 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERIL: Noise Adaptive Speech Enhancement using Regularization-based Incremental Learning
Paper and Code
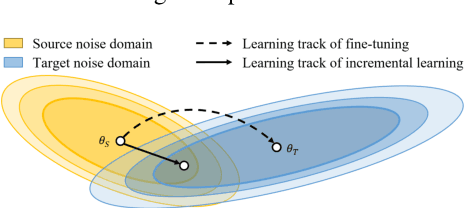
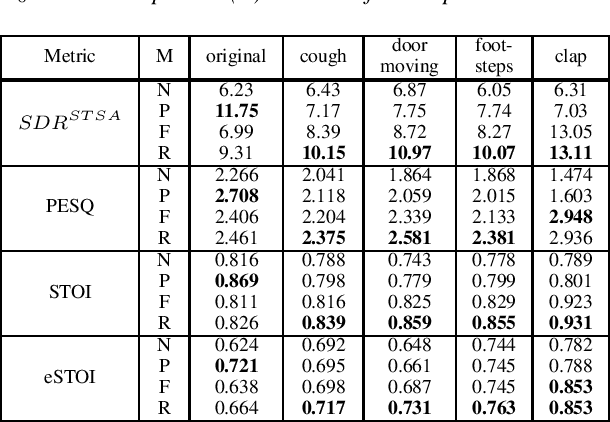

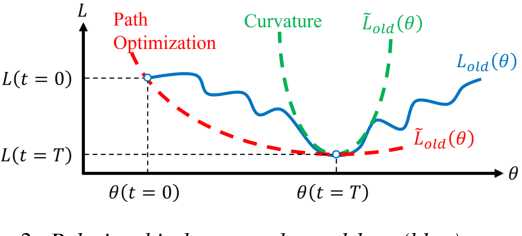
Numerous noise adaptation techniques have been proposed to address the mismatch problem in speech enhancement (SE) by fine-tuning deep-learning (DL)-based models. However, adaptation to a target domain can lead to catastrophic forgetting of the previously learnt noise environments. Because SE models are commonly used in embedded devices, re-visiting previous noise environments is a common situation in speech enhancement. In this paper, we propose a novel regularization-based incremental learning SE (SERIL) strategy, which can complement these noise adaptation strategies without having to access previous training data. The experimental results show that, when faced with a new noise domain, the SERIL model outperforms the unadapted SE model in various metrics: PESQ, STOI, eSTOI, and short-time spectral amplitude SDR. Meanwhile, compared with the traditional fine-tuning adaptive SE model, the SERIL model can significantly reduce the forgetting of previous noise environments by 52%. The promising results indicate that the SERIL model can effectively overcome the catastrophic forgetting problem and can be suitably deployed in real-world applications, where the noise environment changes frequently.