 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Skills from Action-Free Videos
Dec 23, 2025Learning from videos offers a promising path toward generalist robots by providing rich visual and temporal priors beyond what real robot datasets contain. While existing video generative models produce impressive visual predictions, they are difficult to translate into low-level actions. Conversely, latent-action models better align videos with actions, but they typically operate at the single-step level and lack high-level planning capabilities. We bridge this gap by introducing Skill Abstraction from Optical Flow (SOF), a framework that learns latent skills from large collections of action-free videos. Our key idea is to learn a latent skill space through an intermediate representation based on optical flow that captures motion information aligned with both video dynamics and robot actions. By learning skills in this flow-based latent space, SOF enables high-level planning over video-derived skills and allows for easier translation of these skills into actions. Experiments show that our approach consistently improves performance in both multitask and long-horizon settings, demonstrating the ability to acquire and compose skills directly from raw visual data.
Context-Aware Replanning with Pre-explored Semantic Map for Object Navigation
Sep 07, 2024
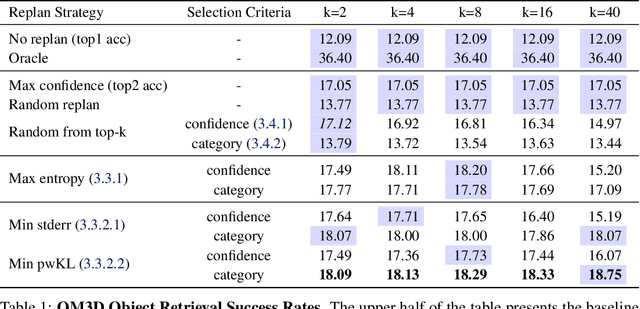
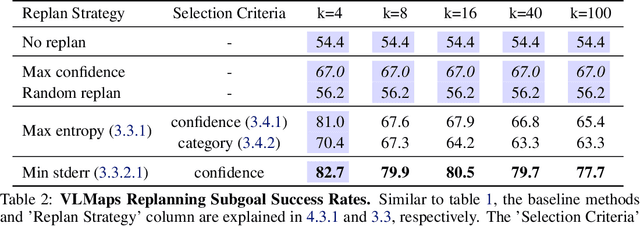
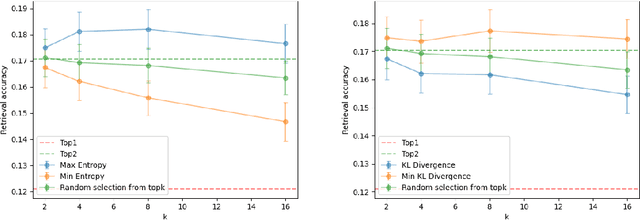
Pre-explored Semantic Maps, constructed through prior exploration using visual language models (VLMs), have proven effective as foundational elements for training-free robotic applications. However, existing approaches assume the map's accuracy and do not provide effective mechanisms for revising decisions based on incorrect maps. To address this, we introduce Context-Aware Replanning (CARe), which estimates map uncertainty through confidence scores and multi-view consistency, enabling the agent to revise erroneous decisions stemming from inaccurate maps without requiring additional labels. We demonstrate the effectiveness of our proposed method by integrating it with two modern mapping backbones, VLMaps and OpenMask3D, and observe significant performance improvements in object navigation tasks. More details can be found on the project page: https://carmaps.github.io/supplements/.
Learning to Act from Actionless Videos through Dense Correspondences
Oct 12, 2023In this work, we present an approach to construct a video-based robot policy capable of reliably executing diverse tasks across different robots and environments from few video demonstrations without using any action annotations. Our method leverages images as a task-agnostic representation, encoding both the state and action information, and text as a general representation for specifying robot goals. By synthesizing videos that ``hallucinate'' robot executing actions and in combination with dense correspondences between frames, our approach can infer the closed-formed action to execute to an environment without the need of any explicit action labels. This unique capability allows us to train the policy solely based on RGB videos and deploy learned policies to various robotic tasks. We demonstrate the efficacy of our approach in learning policies on table-top manipulation and navigation tasks. Additionally, we contribute an open-source framework for efficient video modeling, enabling the training of high-fidelity policy models with four GPUs within a single day.