 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHASE: Robust Visual Tracking via Cell-Level Differentiable Neural Architecture Search
Jul 02, 2021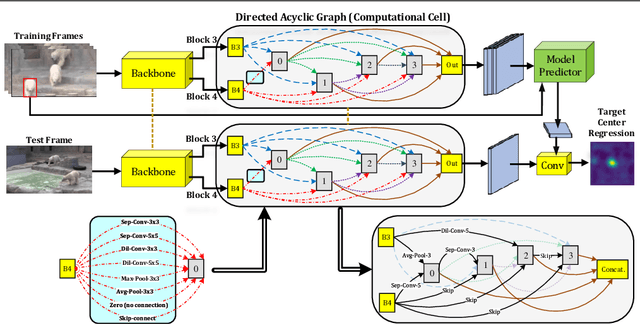

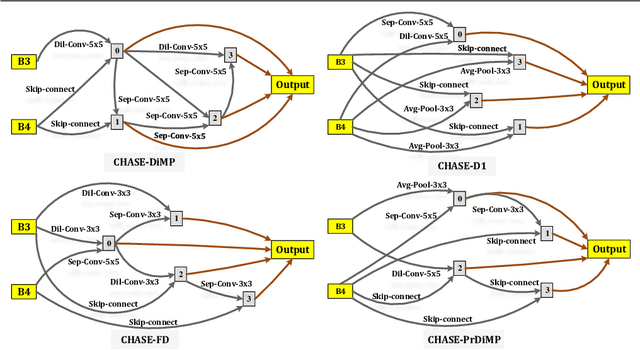
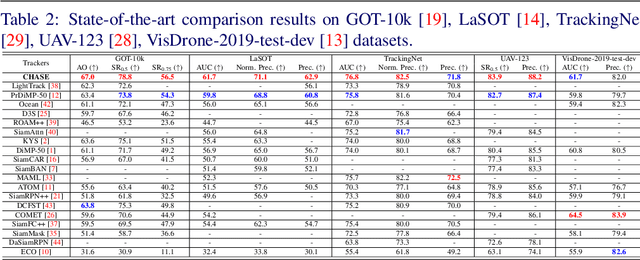
A strong visual object tracker nowadays relies on its well-crafted modules, which typically consist of manually-designed network architectures to deliver high-quality tracking results. Not surprisingly, the manual design process becomes a particularly challenging barrier, as it demands sufficient prior experience, enormous effort, intuition and perhaps some good luck. Meanwhile, neural architecture search has gaining grounds in practical applications such as image segmentation, as a promising method in tackling the issue of automated search of feasible network structures. In this work, we propose a novel cell-level differentiable architecture search mechanism to automate the network design of the tracking module, aiming to adapt backbone features to the objective of a tracking network during offline training. The proposed approach is simple, efficient, and with no need to stack a series of modules to construct a network. Our approach is easy to be incorporated into existing trackers, which is empirically validated using different differentiable architecture search-based methods and tracking objectives. Extensive experimental evaluations demonstrate the superior performance of our approach over five commonly-used benchmarks. Meanwhile, our automated searching process takes 41 (18) hours for the second (first) order DARTS method on the TrackingNet dataset.
