 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineBench: Benchmarking and Enhancing Vision-Language Models for Fine-grained Human Activity Understanding
May 20, 2026Vision-Language Models (VLMs) have demonstrated remarkable capabilities in general video understanding, yet they often struggle with the fine-grained comprehension crucial for real-world applications requiring nuanced interpretation of human actions and interactions. While some recent human-centric benchmarks evaluate aspects of model behaviour such as fairness/ethics, emotion perception, and broader human-centric metrics, they do not combine long-form videos, very dense QA coverage, and frame-level spatial/temporal grounding at scale. To bridge this gap, we introduce FineBench, a human-centric video question answering (VQA) benchmark specifically designed to assess fine-grained understanding. FineBench comprises 199,420 multiple-choice QA pairs densely annotated across 64 long-form videos (15 minutes each), focusing on detailed person movement, person interaction, and object manipulation, including compositional actions. Our extensive evaluation reveals that while proprietary models like GPT-5 achieve respectable performance, current open-source VLMs significantly underperform, struggling particularly with spatial reasoning in multi-person scenes and distinguishing subtle differences in human movements and interactions. To address these identified weaknesses, we propose FineAgent, a modular framework that enhances VLMs by leveraging a Localizer and a Descriptor. Experiments show that FineAgent consistently improves the performance of various open VLMs on FineBench. FineBench provides a rigorous testbed for future research into fine-grained human-centric video understanding, while FineAgent offers a practical approach to enhance such reasoning in current VLMs. Project page and code at https://joslefaure.github.io/assets/html/finebench.html.
SPATIOROUTE: Dynamic Prompt Routing for Zero-Shot Spatial Reasoning
May 18, 2026Spatial question answering over egocentric video is a challenging task that requires Vision-Language Models (VLMs) to reason about 3D object positions, scene affordances, and directional relationships, particularly in the zero-shot setting where no task-specific fine-tuning is available. We introduce SpatioRoute, a dynamic prompt generation approach that routes each incoming question to a semantically tailored prompt template -- without any additional training, fine-tuning, or 3D sensor input. SpatioRoute operates in two complementary modes: SpatioRoute-R, a rule-based router that deterministically maps question typologies (e.g., What, Is, How, Can, Which) to specialized prompt templates; and SpatioRoute-L, an LLM-driven approach that generates task-specific prompts from the question and situational context alone, with no video input at routing time. We evaluate SpatioRoute on the SQA3D benchmark across VLMs spanning model families. SpatioRoute achieves consistent overall accuracy gains up to 5% over fixed prompt baselines, establishing a new state-of-the-art for zero-shot video-only spatial VQA without requiring 3D point-cloud inputs. As an additional finding, we observe that Chain-of-Thought (CoT) prompting, implemented via the Think it Twice architecture, consistently degrades performance in this setting on Qwen series models, confirming that question-aware routing is more effective than uniform reasoning instructions for spatial video understanding.
SceneFunRI: Reasoning the Invisible for Task-Driven Functional Object Localization
May 14, 2026In real-world scenes, target objects may reside in regions that are not visible. While humans can often infer the locations of occluded objects from context and commonsense knowledge, this capability remains a major challenge for vision-language models (VLMs). To address this gap, we introduce SceneFunRI, a benchmark for Reasoning the Invisible. Based on the SceneFun3D dataset, SceneFunRI formulates the task as a 2D spatial reasoning problem via a semi-automatic pipeline and comprises 855 instances. It requires models to infer the locations of invisible functional objects from task instructions and commonsense reasoning. The strongest baseline model (Gemini 3 Flash) only achieves an CAcc@75 of 15.20, an mIoU of 0.74, and a Dist of 28.65. We group our prompting analysis into three categories: Strong Instruction Prompting, Reasoning-based Prompting, and Spatial Process of Elimination (SPoE). These findings indicate that invisible-region reasoning remains an unstable capability in current VLMs, motivating future work on models that more tightly integrate task intent, commonsense priors, spatial grounding, and uncertainty-aware search.
MovieCORE: COgnitive REasoning in Movies
Aug 26, 2025



This paper introduces MovieCORE, a novel video question answering (VQA) dataset designed to probe deeper cognitive understanding of movie content. Unlike existing datasets that focus on surface-level comprehension, MovieCORE emphasizes questions that engage System-2 thinking while remaining specific to the video material. We present an innovative agentic brainstorming approach, utilizing multiple large language models (LLMs) as thought agents to generate and refine high-quality question-answer pairs. To evaluate dataset quality, we develop a set of cognitive tests assessing depth, thought-provocation potential, and syntactic complexity. We also propose a comprehensive evaluation scheme for assessing VQA model performance on deeper cognitive tasks. To address the limitations of existing video-language models (VLMs), we introduce an agentic enhancement module, Agentic Choice Enhancement (ACE), which improves model reasoning capabilities post-training by up to 25%. Our work contributes to advancing movie understanding in AI systems and provides valuable insights into the capabilities and limitations of current VQA models when faced with more challenging, nuanced questions about cinematic content. Our project page, dataset and code can be found at https://joslefaure.github.io/assets/html/moviecore.html.
