortion caused by the denoising module. To address this distortion issue, in this paper we propose the improved VC module to directly model the noisy speech waveform while controlling the background sounds. The experimental results have demonstrated that our improved framework significantly outperforms the previous one and achieves an acceptable score in terms of naturalness, while reaching comparable similarity performance to the upper bound of our framework.
Noisy-to-Noisy Voice Conversion Framework with Denoising Model
Sep 22, 2021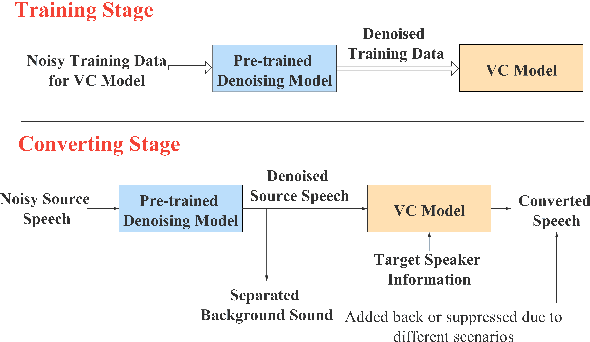
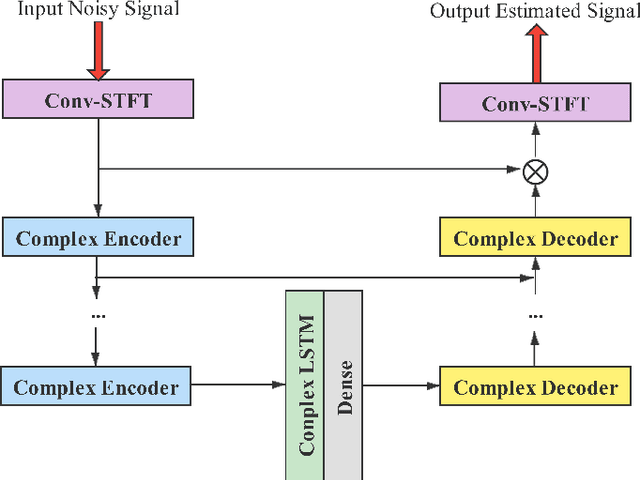
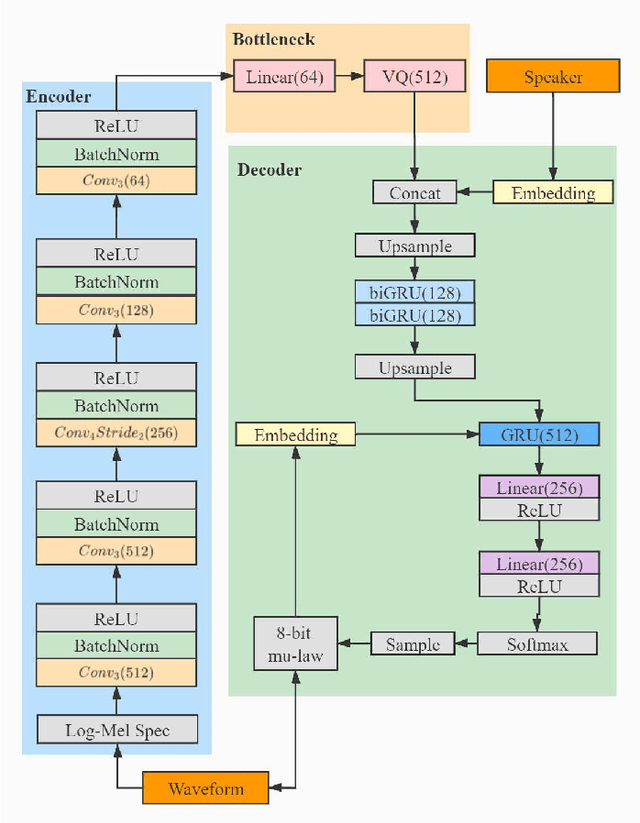
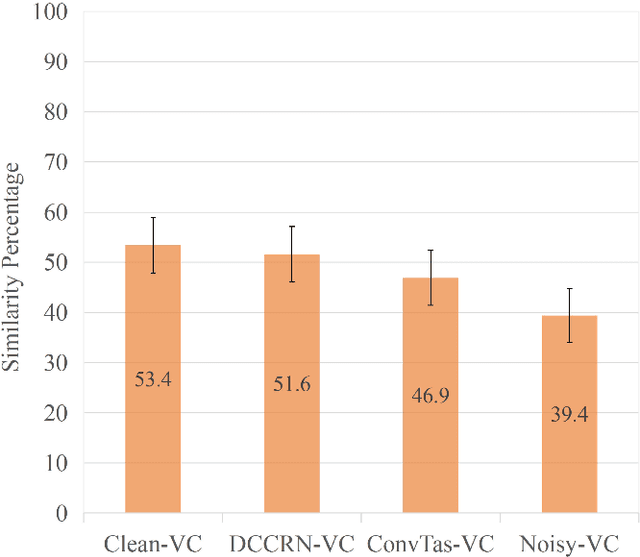
In a conventional voice conversion (VC) framework, a VC model is often trained with a clean dataset consisting of speech data carefully recorded and selected by minimizing background interference. However, collecting such a high-quality dataset is expensive and time-consuming. Leveraging crowd-sourced speech data in training is more economical. Moreover, for some real-world VC scenarios such as VC in video and VC-based data augmentation for speech recognition systems, the background sounds themselves are also informative and need to be maintained. In this paper, to explore VC with the flexibility of handling background sounds, we propose a noisy-to-noisy (N2N) VC framework composed of a denoising module and a VC module. With the proposed framework, we can convert the speaker's identity while preserving the background sounds. Both objective and subjective evaluations are conducted, and the results reveal the effectiveness of the proposed framework.