 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneration of Speaker Representations Using Heterogeneous Training Batch Assembly
Mar 30, 2022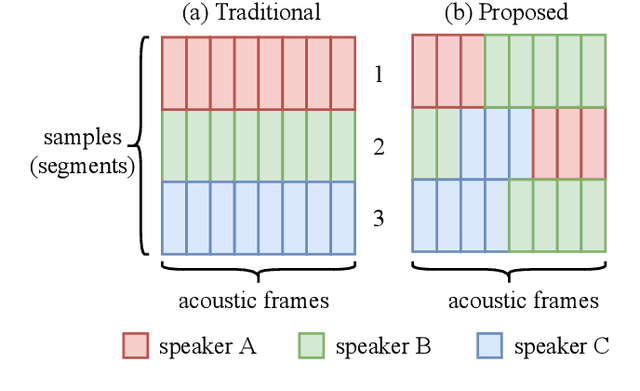
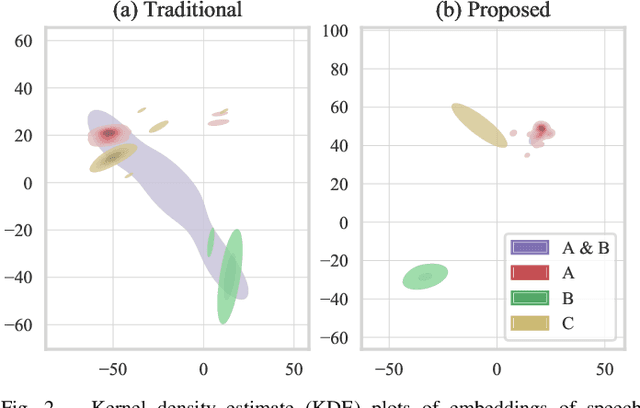
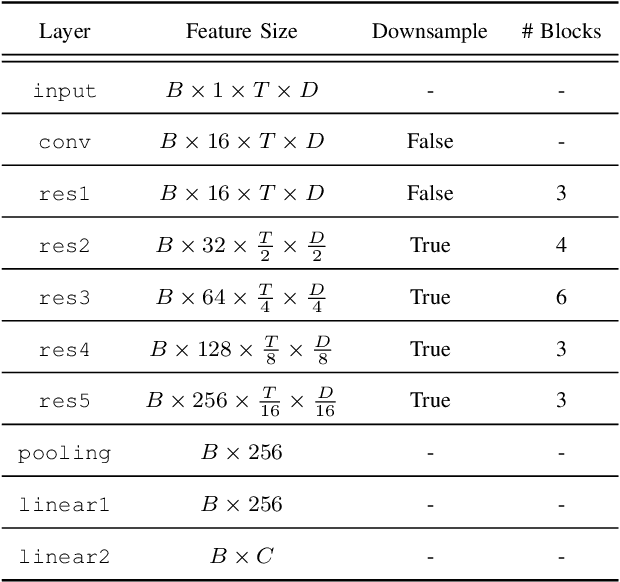
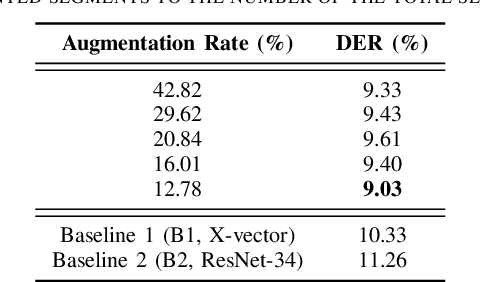
In traditional speaker diarization systems, a well-trained speaker model is a key component to extract representations from consecutive and partially overlapping segments in a long speech session. To be more consistent with the back-end segmentation and clustering, we propose a new CNN-based speaker modeling scheme, which takes into account the heterogeneity of the speakers in each training segment and batch. We randomly and synthetically augment the training data into a set of segments, each of which contains more than one speaker and some overlapping parts. A soft label is imposed on each segment based on its speaker occupation ratio, and the standard cross entropy loss is implemented in model training. In this way, the speaker model should have the ability to generate a geometrically meaningful embedding for each multi-speaker segment. Experimental results show that our system is superior to the baseline system using x-vectors in two speaker diarization tasks. In the CALLHOME task trained on the NIST SRE and Switchboard datasets, our system achieves a relative reduction of 12.93% in DER. In Track 2 of CHiME-6, our system provides 13.24%, 12.60%, and 5.65% relative reductions in DER, JER, and WER, respectively.
Chain-based Discriminative Autoencoders for Speech Recognition
Mar 28, 2022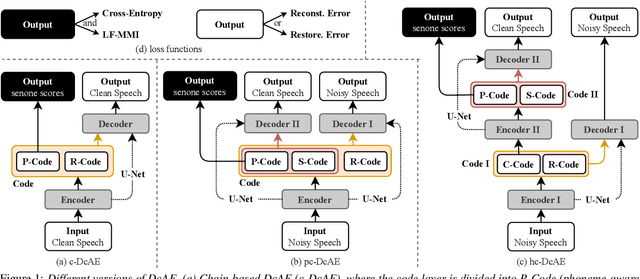
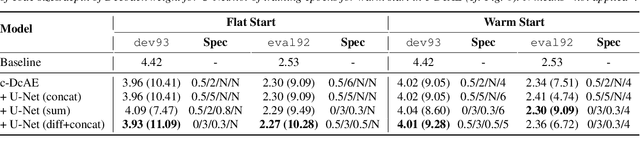
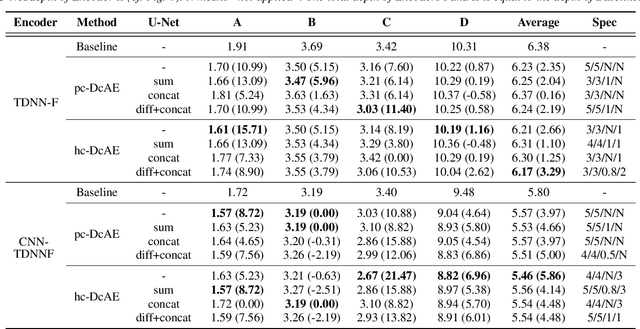
In our previous work, we proposed a discriminative autoencoder (DcAE) for speech recognition. DcAE combines two training schemes into one. First, since DcAE aims to learn encoder-decoder mappings, the squared error between the reconstructed speech and the input speech is minimized. Second, in the code layer, frame-based phonetic embeddings are obtained by minimizing the categorical cross-entropy between ground truth labels and predicted triphone-state scores. DcAE is developed based on the Kaldi toolkit by treating various TDNN models as encoders. In this paper, we further propose three new versions of DcAE. First, a new objective function that considers both categorical cross-entropy and mutual information between ground truth and predicted triphone-state sequences is used. The resulting DcAE is called a chain-based DcAE (c-DcAE). For application to robust speech recognition, we further extend c-DcAE to hierarchical and parallel structures, resulting in hc-DcAE and pc-DcAE. In these two models, both the error between the reconstructed noisy speech and the input noisy speech and the error between the enhanced speech and the reference clean speech are taken into the objective function. Experimental results on the WSJ and Aurora-4 corpora show that our DcAE models outperform baseline systems.