Adaptive Exploitation of Pre-trained Deep Convolutional Neural Networks for Robust Visual Tracking
Aug 29, 2020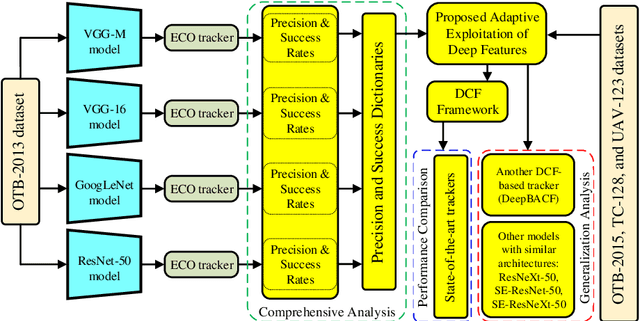
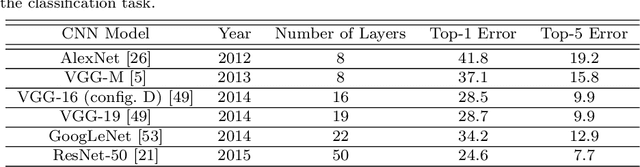
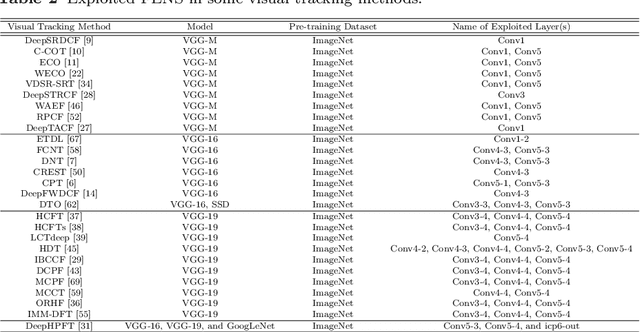
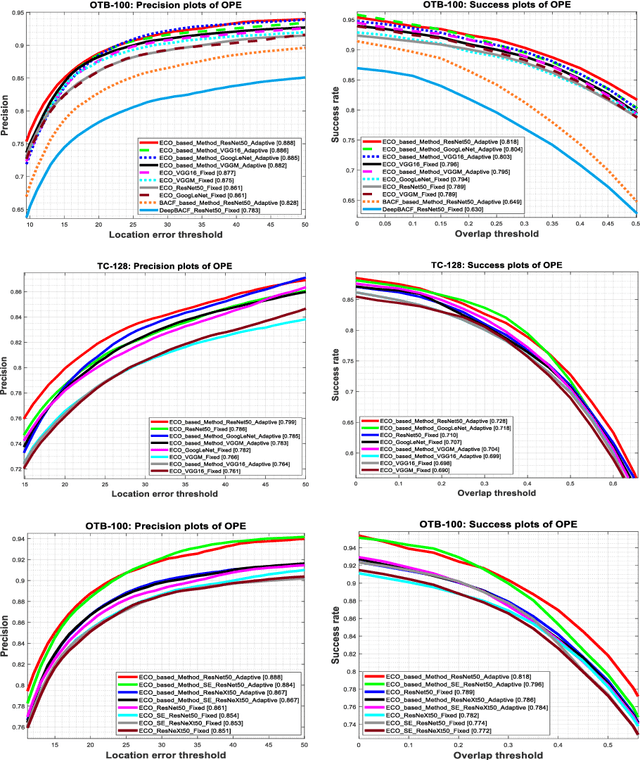
Due to the automatic feature extraction procedure via multi-layer nonlinear transformations, the deep learning-based visual trackers have recently achieved great success in challenging scenarios for visual tracking purposes. Although many of those trackers utilize the feature maps from pre-trained convolutional neural networks (CNNs), the effects of selecting different models and exploiting various combinations of their feature maps are still not compared completely. To the best of our knowledge, all those methods use a fixed number of convolutional feature maps without considering the scene attributes (e.g., occlusion, deformation, and fast motion) that might occur during tracking. As a pre-requisition, this paper proposes adaptive discriminative correlation filters (DCF) based on the methods that can exploit CNN models with different topologies. First, the paper provides a comprehensive analysis of four commonly used CNN models to determine the best feature maps of each model. Second, with the aid of analysis results as attribute dictionaries, adaptive exploitation of deep features is proposed to improve the accuracy and robustness of visual trackers regarding video characteristics. Third, the generalization of the proposed method is validated on various tracking datasets as well as CNN models with similar architectures. Finally, extensive experimental results demonstrate the effectiveness of the proposed adaptive method compared with state-of-the-art visual tracking methods.
