 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShadowSense: Unsupervised Domain Adaptation and Feature Fusion for Shadow-Agnostic Tree Crown Detection from RGB-Thermal Drone Imagery
Oct 24, 2023Accurate detection of individual tree crowns from remote sensing data poses a significant challenge due to the dense nature of forest canopy and the presence of diverse environmental variations, e.g., overlapping canopies, occlusions, and varying lighting conditions. Additionally, the lack of data for training robust models adds another limitation in effectively studying complex forest conditions. This paper presents a novel method for detecting shadowed tree crowns and provides a challenging dataset comprising roughly 50k paired RGB-thermal images to facilitate future research for illumination-invariant detection. The proposed method (ShadowSense) is entirely self-supervised, leveraging domain adversarial training without source domain annotations for feature extraction and foreground feature alignment for feature pyramid networks to adapt domain-invariant representations by focusing on visible foreground regions, respectively. It then fuses complementary information of both modalities to effectively improve upon the predictions of an RGB-trained detector and boost the overall accuracy. Extensive experiments demonstrate the superiority of the proposed method over both the baseline RGB-trained detector and state-of-the-art techniques that rely on unsupervised domain adaptation or early image fusion. Our code and data are available: https://github.com/rudrakshkapil/ShadowSense
TMR-RD: Training-based Model Refinement and Representation Disagreement for Semi-Supervised Object Detection
Jul 25, 2023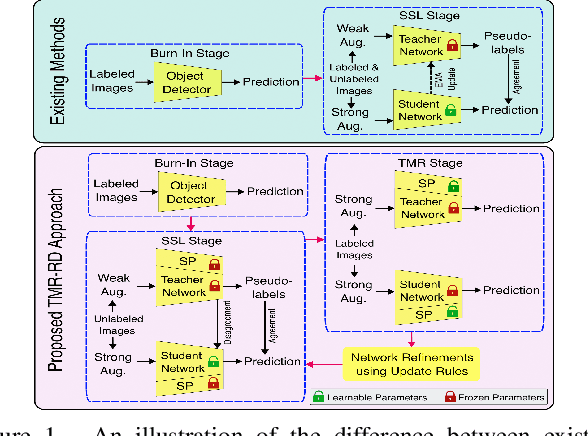
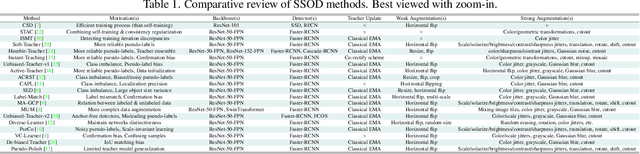
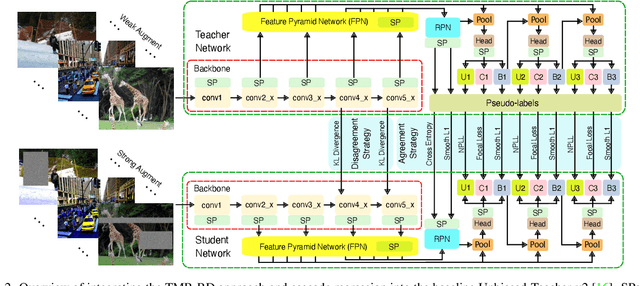
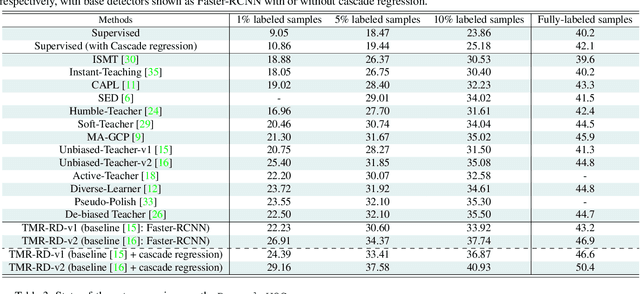
Semi-supervised object detection (SSOD) can incorporate limited labeled data and large amounts of unlabeled data to improve the performance and generalization of existing object detectors. Despite many advances, recent SSOD methods are still challenged by noisy/misleading pseudo-labels, classical exponential moving average (EMA) strategy, and the consensus of Teacher-Student models in the latter stages of training. This paper proposes a novel training-based model refinement (TMR) stage and a simple yet effective representation disagreement (RD) strategy to address the limitations of classical EMA and the consensus problem. The TMR stage of Teacher-Student models optimizes the lightweight scaling operation to refine the model's weights and prevent overfitting or forgetting learned patterns from unlabeled data. Meanwhile, the RD strategy helps keep these models diverged to encourage the student model to explore complementary representations. In addition, we use cascade regression to generate more reliable pseudo-labels for supervising the student model. Extensive experiments demonstrate the superior performance of our approach over state-of-the-art SSOD methods. Specifically, the proposed approach outperforms the Unbiased-Teacher method by an average mAP margin of 4.6% and 5.3% when using partially-labeled and fully-labeled data on the MS-COCO dataset, respectively.
