 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy-to-Noisy Voice Conversion Framework with Denoising Model
Paper and Code
Sep 22, 2021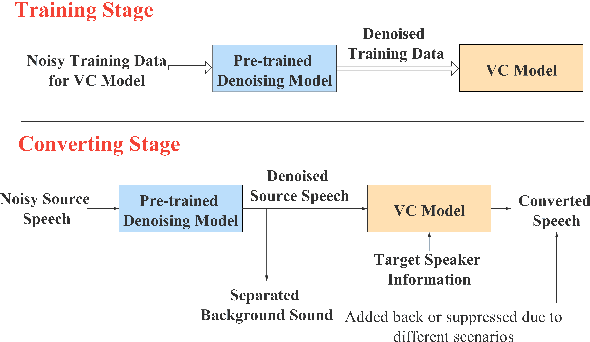
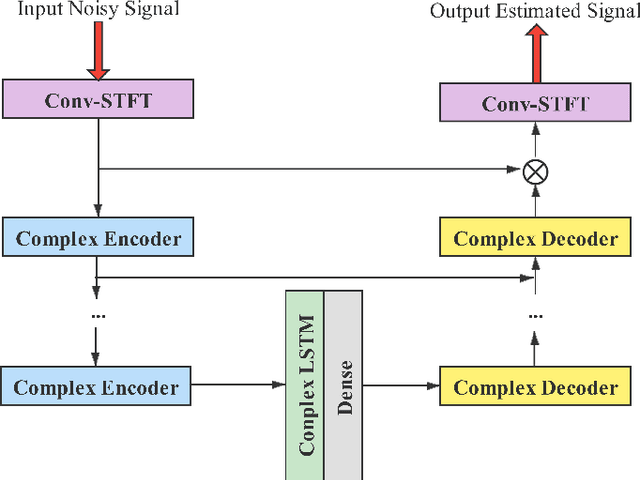
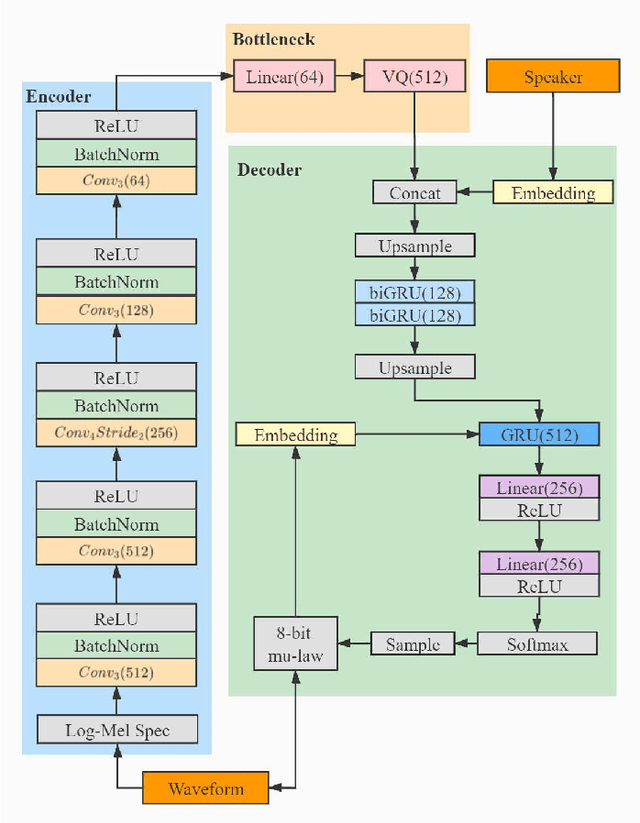
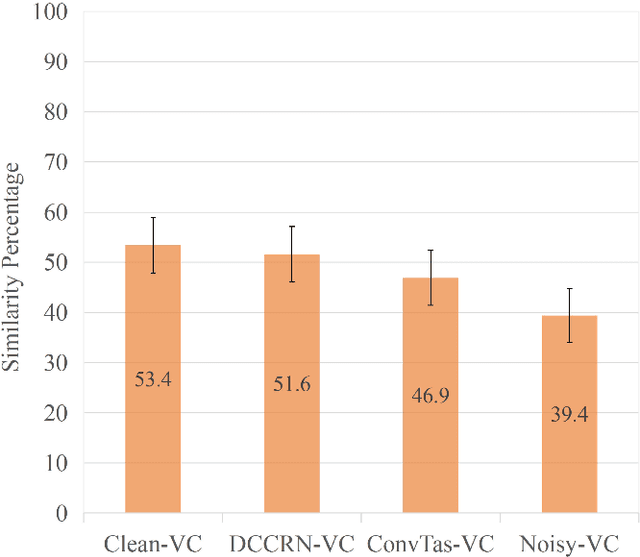
In a conventional voice conversion (VC) framework, a VC model is often trained with a clean dataset consisting of speech data carefully recorded and selected by minimizing background interference. However, collecting such a high-quality dataset is expensive and time-consuming. Leveraging crowd-sourced speech data in training is more economical. Moreover, for some real-world VC scenarios such as VC in video and VC-based data augmentation for speech recognition systems, the background sounds themselves are also informative and need to be maintained. In this paper, to explore VC with the flexibility of handling background sounds, we propose a noisy-to-noisy (N2N) VC framework composed of a denoising module and a VC module. With the proposed framework, we can convert the speaker's identity while preserving the background sounds. Both objective and subjective evaluations are conducted, and the results reveal the effectiveness of the proposed framework.