COMET: Context-Aware IoU-Guided Network for Small Object Tracking
Jun 04, 2020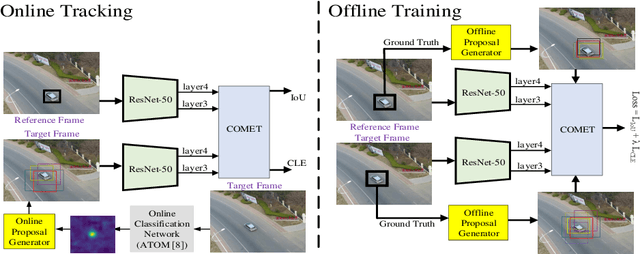
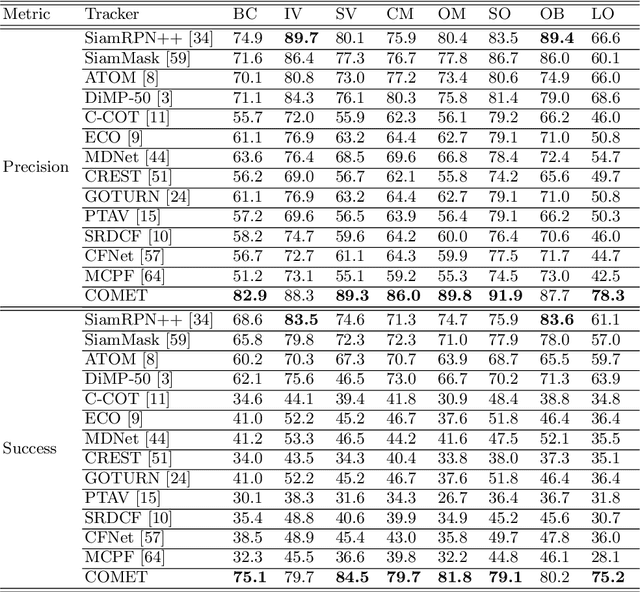
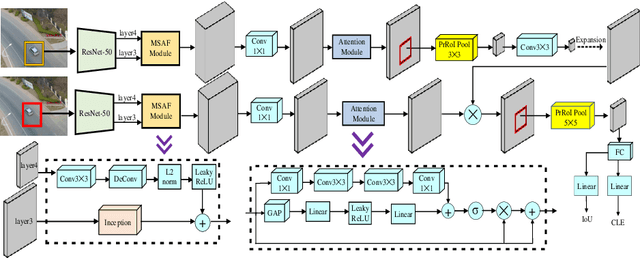
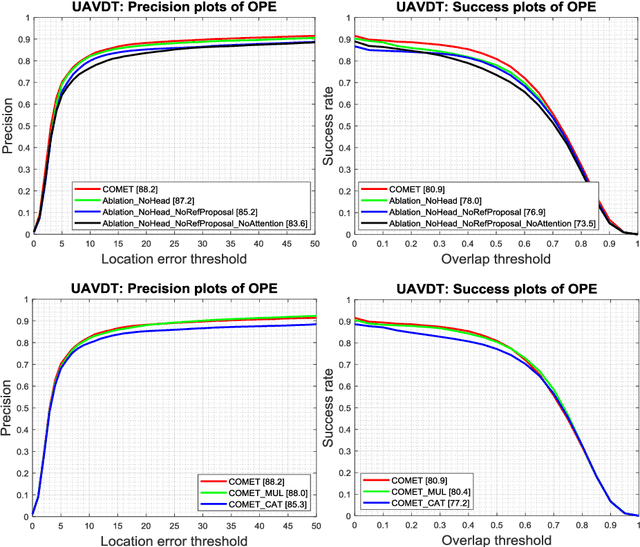
Tracking an unknown target captured from medium- or high-aerial view is challenging, especially in scenarios of small objects, large viewpoint change, drastic camera motion, and high density. This paper introduces a context-aware IoU-guided tracker that exploits an offline reference proposal generation strategy and a multitask two-stream network. The proposed strategy introduces an efficient sampling strategy to generalize the network on the target and its parts without imposing extra computational complexity during online tracking. It considerably helps the proposed tracker, COMET, to handle occlusion and view-point change, where only some parts of the target are visible. Extensive experimental evaluations on broad range of small object benchmarks (UAVDT, VisDrone-2019, and Small-90) demonstrate the effectiveness of our approach for small object tracking.