Crown-CAM: Reliable Visual Explanations for Tree Crown Detection in Aerial Images
Nov 23, 2022



Visual explanation of "black-box" models has enabled researchers and experts in artificial intelligence (AI) to exploit the localization abilities of such methods to a much greater extent. Despite most of the developed visual explanation methods applied to single object classification problems, they are not well-explored in the detection task, where the challenges may go beyond simple coarse area-based discrimination. This is of particular importance when a detector should face several objects with different scales from various viewpoints or if the objects of interest are absent. In this paper, we propose CrownCAM to generate reliable visual explanations for the challenging and dynamic problem of tree crown detection in aerial images. It efficiently provides fine-grain localization of tree crowns and non-contextual background suppression for scenarios with highly dense forest trees in the presence of potential distractors or scenes without tree crowns. Additionally, two Intersection over Union (IoU)-based metrics are introduced that can effectively quantify both the accuracy and inaccuracy of generated visual explanations with respect to regions with or without tree crowns in the image. Empirical evaluations demonstrate that the proposed Crown-CAM outperforms the Score-CAM, Augmented ScoreCAM, and Eigen-CAM methods by an average IoU margin of 8.7, 5.3, and 21.7 (and 3.3, 9.8, and 16.5) respectively in improving the accuracy (and decreasing inaccuracy) of visual explanations on the challenging NEON tree crown dataset.
Early Detection of Bark Beetle Attack Using Remote Sensing and Machine Learning: A Review
Oct 07, 2022
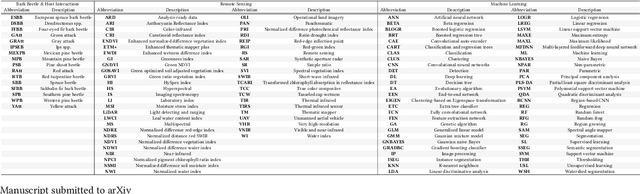


Bark beetle outbreaks can result in a devastating impact on forest ecosystem processes, biodiversity, forest structure and function, and economies. Accurate and timely detection of bark beetle infestations is crucial to mitigate further damage, develop proactive forest management activities, and minimize economic losses. Incorporating remote sensing (RS) data with machine learning (ML) (or deep learning (DL)) can provide a great alternative to the current approaches that rely on aerial surveys and field surveys, which are impractical over vast geographical regions. This paper provides a comprehensive review of past and current advances in the early detection of bark beetle-induced tree mortality from three key perspectives: bark beetle & host interactions, RS, and ML/DL. We parse recent literature according to bark beetle species & attack phases, host trees, study regions, imagery platforms & sensors, spectral/spatial/temporal resolutions, spectral signatures, spectral vegetation indices (SVIs), ML approaches, learning schemes, task categories, models, algorithms, classes/clusters, features, and DL networks & architectures. This review focuses on challenging early detection, discussing current challenges and potential solutions. Our literature survey suggests that the performance of current ML methods is limited (less than 80%) and depends on various factors, including imagery sensors & resolutions, acquisition dates, and employed features & algorithms/networks. A more promising result from DL networks and then the random forest (RF) algorithm highlighted the potential to detect subtle changes in visible, thermal, and short-wave infrared (SWIR) spectral regions.
