 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHighlight Specular Reflection Separation based on Tensor Low-rank and Sparse Decomposition Using Polarimetric Cues
Jul 07, 2022
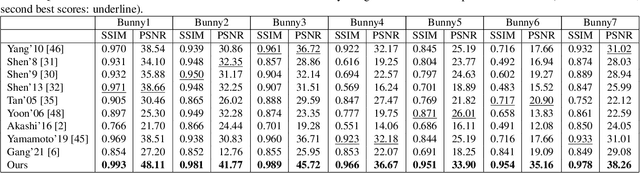
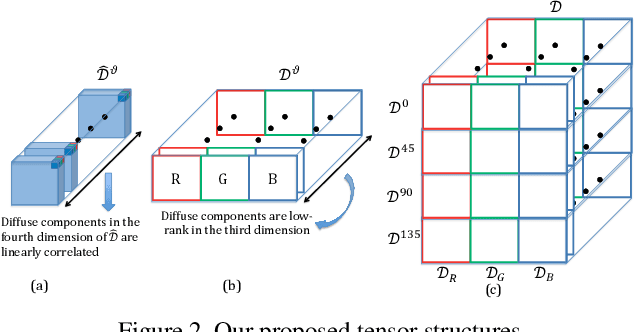
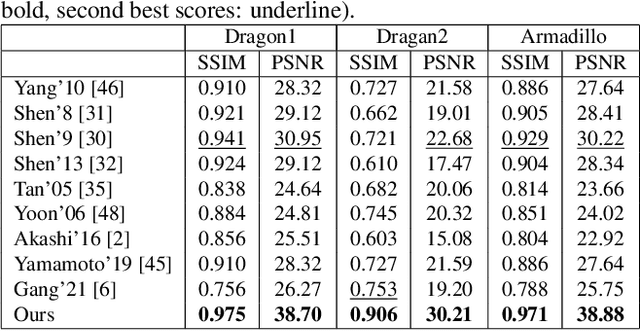
This paper is concerned with specular reflection removal based on tensor low-rank decomposition framework with the help of polarization information. Our method is motivated by the observation that the specular highlight of an image is sparsely distributed while the remaining diffuse reflection can be well approximated by a linear combination of several distinct colors using a low-rank and sparse decomposition framework. Unlike current solutions, our tensor low-rank decomposition keeps the spatial structure of specular and diffuse information which enables us to recover the diffuse image under strong specular reflection or in saturated regions. We further define and impose a new polarization regularization term as constraint on color channels. This regularization boosts the performance of the method to recover an accurate diffuse image by handling the color distortion, a common problem of chromaticity-based methods, especially in case of strong specular reflection. Through comprehensive experiments on both synthetic and real polarization images, we demonstrate that our method is able to significantly improve the accuracy of highlight specular removal, and outperform the competitive methods to recover the diffuse image, especially in regions of strong specular reflection or in saturated areas.
Deep Polarimetric HDR Reconstruction
Mar 27, 2022
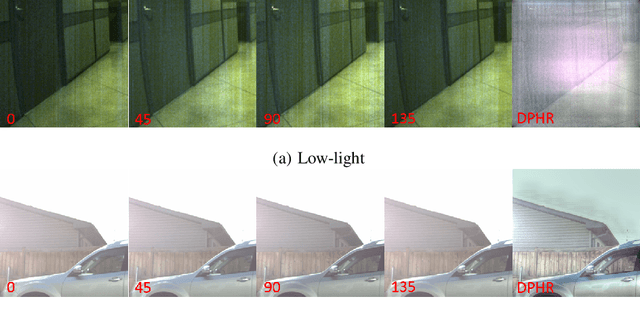
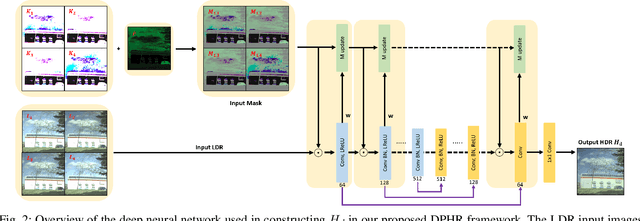
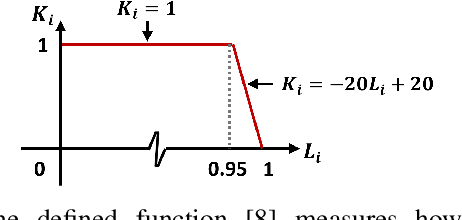
This paper proposes a novel learning based high-dynamic-range (HDR) reconstruction method using a polarization camera. We utilize a previous observation that polarization filters with different orientations can attenuate natural light differently, and we treat the multiple images acquired by the polarization camera as a set acquired under different exposure times, to introduce the development of solutions for the HDR reconstruction problem. We propose a deep HDR reconstruction framework with a feature masking mechanism that uses polarimetric cues available from the polarization camera, called Deep Polarimetric HDR Reconstruction (DPHR). The proposed DPHR obtains polarimetric information to propagate valid features through the network more effectively to regress the missing pixels. We demonstrate through both qualitative and quantitative evaluations that the proposed DPHR performs favorably than state-of-the-art HDR reconstruction algorithms.
