 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Realtime Dynamic Background Subtraction
Mar 06, 2023



Background subtraction is a fundamental task in computer vision with numerous real-world applications, ranging from object tracking to video surveillance. Dynamic backgrounds poses a significant challenge here. Supervised deep learning-based techniques are currently considered state-of-the-art for this task. However, these methods require pixel-wise ground-truth labels, which can be time-consuming and expensive. In this work, we propose a weakly supervised framework that can perform background subtraction without requiring per-pixel ground-truth labels. Our framework is trained on a moving object-free sequence of images and comprises two networks. The first network is an autoencoder that generates background images and prepares dynamic background images for training the second network. The dynamic background images are obtained by thresholding the background-subtracted images. The second network is a U-Net that uses the same object-free video for training and the dynamic background images as pixel-wise ground-truth labels. During the test phase, the input images are processed by the autoencoder and U-Net, which generate background and dynamic background images, respectively. The dynamic background image helps remove dynamic motion from the background-subtracted image, enabling us to obtain a foreground image that is free of dynamic artifacts. To demonstrate the effectiveness of our method, we conducted experiments on selected categories of the CDnet 2014 dataset and the I2R dataset. Our method outperformed all top-ranked unsupervised methods. We also achieved better results than one of the two existing weakly supervised methods, and our performance was similar to the other. Our proposed method is online, real-time, efficient, and requires minimal frame-level annotation, making it suitable for a wide range of real-world applications.
Dynamic Background Subtraction by Generative Neural Networks
Feb 10, 2022
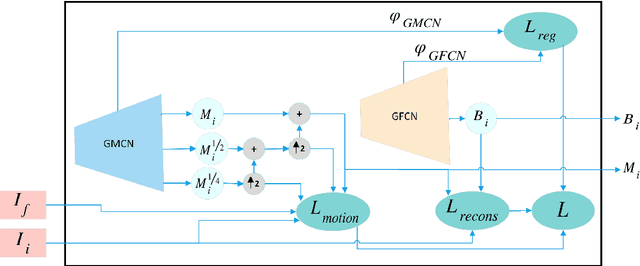


Background subtraction is a significant task in computer vision and an essential step for many real world applications. One of the challenges for background subtraction methods is dynamic background, which constitute stochastic movements in some parts of the background. In this paper, we have proposed a new background subtraction method, called DBSGen, which uses two generative neural networks, one for dynamic motion removal and another for background generation. At the end, the foreground moving objects are obtained by a pixel-wise distance threshold based on a dynamic entropy map. The proposed method has a unified framework that can be optimized in an end-to-end and unsupervised fashion. The performance of the method is evaluated over dynamic background sequences and it outperforms most of state-of-the-art methods. Our code is publicly available at https://github.com/FatemeBahri/DBSGen.
Online Illumination Invariant Moving Object Detection by Generative Neural Network
Aug 03, 2018
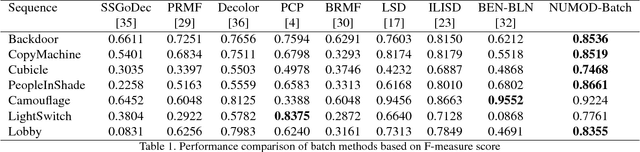

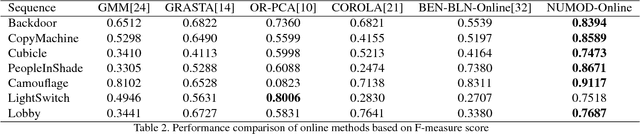
Moving object detection (MOD) is a significant problem in computer vision that has many real world applications. Different categories of methods have been proposed to solve MOD. One of the challenges is to separate moving objects from illumination changes and shadows that are present in most real world videos. State-of-the-art methods that can handle illumination changes and shadows work in a batch mode; thus, these methods are not suitable for long video sequences or real-time applications. In this paper, we propose an extension of a state-of-the-art batch MOD method (ILISD) to an online/incremental MOD using unsupervised and generative neural networks, which use illumination invariant image representations. For each image in a sequence, we use a low-dimensional representation of a background image by a neural network and then based on the illumination invariant representation, decompose the foreground image into: illumination change and moving objects. Optimization is performed by stochastic gradient descent in an end-to-end and unsupervised fashion. Our algorithm can work in both batch and online modes. In the batch mode, like other batch methods, optimizer uses all the images. In online mode, images can be incrementally fed into the optimizer. Based on our experimental evaluation on benchmark image sequences, both the online and the batch modes of our algorithm achieve state-of-the-art accuracy on most data sets.