 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference-based training framework for automatic speech quality assessment using deep neural network
Aug 29, 2023One objective of Speech Quality Assessment (SQA) is to estimate the ranks of synthetic speech systems. However, recent SQA models are typically trained using low-precision direct scores such as mean opinion scores (MOS) as the training objective, which is not straightforward to estimate ranking. Although it is effective for predicting quality scores of individual sentences, this approach does not account for speech and system preferences when ranking multiple systems. We propose a training framework of SQA models that can be trained with only preference scores derived from pairs of MOS to improve ranking prediction. Our experiment reveals conditions where our framework works the best in terms of pair generation, aggregation functions to derive system score from utterance preferences, and threshold functions to determine preference from a pair of MOS. Our results demonstrate that our proposed method significantly outperforms the baseline model in Spearman's Rank Correlation Coefficient.
NASTAR: Noise Adaptive Speech Enhancement with Target-Conditional Resampling
Jun 18, 2022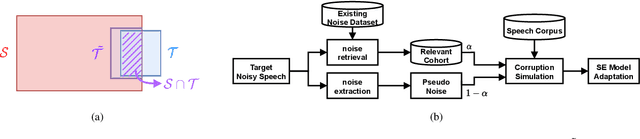
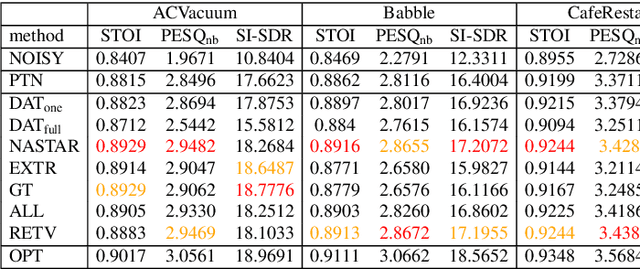
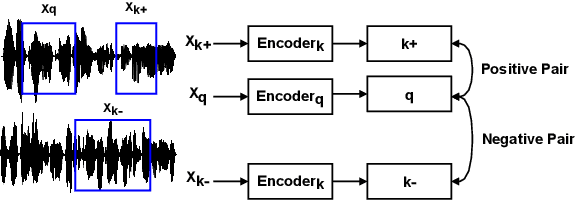
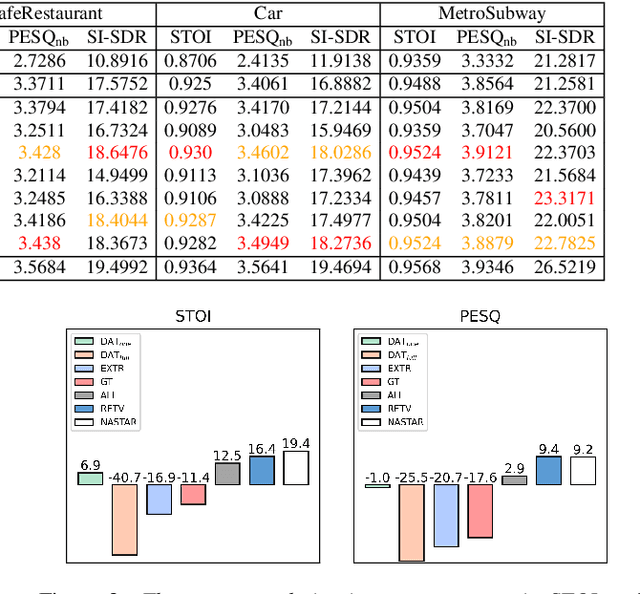
For deep learning-based speech enhancement (SE) systems, the training-test acoustic mismatch can cause notable performance degradation. To address the mismatch issue, numerous noise adaptation strategies have been derived. In this paper, we propose a novel method, called noise adaptive speech enhancement with target-conditional resampling (NASTAR), which reduces mismatches with only one sample (one-shot) of noisy speech in the target environment. NASTAR uses a feedback mechanism to simulate adaptive training data via a noise extractor and a retrieval model. The noise extractor estimates the target noise from the noisy speech, called pseudo-noise. The noise retrieval model retrieves relevant noise samples from a pool of noise signals according to the noisy speech, called relevant-cohort. The pseudo-noise and the relevant-cohort set are jointly sampled and mixed with the source speech corpus to prepare simulated training data for noise adaptation. Experimental results show that NASTAR can effectively use one noisy speech sample to adapt an SE model to a target condition. Moreover, both the noise extractor and the noise retrieval model contribute to model adaptation. To our best knowledge, NASTAR is the first work to perform one-shot noise adaptation through noise extraction and retrieval.