Efficient Scale Estimation Methods using Lightweight Deep Convolutional Neural Networks for Visual Tracking
Apr 06, 2020
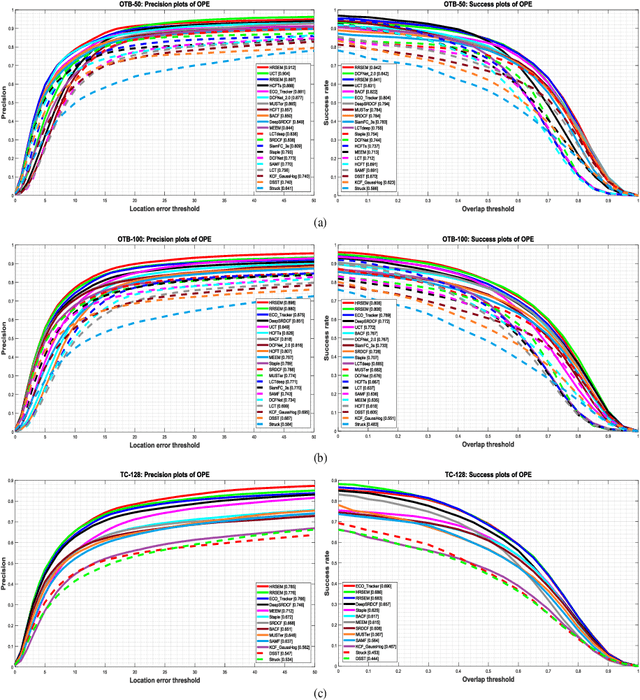
In recent years, visual tracking methods that are based on discriminative correlation filters (DCF) have been very promising. However, most of these methods suffer from a lack of robust scale estimation skills. Although a wide range of recent DCF-based methods exploit the features that are extracted from deep convolutional neural networks (CNNs) in their translation model, the scale of the visual target is still estimated by hand-crafted features. Whereas the exploitation of CNNs imposes a high computational burden, this paper exploits pre-trained lightweight CNNs models to propose two efficient scale estimation methods, which not only improve the visual tracking performance but also provide acceptable tracking speeds. The proposed methods are formulated based on either holistic or region representation of convolutional feature maps to efficiently integrate into DCF formulations to learn a robust scale model in the frequency domain. Moreover, against the conventional scale estimation methods with iterative feature extraction of different target regions, the proposed methods exploit proposed one-pass feature extraction processes that significantly improve the computational efficiency. Comprehensive experimental results on the OTB-50, OTB-100, TC-128 and VOT-2018 visual tracking datasets demonstrate that the proposed visual tracking methods outperform the state-of-the-art methods, effectively.
