 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evaluation of Three-Stage Voice Conversion Framework for Noisy and Reverberant Conditions
Paper and Code
Jun 30, 2022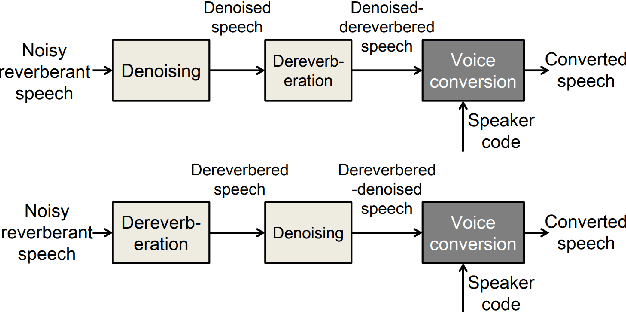
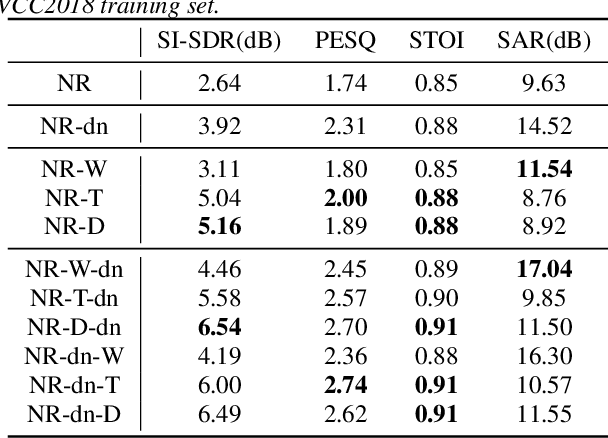
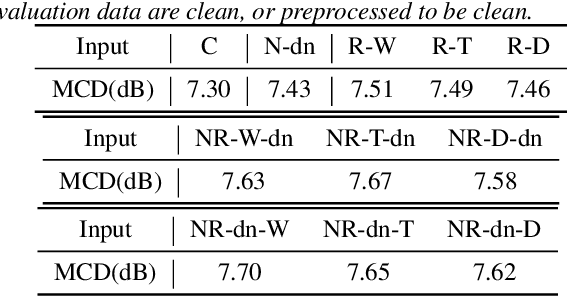
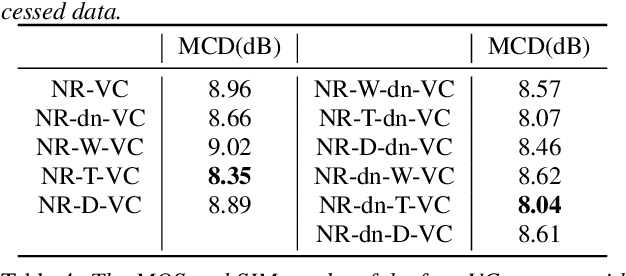
This paper presents a new voice conversion (VC) framework capable of dealing with both additive noise and reverberation, and its performance evaluation. There have been studied some VC researches focusing on real-world circumstances where speech data are interfered with background noise and reverberation. To deal with more practical conditions where no clean target dataset is available, one possible approach is zero-shot VC, but its performance tends to degrade compared with VC using sufficient amount of target speech data. To leverage large amount of noisy-reverberant target speech data, we propose a three-stage VC framework based on denoising process using a pretrained denoising model, dereverberation process using a dereverberation model, and VC process using a nonparallel VC model based on a variational autoencoder. The experimental results show that 1) noise and reverberation additively cause significant VC performance degradation, 2) the proposed method alleviates the adverse effects caused by both noise and reverberation, and significantly outperforms the baseline directly trained on the noisy-reverberant speech data, and 3) the potential degradation introduced by the denoising and dereverberation still causes noticeable adverse effects on VC performance.