Classification of Bark Beetle-Induced Forest Tree Mortality using Deep Learning
Jul 15, 2022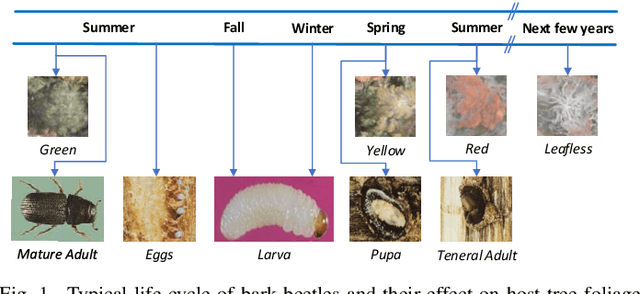
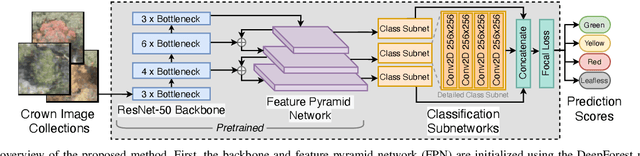
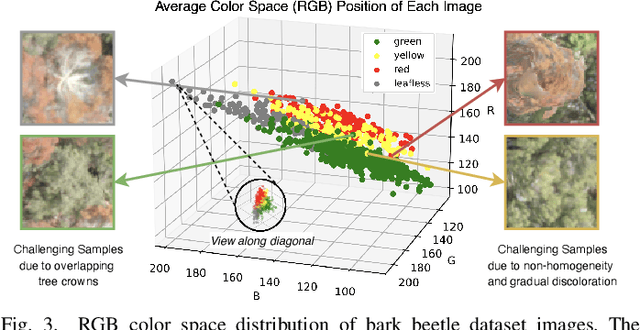
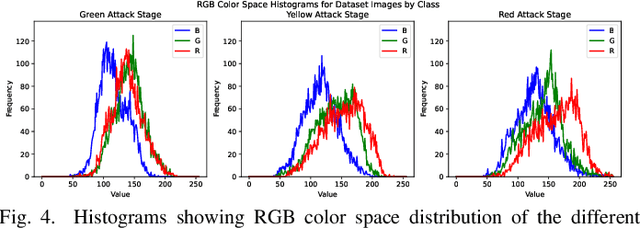
Bark beetle outbreaks can dramatically impact forest ecosystems and services around the world. For the development of effective forest policies and management plans, the early detection of infested trees is essential. Despite the visual symptoms of bark beetle infestation, this task remains challenging, considering overlapping tree crowns and non-homogeneity in crown foliage discolouration. In this work, a deep learning based method is proposed to effectively classify different stages of bark beetle attacks at the individual tree level. The proposed method uses RetinaNet architecture (exploiting a robust feature extraction backbone pre-trained for tree crown detection) to train a shallow subnetwork for classifying the different attack stages of images captured by unmanned aerial vehicles (UAVs). Moreover, various data augmentation strategies are examined to address the class imbalance problem, and consequently, the affine transformation is selected to be the most effective one for this purpose. Experimental evaluations demonstrate the effectiveness of the proposed method by achieving an average accuracy of 98.95%, considerably outperforming the baseline method by approximately 10%.
Learning-based Monocular 3D Reconstruction of Birds: A Contemporary Survey
Jul 10, 2022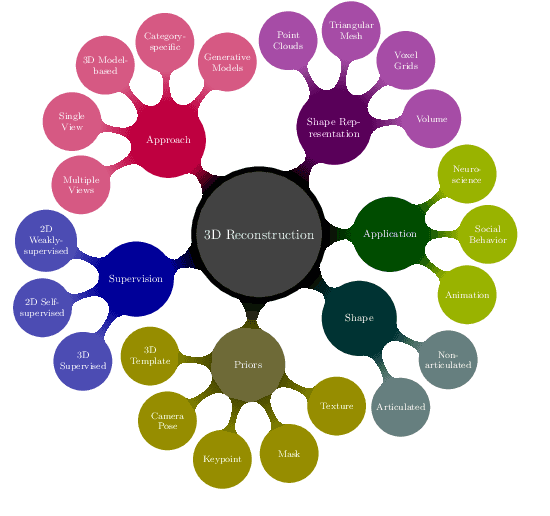

In nature, the collective behavior of animals, such as flying birds is dominated by the interactions between individuals of the same species. However, the study of such behavior among the bird species is a complex process that humans cannot perform using conventional visual observational techniques such as focal sampling in nature. For social animals such as birds, the mechanism of group formation can help ecologists understand the relationship between social cues and their visual characteristics over time (e.g., pose and shape). But, recovering the varying pose and shapes of flying birds is a highly challenging problem. A widely-adopted solution to tackle this bottleneck is to extract the pose and shape information from 2D image to 3D correspondence. Recent advances in 3D vision have led to a number of impressive works on the 3D shape and pose estimation, each with different pros and cons. To the best of our knowledge, this work is the first attempt to provide an overview of recent advances in 3D bird reconstruction based on monocular vision, give both computer vision and biology researchers an overview of existing approaches, and compare their characteristics.
