 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Plane: Audio Factorization Plane Gaussian Splatting for Real-Time Talking Head Synthesis
Mar 28, 2025Talking head synthesis has become a key research area in computer graphics and multimedia, yet most existing methods often struggle to balance generation quality with computational efficiency. In this paper, we present a novel approach that leverages an Audio Factorization Plane (Audio-Plane) based Gaussian Splatting for high-quality and real-time talking head generation. For modeling a dynamic talking head, 4D volume representation is needed. However, directly storing a dense 4D grid is impractical due to the high cost and lack of scalability for longer durations. We overcome this challenge with the proposed Audio-Plane, where the 4D volume representation is decomposed into audio-independent space planes and audio-dependent planes. This provides a compact and interpretable feature representation for talking head, facilitating more precise audio-aware spatial encoding and enhanced audio-driven lip dynamic modeling. To further improve speech dynamics, we develop a dynamic splatting method that helps the network more effectively focus on modeling the dynamics of the mouth region. Extensive experiments demonstrate that by integrating these innovations with the powerful Gaussian Splatting, our method is capable of synthesizing highly realistic talking videos in real time while ensuring precise audio-lip synchronization. Synthesized results are available in https://sstzal.github.io/Audio-Plane/.
InteractEdit: Zero-Shot Editing of Human-Object Interactions in Images
Mar 12, 2025

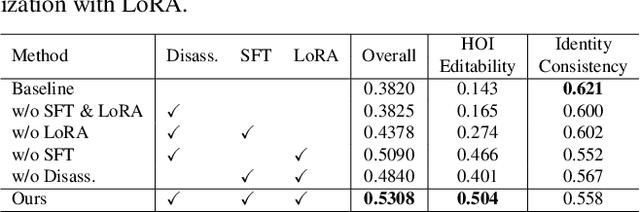

This paper presents InteractEdit, a novel framework for zero-shot Human-Object Interaction (HOI) editing, addressing the challenging task of transforming an existing interaction in an image into a new, desired interaction while preserving the identities of the subject and object. Unlike simpler image editing scenarios such as attribute manipulation, object replacement or style transfer, HOI editing involves complex spatial, contextual, and relational dependencies inherent in humans-objects interactions. Existing methods often overfit to the source image structure, limiting their ability to adapt to the substantial structural modifications demanded by new interactions. To address this, InteractEdit decomposes each scene into subject, object, and background components, then employs Low-Rank Adaptation (LoRA) and selective fine-tuning to preserve pretrained interaction priors while learning the visual identity of the source image. This regularization strategy effectively balances interaction edits with identity consistency. We further introduce IEBench, the most comprehensive benchmark for HOI editing, which evaluates both interaction editing and identity preservation. Our extensive experiments show that InteractEdit significantly outperforms existing methods, establishing a strong baseline for future HOI editing research and unlocking new possibilities for creative and practical applications. Code will be released upon publication.
Dynamic Modality-Camera Invariant Clustering for Unsupervised Visible-Infrared Person Re-identification
Dec 11, 2024Unsupervised learning visible-infrared person re-identification (USL-VI-ReID) offers a more flexible and cost-effective alternative compared to supervised methods. This field has gained increasing attention due to its promising potential. Existing methods simply cluster modality-specific samples and employ strong association techniques to achieve instance-to-cluster or cluster-to-cluster cross-modality associations. However, they ignore cross-camera differences, leading to noticeable issues with excessive splitting of identities. Consequently, this undermines the accuracy and reliability of cross-modal associations. To address these issues, we propose a novel Dynamic Modality-Camera Invariant Clustering (DMIC) framework for USL-VI-ReID. Specifically, our DMIC naturally integrates Modality-Camera Invariant Expansion (MIE), Dynamic Neighborhood Clustering (DNC) and Hybrid Modality Contrastive Learning (HMCL) into a unified framework, which eliminates both the cross-modality and cross-camera discrepancies in clustering. MIE fuses inter-modal and inter-camera distance coding to bridge the gaps between modalities and cameras at the clustering level. DNC employs two dynamic search strategies to refine the network's optimization objective, transitioning from improving discriminability to enhancing cross-modal and cross-camera generalizability. Moreover, HMCL is designed to optimize instance-level and cluster-level distributions. Memories for intra-modality and inter-modality training are updated using randomly selected samples, facilitating real-time exploration of modality-invariant representations. Extensive experiments have demonstrated that our DMIC addresses the limitations present in current clustering approaches and achieve competitive performance, which significantly reduces the performance gap with supervised methods.
InteractDiffusion: Interaction Control in Text-to-Image Diffusion Models
Dec 10, 2023



Large-scale text-to-image (T2I) diffusion models have showcased incredible capabilities in generating coherent images based on textual descriptions, enabling vast applications in content generation. While recent advancements have introduced control over factors such as object localization, posture, and image contours, a crucial gap remains in our ability to control the interactions between objects in the generated content. Well-controlling interactions in generated images could yield meaningful applications, such as creating realistic scenes with interacting characters. In this work, we study the problems of conditioning T2I diffusion models with Human-Object Interaction (HOI) information, consisting of a triplet label (person, action, object) and corresponding bounding boxes. We propose a pluggable interaction control model, called InteractDiffusion that extends existing pre-trained T2I diffusion models to enable them being better conditioned on interactions. Specifically, we tokenize the HOI information and learn their relationships via interaction embeddings. A conditioning self-attention layer is trained to map HOI tokens to visual tokens, thereby conditioning the visual tokens better in existing T2I diffusion models. Our model attains the ability to control the interaction and location on existing T2I diffusion models, which outperforms existing baselines by a large margin in HOI detection score, as well as fidelity in FID and KID. Project page: https://jiuntian.github.io/interactdiffusion.