 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD4AM: A General Denoising Framework for Downstream Acoustic Models
Nov 28, 2023The performance of acoustic models degrades notably in noisy environments. Speech enhancement (SE) can be used as a front-end strategy to aid automatic speech recognition (ASR) systems. However, existing training objectives of SE methods are not fully effective at integrating speech-text and noisy-clean paired data for training toward unseen ASR systems. In this study, we propose a general denoising framework, D4AM, for various downstream acoustic models. Our framework fine-tunes the SE model with the backward gradient according to a specific acoustic model and the corresponding classification objective. In addition, our method aims to consider the regression objective as an auxiliary loss to make the SE model generalize to other unseen acoustic models. To jointly train an SE unit with regression and classification objectives, D4AM uses an adjustment scheme to directly estimate suitable weighting coefficients rather than undergoing a grid search process with additional training costs. The adjustment scheme consists of two parts: gradient calibration and regression objective weighting. The experimental results show that D4AM can consistently and effectively provide improvements to various unseen acoustic models and outperforms other combination setups. Specifically, when evaluated on the Google ASR API with real noisy data completely unseen during SE training, D4AM achieves a relative WER reduction of 24.65% compared with the direct feeding of noisy input. To our knowledge, this is the first work that deploys an effective combination scheme of regression (denoising) and classification (ASR) objectives to derive a general pre-processor applicable to various unseen ASR systems. Our code is available at https://github.com/ChangLee0903/D4AM.
LC4SV: A Denoising Framework Learning to Compensate for Unseen Speaker Verification Models
Nov 28, 2023The performance of speaker verification (SV) models may drop dramatically in noisy environments. A speech enhancement (SE) module can be used as a front-end strategy. However, existing SE methods may fail to bring performance improvements to downstream SV systems due to artifacts in the predicted signals of SE models. To compensate for artifacts, we propose a generic denoising framework named LC4SV, which can serve as a pre-processor for various unknown downstream SV models. In LC4SV, we employ a learning-based interpolation agent to automatically generate the appropriate coefficients between the enhanced signal and its noisy input to improve SV performance in noisy environments. Our experimental results demonstrate that LC4SV consistently improves the performance of various unseen SV systems. To the best of our knowledge, this work is the first attempt to develop a learning-based interpolation scheme aiming at improving SV performance in noisy environments.