CHASE: Robust Visual Tracking via Cell-Level Differentiable Neural Architecture Search
Jul 02, 2021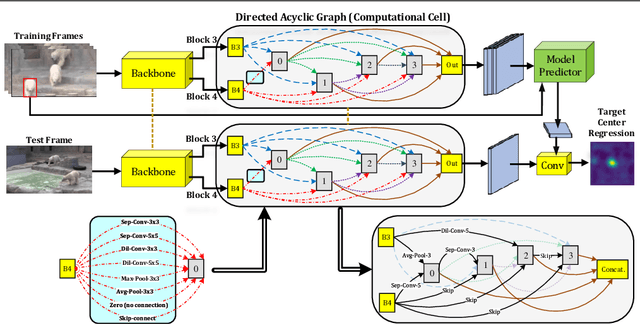

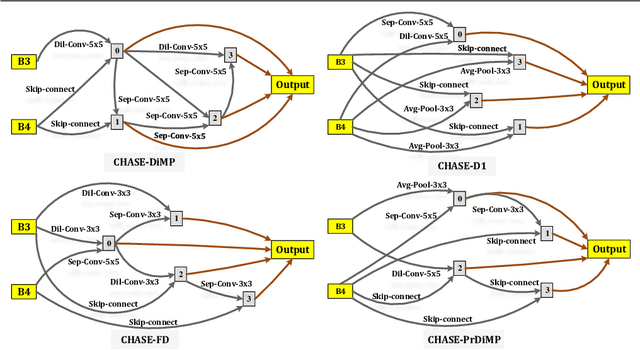
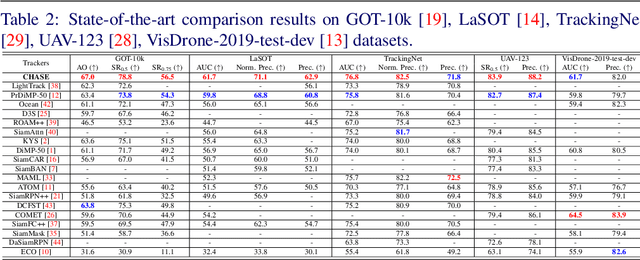
A strong visual object tracker nowadays relies on its well-crafted modules, which typically consist of manually-designed network architectures to deliver high-quality tracking results. Not surprisingly, the manual design process becomes a particularly challenging barrier, as it demands sufficient prior experience, enormous effort, intuition and perhaps some good luck. Meanwhile, neural architecture search has gaining grounds in practical applications such as image segmentation, as a promising method in tackling the issue of automated search of feasible network structures. In this work, we propose a novel cell-level differentiable architecture search mechanism to automate the network design of the tracking module, aiming to adapt backbone features to the objective of a tracking network during offline training. The proposed approach is simple, efficient, and with no need to stack a series of modules to construct a network. Our approach is easy to be incorporated into existing trackers, which is empirically validated using different differentiable architecture search-based methods and tracking objectives. Extensive experimental evaluations demonstrate the superior performance of our approach over five commonly-used benchmarks. Meanwhile, our automated searching process takes 41 (18) hours for the second (first) order DARTS method on the TrackingNet dataset.