Beyond Background-Aware Correlation Filters: Adaptive Context Modeling by Hand-Crafted and Deep RGB Features for Visual Tracking
Apr 06, 2020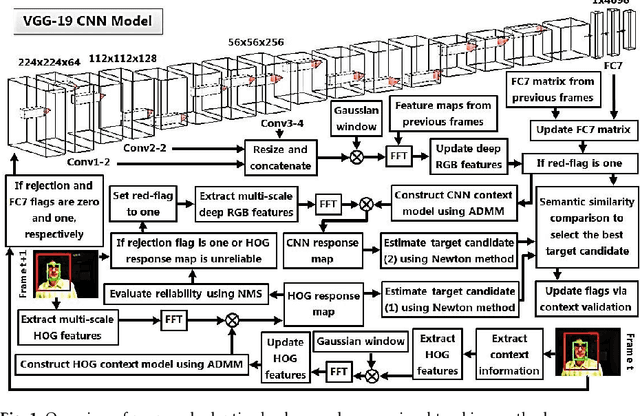
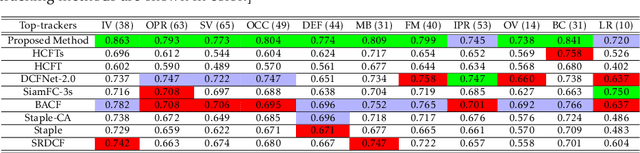


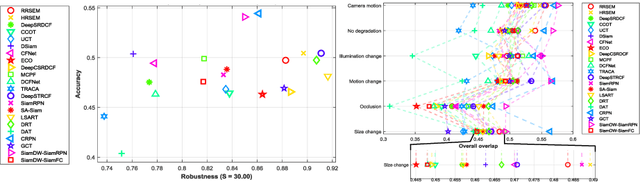
In recent years, the background-aware correlation filters have achie-ved a lot of research interest in the visual target tracking. However, these methods cannot suitably model the target appearance due to the exploitation of hand-crafted features. On the other hand, the recent deep learning-based visual tracking methods have provided a competitive performance along with extensive computations. In this paper, an adaptive background-aware correlation filter-based tracker is proposed that effectively models the target appearance by using either the histogram of oriented gradients (HOG) or convolutional neural network (CNN) feature maps. The proposed method exploits the fast 2D non-maximum suppression (NMS) algorithm and the semantic information comparison to detect challenging situations. When the HOG-based response map is not reliable, or the context region has a low semantic similarity with prior regions, the proposed method constructs the CNN context model to improve the target region estimation. Furthermore, the rejection option allows the proposed method to update the CNN context model only on valid regions. Comprehensive experimental results demonstrate that the proposed adaptive method clearly outperforms the accuracy and robustness of visual target tracking compared to the state-of-the-art methods on the OTB-50, OTB-100, TC-128, UAV-123, and VOT-2015 datasets.
