 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAST-BAR: Knowledge-Anchored Semantically-Dynamic Topology Brain Autoregressive Modeling for Universal Neural Interpretation
May 13, 2026While EEG foundation models have shown significant potential in universal neural decoding across tasks, their advancement remains constrained by the inadequacy modeling of complex spatiotemporal topology, as well as the inherent modality gap between low-level physiological signals and high-level textual semantics. To address these challenges, we propose a Knowledge-Anchored Semantically-Dynamic Topology Brain Autoregressive Model (KAST-BAR), which dynamically aligns physiological representations derived from multi-level brain topology with an expert-level semantic space. Specifically, we design a Dual-Stream Hierarchical Attention (DSHA) encoder that accurately captures the brain's intrinsic non-Euclidean topology by modeling local temporal dynamics with global spatial contexts. On this basis, a Knowledge-Anchored Semantic Profiler (KASP) is proposed to synthesize physically-grounded and instance-level textual profiles, which subsequently drive a Semantic Text-Aware Refiner (STAR) to dynamically reconstruct EEG representations using Latent Expert Queries. By conducting large-scale pre-training on 21 diverse datasets to build a foundation model, KAST-BAR effectively integrates expert-level medical knowledge into EEG signal representations, consistently achieving superior performance across six downstream tasks. Our code is available at https://github.com/KAST-BAR/KAST-BAR
Audio-Plane: Audio Factorization Plane Gaussian Splatting for Real-Time Talking Head Synthesis
Mar 28, 2025Talking head synthesis has become a key research area in computer graphics and multimedia, yet most existing methods often struggle to balance generation quality with computational efficiency. In this paper, we present a novel approach that leverages an Audio Factorization Plane (Audio-Plane) based Gaussian Splatting for high-quality and real-time talking head generation. For modeling a dynamic talking head, 4D volume representation is needed. However, directly storing a dense 4D grid is impractical due to the high cost and lack of scalability for longer durations. We overcome this challenge with the proposed Audio-Plane, where the 4D volume representation is decomposed into audio-independent space planes and audio-dependent planes. This provides a compact and interpretable feature representation for talking head, facilitating more precise audio-aware spatial encoding and enhanced audio-driven lip dynamic modeling. To further improve speech dynamics, we develop a dynamic splatting method that helps the network more effectively focus on modeling the dynamics of the mouth region. Extensive experiments demonstrate that by integrating these innovations with the powerful Gaussian Splatting, our method is capable of synthesizing highly realistic talking videos in real time while ensuring precise audio-lip synchronization. Synthesized results are available in https://sstzal.github.io/Audio-Plane/.
DiffTalk: Crafting Diffusion Models for Generalized Talking Head Synthesis
Jan 10, 2023Talking head synthesis is a promising approach for the video production industry. Recently, a lot of effort has been devoted in this research area to improve the generation quality or enhance the model generalization. However, there are few works able to address both issues simultaneously, which is essential for practical applications. To this end, in this paper, we turn attention to the emerging powerful Latent Diffusion Models, and model the Talking head generation as an audio-driven temporally coherent denoising process (DiffTalk). More specifically, instead of employing audio signals as the single driving factor, we investigate the control mechanism of the talking face, and incorporate reference face images and landmarks as conditions for personality-aware generalized synthesis. In this way, the proposed DiffTalk is capable of producing high-quality talking head videos in synchronization with the source audio, and more importantly, it can be naturally generalized across different identities without any further fine-tuning. Additionally, our DiffTalk can be gracefully tailored for higher-resolution synthesis with negligible extra computational cost. Extensive experiments show that the proposed DiffTalk efficiently synthesizes high-fidelity audio-driven talking head videos for generalized novel identities. For more video results, please refer to this demonstration \url{https://cloud.tsinghua.edu.cn/f/e13f5aad2f4c4f898ae7/}.