Adaptive Exploitation of Pre-trained Deep Convolutional Neural Networks for Robust Visual Tracking
Aug 29, 2020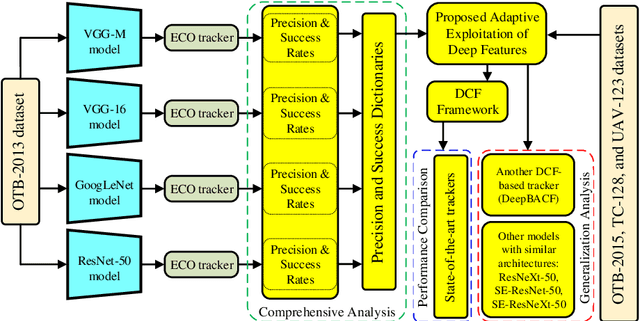
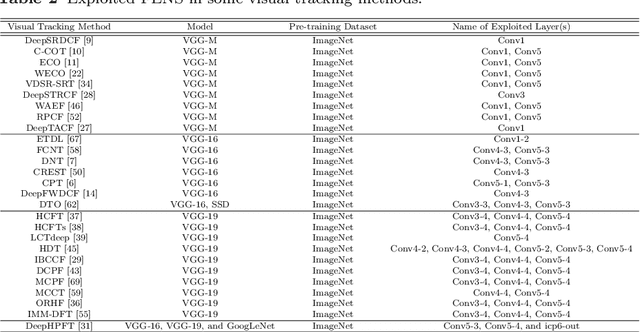
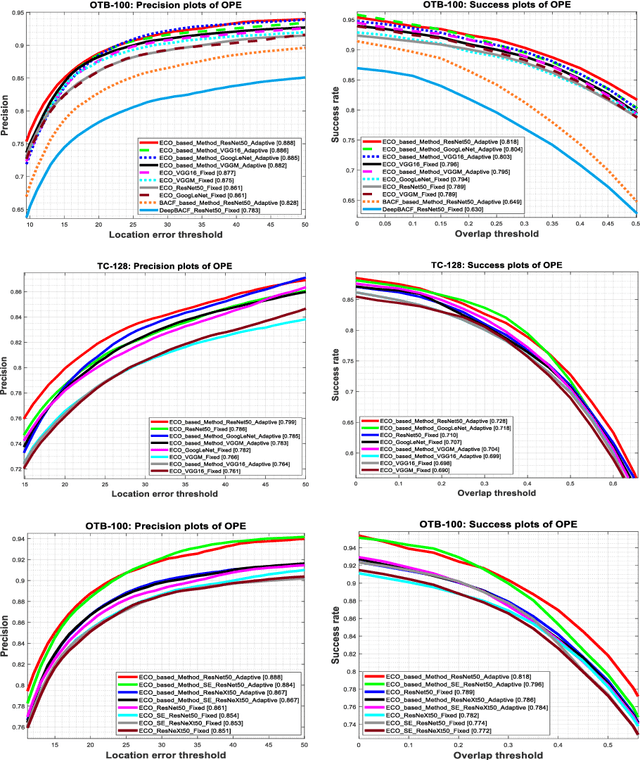
Due to the automatic feature extraction procedure via multi-layer nonlinear transformations, the deep learning-based visual trackers have recently achieved great success in challenging scenarios for visual tracking purposes. Although many of those trackers utilize the feature maps from pre-trained convolutional neural networks (CNNs), the effects of selecting different models and exploiting various combinations of their feature maps are still not compared completely. To the best of our knowledge, all those methods use a fixed number of convolutional feature maps without considering the scene attributes (e.g., occlusion, deformation, and fast motion) that might occur during tracking. As a pre-requisition, this paper proposes adaptive discriminative correlation filters (DCF) based on the methods that can exploit CNN models with different topologies. First, the paper provides a comprehensive analysis of four commonly used CNN models to determine the best feature maps of each model. Second, with the aid of analysis results as attribute dictionaries, adaptive exploitation of deep features is proposed to improve the accuracy and robustness of visual trackers regarding video characteristics. Third, the generalization of the proposed method is validated on various tracking datasets as well as CNN models with similar architectures. Finally, extensive experimental results demonstrate the effectiveness of the proposed adaptive method compared with state-of-the-art visual tracking methods.