Effective Fusion of Deep Multitasking Representations for Robust Visual Tracking
Apr 03, 2020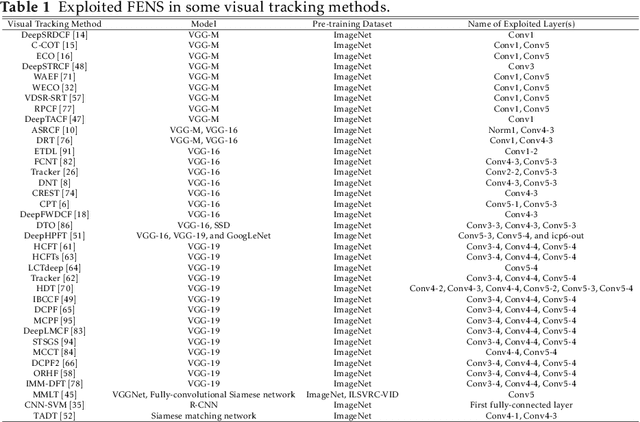
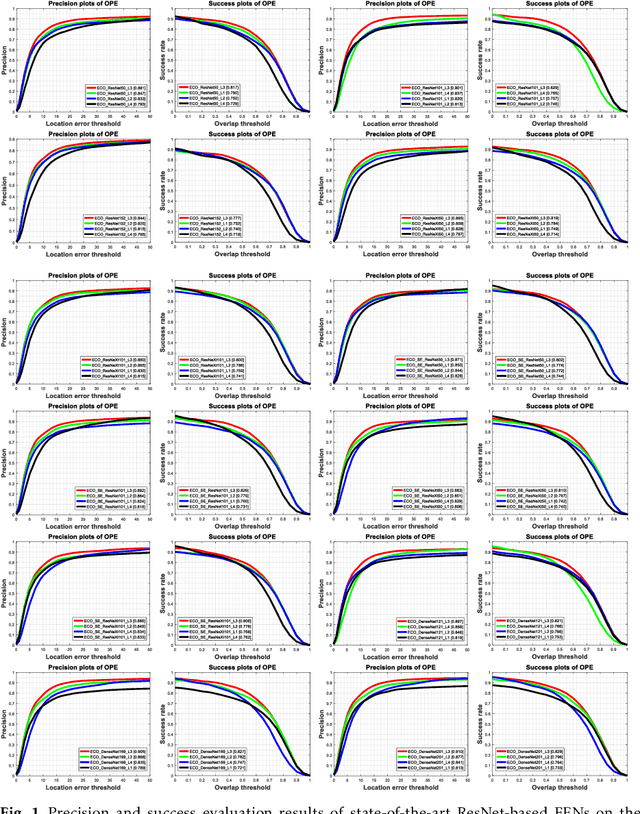
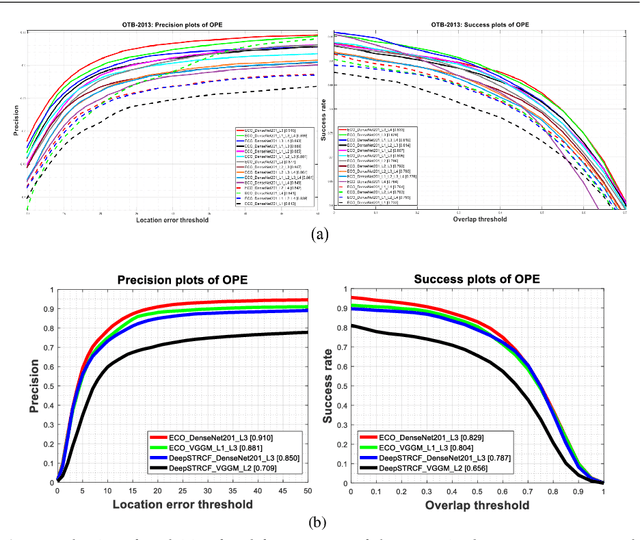
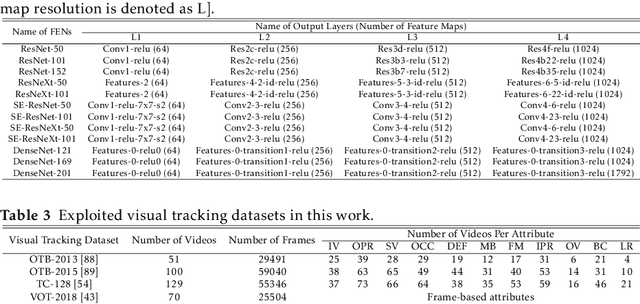
Visual object tracking remains an active research field in computer vision due to persisting challenges with various problem-specific factors in real-world scenes. Many existing tracking methods based on discriminative correlation filters (DCFs) employ feature extraction networks (FENs) to model the target appearance during the learning process. However, using deep feature maps extracted from FENs based on different residual neural networks (ResNets) has not previously been investigated. This paper aims to evaluate the performance of twelve state-of-the-art ResNet-based FENs in a DCF-based framework to determine the best for visual tracking purposes. First, it ranks their best feature maps and explores the generalized adoption of the best ResNet-based FEN into another DCF-based method. Then, the proposed method extracts deep semantic information from a fully convolutional FEN and fuses it with the best ResNet-based feature maps to strengthen the target representation in the learning process of continuous convolution filters. Finally, it introduces a new and efficient semantic weighting method (using semantic segmentation feature maps on each video frame) to reduce the drift problem. Extensive experimental results on the well-known OTB-2013, OTB-2015, TC-128 and VOT-2018 visual tracking datasets demonstrate that the proposed method effectively outperforms state-of-the-art methods in terms of precision and robustness of visual tracking.