Bridging Episodes and Semantics: A Novel Framework for Long-Form Video Understanding
Aug 30, 2024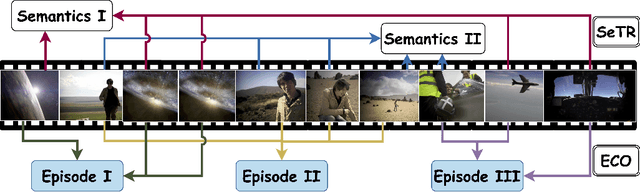
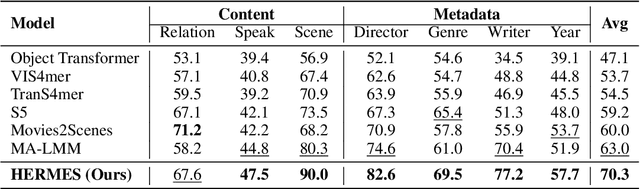
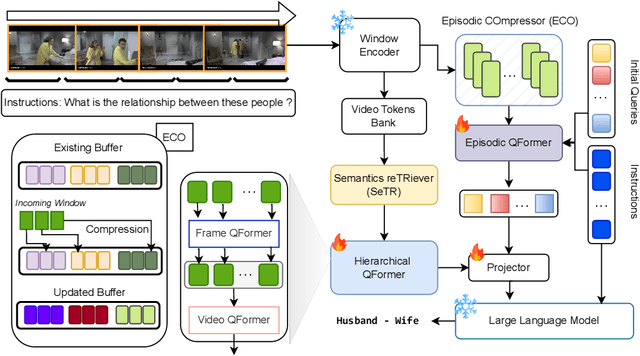

While existing research often treats long-form videos as extended short videos, we propose a novel approach that more accurately reflects human cognition. This paper introduces BREASE: BRidging Episodes And SEmantics for Long-Form Video Understanding, a model that simulates episodic memory accumulation to capture action sequences and reinforces them with semantic knowledge dispersed throughout the video. Our work makes two key contributions: First, we develop an Episodic COmpressor (ECO) that efficiently aggregates crucial representations from micro to semi-macro levels. Second, we propose a Semantics reTRiever (SeTR) that enhances these aggregated representations with semantic information by focusing on the broader context, dramatically reducing feature dimensionality while preserving relevant macro-level information. Extensive experiments demonstrate that BREASE achieves state-of-the-art performance across multiple long video understanding benchmarks in both zero-shot and fully-supervised settings. The project page and code are at: https://joslefaure.github.io/assets/html/hermes.html.
Interaction-Aware Prompting for Zero-Shot Spatio-Temporal Action Detection
Apr 11, 2023The goal of spatial-temporal action detection is to determine the time and place where each person's action occurs in a video and classify the corresponding action category. Most of the existing methods adopt fully-supervised learning, which requires a large amount of training data, making it very difficult to achieve zero-shot learning. In this paper, we propose to utilize a pre-trained visual-language model to extract the representative image and text features, and model the relationship between these features through different interaction modules to obtain the interaction feature. In addition, we use this feature to prompt each label to obtain more appropriate text features. Finally, we calculate the similarity between the interaction feature and the text feature for each label to determine the action category. Our experiments on J-HMDB and UCF101-24 datasets demonstrate that the proposed interaction module and prompting make the visual-language features better aligned, thus achieving excellent accuracy for zero-shot spatio-temporal action detection. The code will be released upon acceptance.
Holistic Interaction Transformer Network for Action Detection
Oct 23, 2022Actions are about how we interact with the environment, including other people, objects, and ourselves. In this paper, we propose a novel multi-modal Holistic Interaction Transformer Network (HIT) that leverages the largely ignored, but critical hand and pose information essential to most human actions. The proposed "HIT" network is a comprehensive bi-modal framework that comprises an RGB stream and a pose stream. Each of them separately models person, object, and hand interactions. Within each sub-network, an Intra-Modality Aggregation module (IMA) is introduced that selectively merges individual interaction units. The resulting features from each modality are then glued using an Attentive Fusion Mechanism (AFM). Finally, we extract cues from the temporal context to better classify the occurring actions using cached memory. Our method significantly outperforms previous approaches on the J-HMDB, UCF101-24, and MultiSports datasets. We also achieve competitive results on AVA. The code will be available at https://github.com/joslefaure/HIT.