COMET: Context-Aware IoU-Guided Network for Small Object Tracking
Jun 04, 2020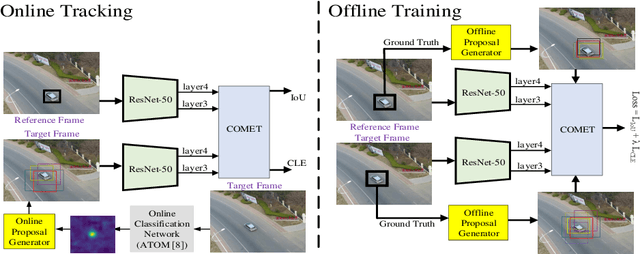
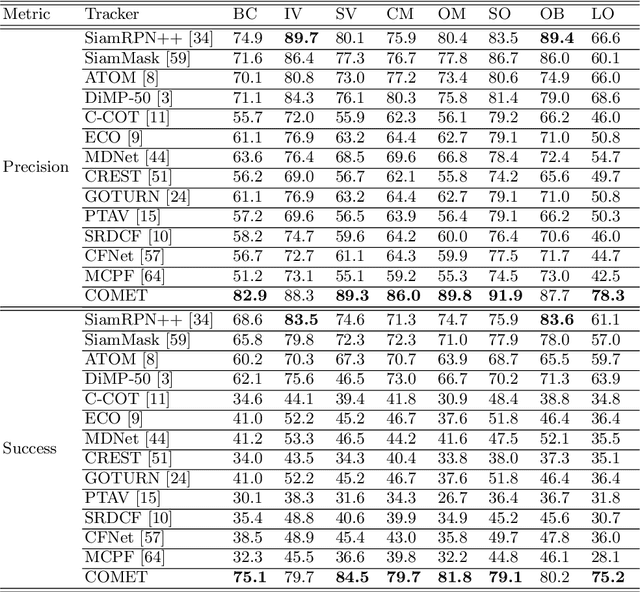
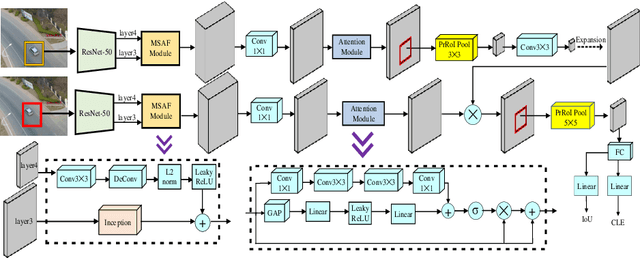
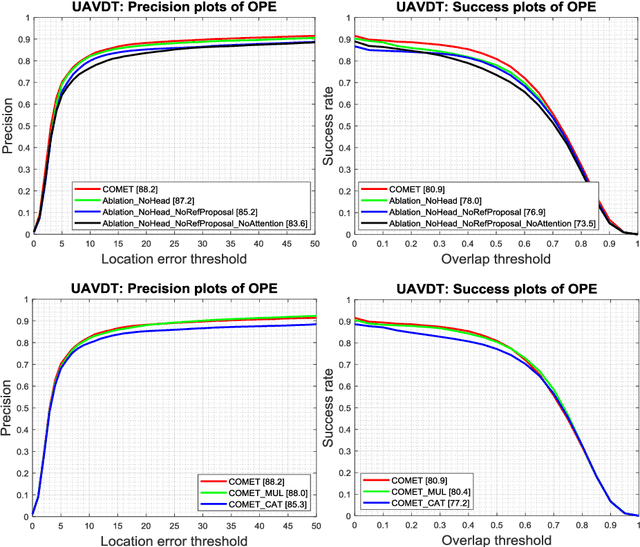
Tracking an unknown target captured from medium- or high-aerial view is challenging, especially in scenarios of small objects, large viewpoint change, drastic camera motion, and high density. This paper introduces a context-aware IoU-guided tracker that exploits an offline reference proposal generation strategy and a multitask two-stream network. The proposed strategy introduces an efficient sampling strategy to generalize the network on the target and its parts without imposing extra computational complexity during online tracking. It considerably helps the proposed tracker, COMET, to handle occlusion and view-point change, where only some parts of the target are visible. Extensive experimental evaluations on broad range of small object benchmarks (UAVDT, VisDrone-2019, and Small-90) demonstrate the effectiveness of our approach for small object tracking.