SVSNet: An End-to-end Speaker Voice Similarity Assessment Model
Jul 20, 2021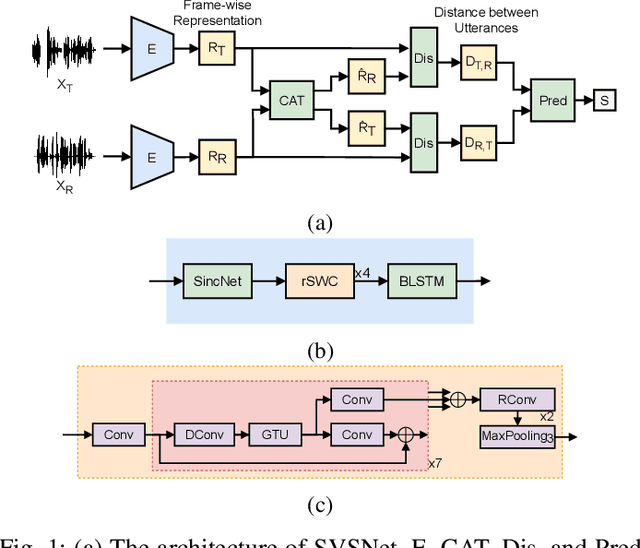



Neural evaluation metrics derived for numerous speech generation tasks have recently attracted great attention. In this paper, we propose SVSNet, the first end-to-end neural network model to assess the speaker voice similarity between natural speech and synthesized speech. Unlike most neural evaluation metrics that use hand-crafted features, SVSNet directly takes the raw waveform as input to more completely utilize speech information for prediction. SVSNet consists of encoder, co-attention, distance calculation, and prediction modules and is trained in an end-to-end manner. The experimental results on the Voice Conversion Challenge 2018 and 2020 (VCC2018 and VCC2020) datasets show that SVSNet notably outperforms well-known baseline systems in the assessment of speaker similarity at the utterance and system levels.
Relational Data Selection for Data Augmentation of Speaker-dependent Multi-band MelGAN Vocoder
Jun 10, 2021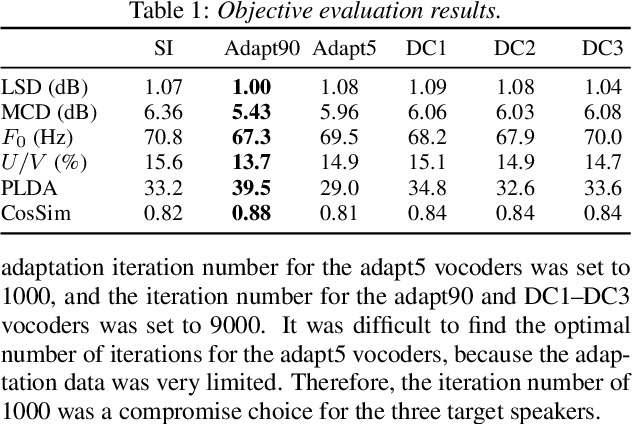
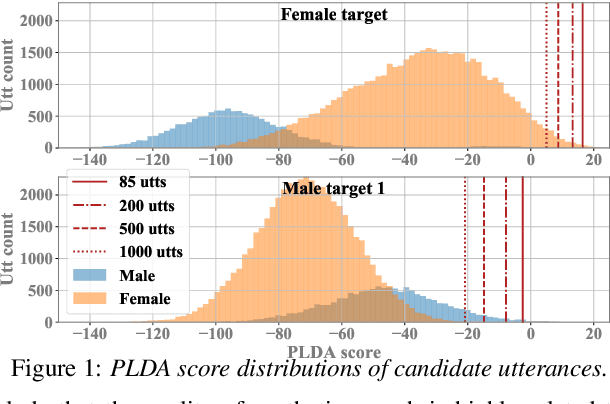
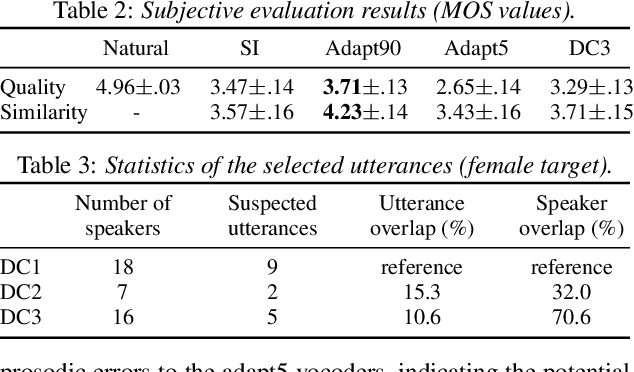
Nowadays, neural vocoders can generate very high-fidelity speech when a bunch of training data is available. Although a speaker-dependent (SD) vocoder usually outperforms a speaker-independent (SI) vocoder, it is impractical to collect a large amount of data of a specific target speaker for most real-world applications. To tackle the problem of limited target data, a data augmentation method based on speaker representation and similarity measurement of speaker verification is proposed in this paper. The proposed method selects utterances that have similar speaker identity to the target speaker from an external corpus, and then combines the selected utterances with the limited target data for SD vocoder adaptation. The evaluation results show that, compared with the vocoder adapted using only limited target data, the vocoder adapted using augmented data improves both the quality and similarity of synthesized speech.