Deep Learning for Visual Tracking: A Comprehensive Survey
Dec 02, 2019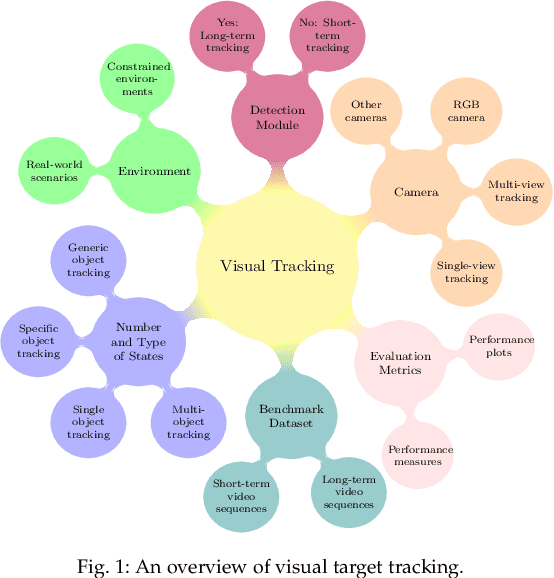
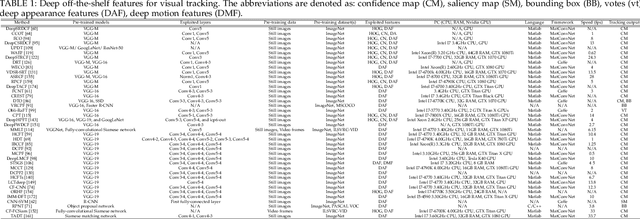
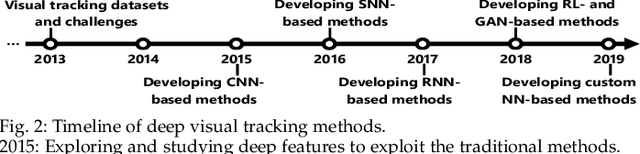
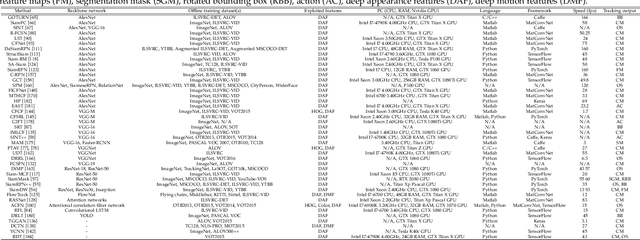
Visual target tracking is one of the most sought-after yet challenging research topics in computer vision. Given the ill-posed nature of the problem and its popularity in a broad range of real-world scenarios, a number of large-scale benchmark datasets have been established, on which considerable methods have been developed and demonstrated with significant progress in recent years -- predominantly by recent deep learning (DL)-based methods. This survey aims to systematically investigate the current DL-based visual tracking methods, benchmark datasets, and evaluation metrics. It also extensively evaluates and analyzes the leading visual tracking methods. First, the fundamental characteristics, primary motivations, and contributions of DL-based methods are summarized from six key aspects of: network architecture, network exploitation, network training for visual tracking, network objective, network output, and the exploitation of correlation filter advantages. Second, popular visual tracking benchmarks and their respective properties are compared, and their evaluation metrics are summarized. Third, the state-of-the-art DL-based methods are comprehensively examined on a set of well-established benchmarks of OTB2013, OTB2015, VOT2018, and LaSOT. Finally, by conducting critical analyses of these state-of-the-art methods both quantitatively and qualitatively, their pros and cons under various common scenarios are investigated. It may serve as a gentle use guide for practitioners to weigh on when and under what conditions to choose which method(s). It also facilitates a discussion on ongoing issues and sheds light on promising research directions.