Efficient Scale Estimation Methods using Lightweight Deep Convolutional Neural Networks for Visual Tracking
Apr 06, 2020
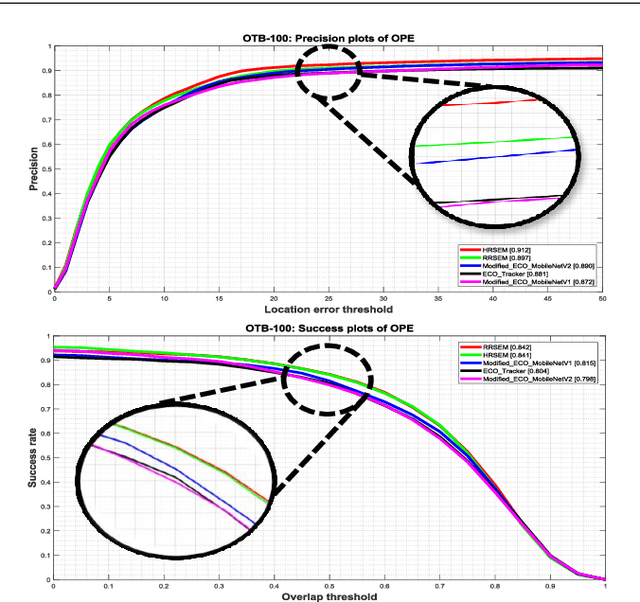
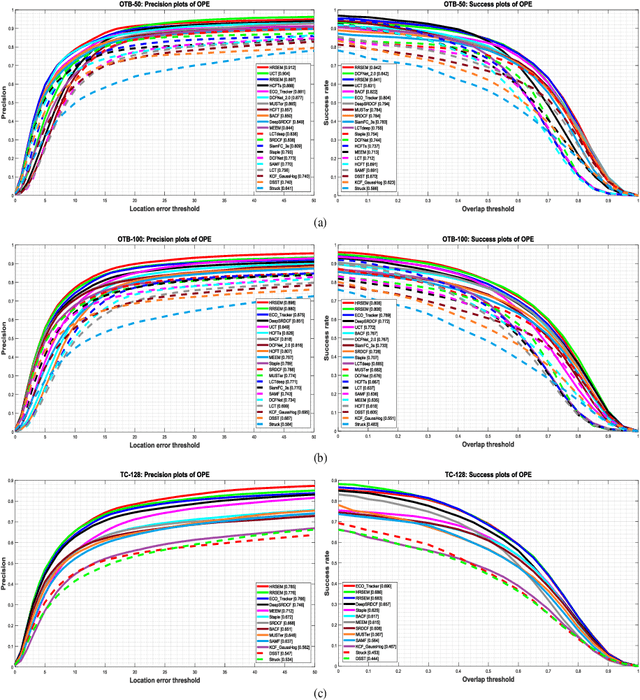
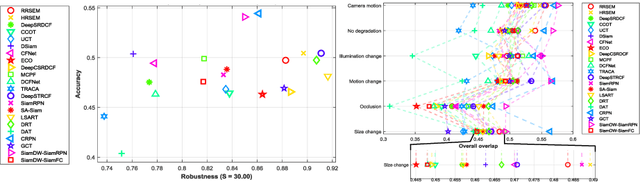
In recent years, visual tracking methods that are based on discriminative correlation filters (DCF) have been very promising. However, most of these methods suffer from a lack of robust scale estimation skills. Although a wide range of recent DCF-based methods exploit the features that are extracted from deep convolutional neural networks (CNNs) in their translation model, the scale of the visual target is still estimated by hand-crafted features. Whereas the exploitation of CNNs imposes a high computational burden, this paper exploits pre-trained lightweight CNNs models to propose two efficient scale estimation methods, which not only improve the visual tracking performance but also provide acceptable tracking speeds. The proposed methods are formulated based on either holistic or region representation of convolutional feature maps to efficiently integrate into DCF formulations to learn a robust scale model in the frequency domain. Moreover, against the conventional scale estimation methods with iterative feature extraction of different target regions, the proposed methods exploit proposed one-pass feature extraction processes that significantly improve the computational efficiency. Comprehensive experimental results on the OTB-50, OTB-100, TC-128 and VOT-2018 visual tracking datasets demonstrate that the proposed visual tracking methods outperform the state-of-the-art methods, effectively.