The AS-NU System for the M2VoC Challenge
Apr 07, 2021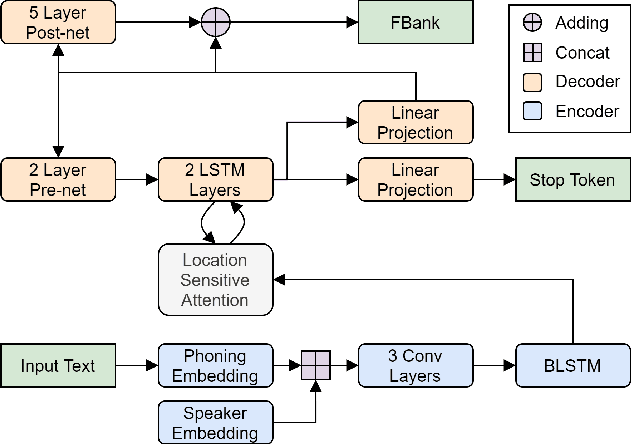
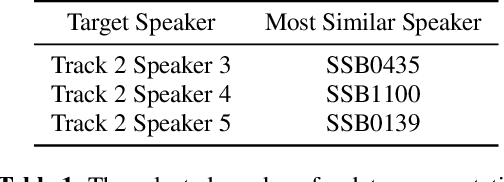
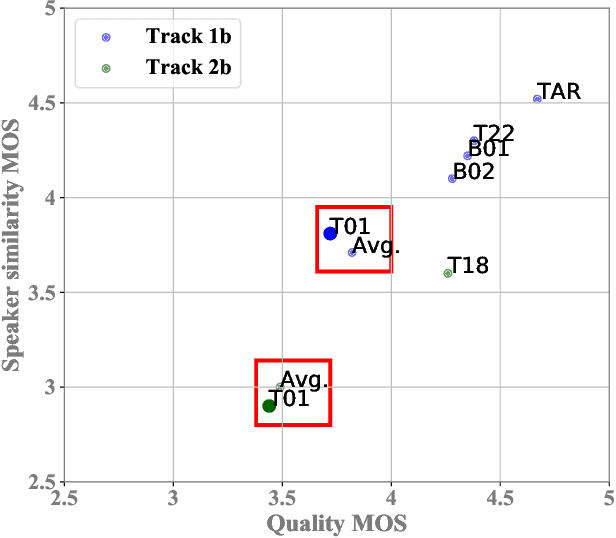
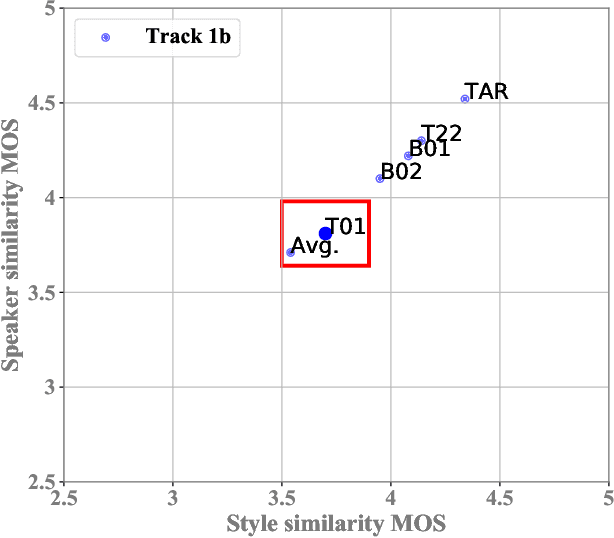
This paper describes the AS-NU systems for two tracks in MultiSpeaker Multi-Style Voice Cloning Challenge (M2VoC). The first track focuses on using a small number of 100 target utterances for voice cloning, while the second track focuses on using only 5 target utterances for voice cloning. Due to the serious lack of data in the second track, we selected the speaker most similar to the target speaker from the training data of the TTS system, and used the speaker's utterances and the given 5 target utterances to fine-tune our model. The evaluation results show that our systems on the two tracks perform similarly in terms of quality, but there is still a clear gap between the similarity score of the second track and the similarity score of the first track.