A Novel Boundary Matching Algorithm for Video Temporal Error Concealment
Oct 25, 2016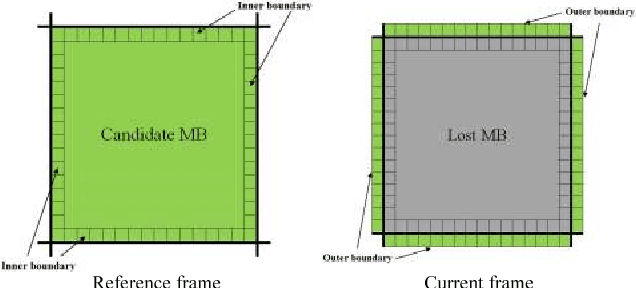
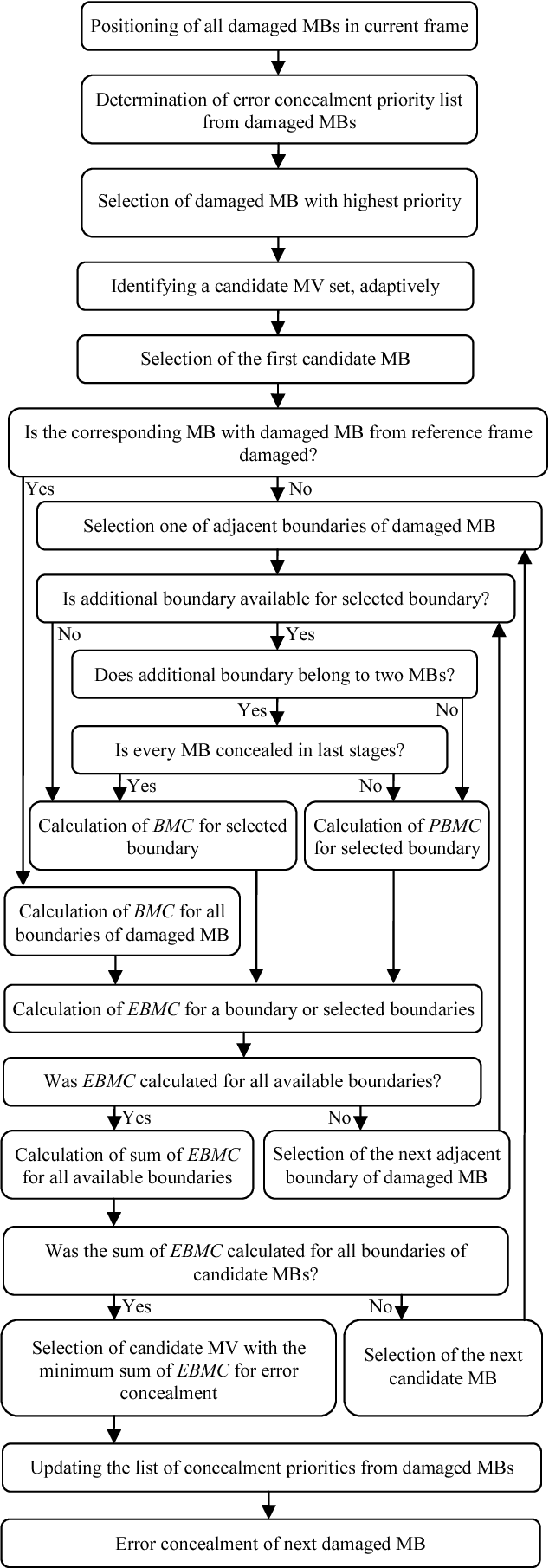

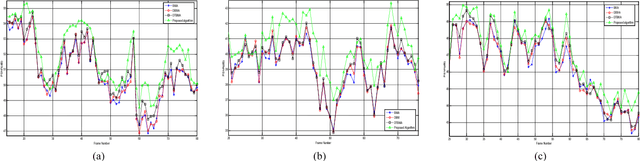
With the fast growth of communication networks, the video data transmission from these networks is extremely vulnerable. Error concealment is a technique to estimate the damaged data by employing the correctly received data at the decoder. In this paper, an efficient boundary matching algorithm for estimating damaged motion vectors (MVs) is proposed. The proposed algorithm performs error concealment for each damaged macro block (MB) according to the list of identified priority of each frame. It then uses a classic boundary matching criterion or the proposed boundary matching criterion adaptively to identify matching distortion in each boundary of candidate MB. Finally, the candidate MV with minimum distortion is selected as an MV of damaged MB and the list of priorities is updated. Experimental results show that the proposed algorithm improves both objective and subjective qualities of reconstructed frames without any significant increase in computational cost. The PSNR for test sequences in some frames is increased about 4.7, 4.5, and 4.4 dB compared to the classic boundary matching, directional boundary matching, and directional temporal boundary matching algorithm, respectively.
* arXiv admin note: text overlap with arXiv:1610.07386