NASTAR: Noise Adaptive Speech Enhancement with Target-Conditional Resampling
Jun 18, 2022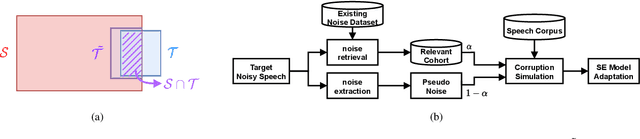
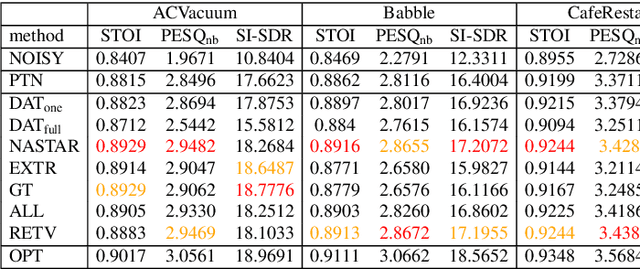
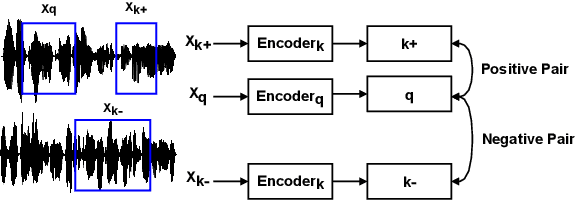
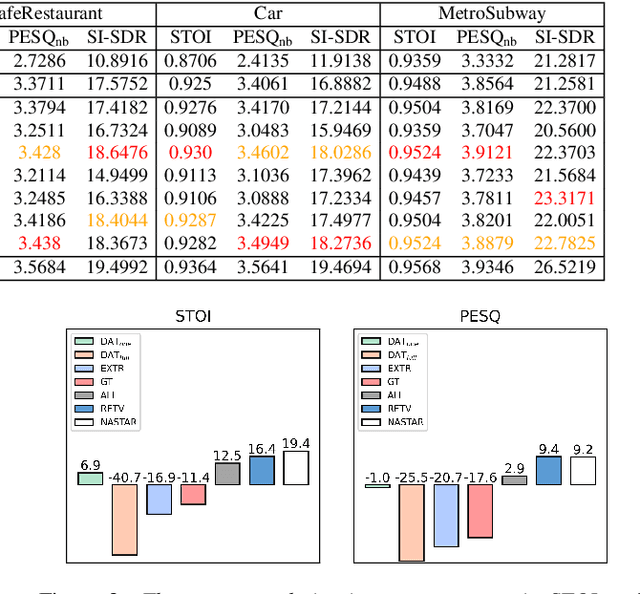
For deep learning-based speech enhancement (SE) systems, the training-test acoustic mismatch can cause notable performance degradation. To address the mismatch issue, numerous noise adaptation strategies have been derived. In this paper, we propose a novel method, called noise adaptive speech enhancement with target-conditional resampling (NASTAR), which reduces mismatches with only one sample (one-shot) of noisy speech in the target environment. NASTAR uses a feedback mechanism to simulate adaptive training data via a noise extractor and a retrieval model. The noise extractor estimates the target noise from the noisy speech, called pseudo-noise. The noise retrieval model retrieves relevant noise samples from a pool of noise signals according to the noisy speech, called relevant-cohort. The pseudo-noise and the relevant-cohort set are jointly sampled and mixed with the source speech corpus to prepare simulated training data for noise adaptation. Experimental results show that NASTAR can effectively use one noisy speech sample to adapt an SE model to a target condition. Moreover, both the noise extractor and the noise retrieval model contribute to model adaptation. To our best knowledge, NASTAR is the first work to perform one-shot noise adaptation through noise extraction and retrieval.
SERIL: Noise Adaptive Speech Enhancement using Regularization-based Incremental Learning
May 24, 2020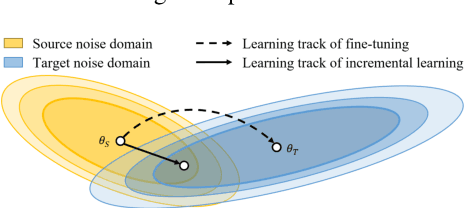
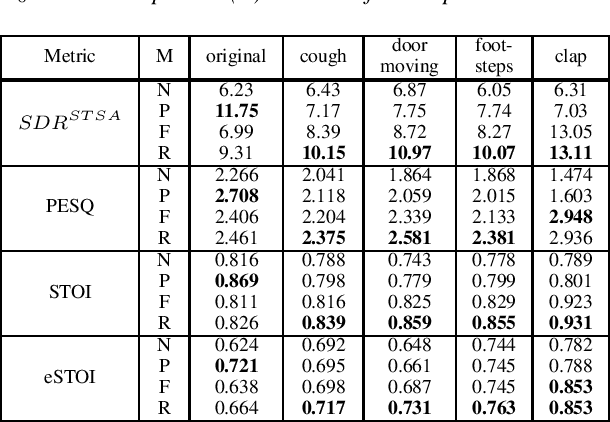

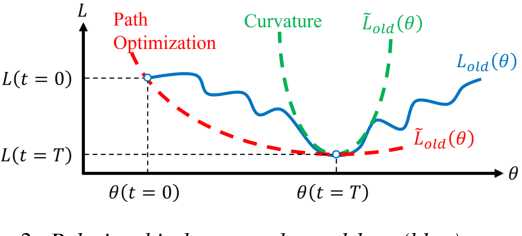
Numerous noise adaptation techniques have been proposed to address the mismatch problem in speech enhancement (SE) by fine-tuning deep-learning (DL)-based models. However, adaptation to a target domain can lead to catastrophic forgetting of the previously learnt noise environments. Because SE models are commonly used in embedded devices, re-visiting previous noise environments is a common situation in speech enhancement. In this paper, we propose a novel regularization-based incremental learning SE (SERIL) strategy, which can complement these noise adaptation strategies without having to access previous training data. The experimental results show that, when faced with a new noise domain, the SERIL model outperforms the unadapted SE model in various metrics: PESQ, STOI, eSTOI, and short-time spectral amplitude SDR. Meanwhile, compared with the traditional fine-tuning adaptive SE model, the SERIL model can significantly reduce the forgetting of previous noise environments by 52%. The promising results indicate that the SERIL model can effectively overcome the catastrophic forgetting problem and can be suitably deployed in real-world applications, where the noise environment changes frequently.