Learning Dynamic Facial Radiance Fields for Few-Shot Talking Head Synthesis
Jul 24, 2022

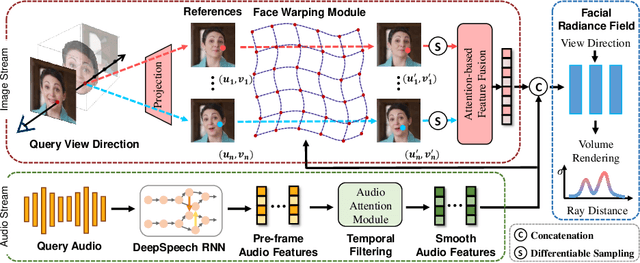
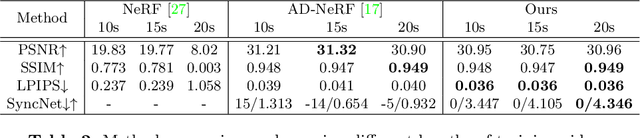
Talking head synthesis is an emerging technology with wide applications in film dubbing, virtual avatars and online education. Recent NeRF-based methods generate more natural talking videos, as they better capture the 3D structural information of faces. However, a specific model needs to be trained for each identity with a large dataset. In this paper, we propose Dynamic Facial Radiance Fields (DFRF) for few-shot talking head synthesis, which can rapidly generalize to an unseen identity with few training data. Different from the existing NeRF-based methods which directly encode the 3D geometry and appearance of a specific person into the network, our DFRF conditions face radiance field on 2D appearance images to learn the face prior. Thus the facial radiance field can be flexibly adjusted to the new identity with few reference images. Additionally, for better modeling of the facial deformations, we propose a differentiable face warping module conditioned on audio signals to deform all reference images to the query space. Extensive experiments show that with only tens of seconds of training clip available, our proposed DFRF can synthesize natural and high-quality audio-driven talking head videos for novel identities with only 40k iterations. We highly recommend readers view our supplementary video for intuitive comparisons. Code is available in https://sstzal.github.io/DFRF/.
Structure-Aware Face Clustering on a Large-Scale Graph with $\bf{10^{7}}$ Nodes
Mar 27, 2021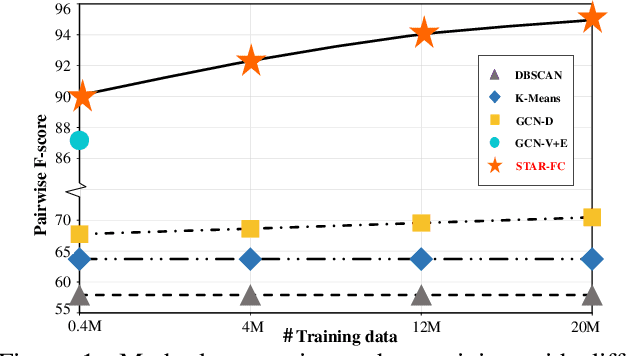
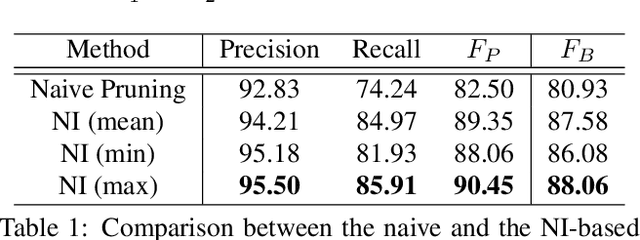
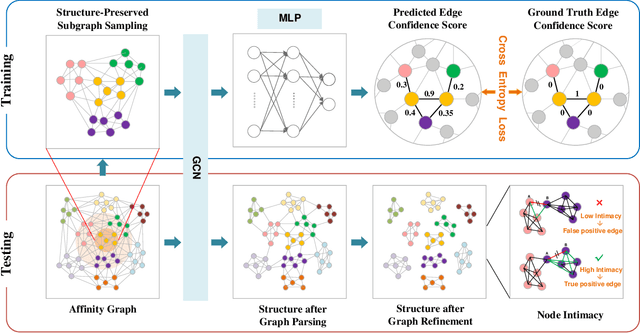

Face clustering is a promising method for annotating unlabeled face images. Recent supervised approaches have boosted the face clustering accuracy greatly, however their performance is still far from satisfactory. These methods can be roughly divided into global-based and local-based ones. Global-based methods suffer from the limitation of training data scale, while local-based ones are difficult to grasp the whole graph structure information and usually take a long time for inference. Previous approaches fail to tackle these two challenges simultaneously. To address the dilemma of large-scale training and efficient inference, we propose the STructure-AwaRe Face Clustering (STAR-FC) method. Specifically, we design a structure-preserved subgraph sampling strategy to explore the power of large-scale training data, which can increase the training data scale from ${10^{5}}$ to ${10^{7}}$. During inference, the STAR-FC performs efficient full-graph clustering with two steps: graph parsing and graph refinement. And the concept of node intimacy is introduced in the second step to mine the local structural information. The STAR-FC gets 91.97 pairwise F-score on partial MS1M within 310s which surpasses the state-of-the-arts. Furthermore, we are the first to train on very large-scale graph with 20M nodes, and achieve superior inference results on 12M testing data. Overall, as a simple and effective method, the proposed STAR-FC provides a strong baseline for large-scale face clustering. Code is available at \url{https://sstzal.github.io/STAR-FC/}.