Online Mutual Adaptation of Deep Depth Prediction and Visual SLAM
Nov 27, 2021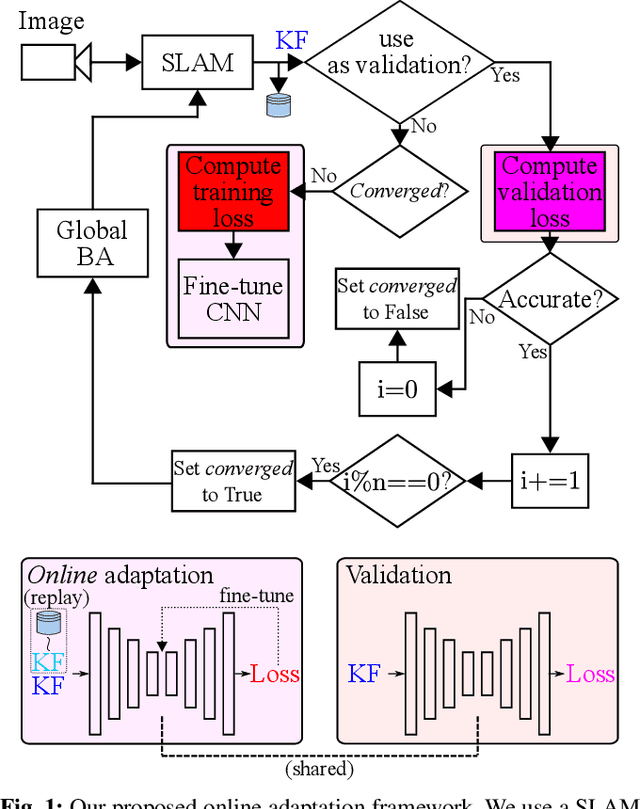
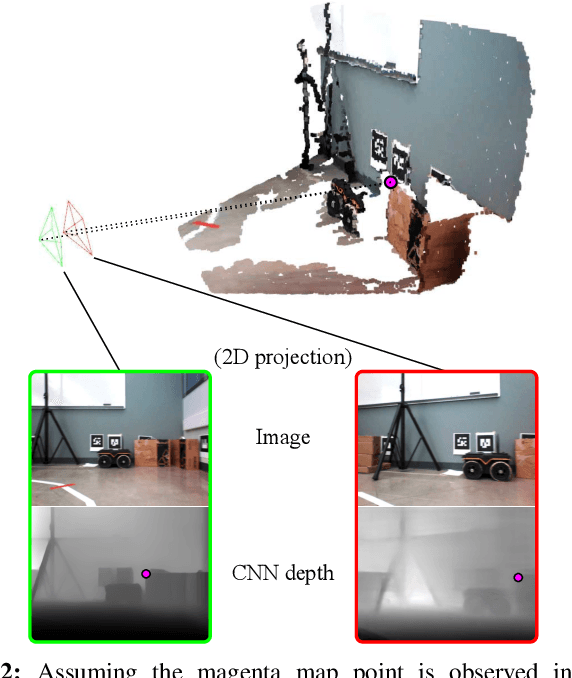


The ability of accurate depth prediction by a CNN is a major challenge for its wide use in practical visual SLAM applications, such as enhanced camera tracking and dense mapping. This paper is set out to answer the following question: Can we tune a depth prediction CNN with the help of a visual SLAM algorithm even if the CNN is not trained for the current operating environment in order to benefit the SLAM performance? To this end, we propose a novel online adaptation framework consisting of two complementary processes: a SLAM algorithm that is used to generate keyframes to fine-tune the depth prediction and another algorithm that uses the online adapted depth to improve map quality. Once the potential noisy map points are removed, we perform global photometric bundle adjustment (BA) to improve the overall SLAM performance. Experimental results on both benchmark datasets and a real robot in our own experimental environments show that our proposed method improves the overall SLAM accuracy. We demonstrate the use of regularization in the training loss as an effective means to prevent catastrophic forgetting. In addition, we compare our online adaptation framework against the state-of-the-art pre-trained depth prediction CNNs to show that our online adapted depth prediction CNN outperforms the depth prediction CNNs that have been trained on a large collection of datasets.
Polarimetric Monocular Dense Mapping Using Relative Deep Depth Prior
Feb 10, 2021



This paper is concerned with polarimetric dense map reconstruction based on a polarization camera with the help of relative depth information as a prior. In general, polarization imaging is able to reveal information about surface normal such as azimuth and zenith angles, which can support the development of solutions to the problem of dense reconstruction, especially in texture-poor regions. However, polarimetric shape cues are ambiguous due to two types of polarized reflection (specular/diffuse). Although methods have been proposed to address this issue, they either are offline and therefore not practical in robotics applications, or use incomplete polarimetric cues, leading to sub-optimal performance. In this paper, we propose an online reconstruction method that uses full polarimetric cues available from the polarization camera. With our online method, we can propagate sparse depth values both along and perpendicular to iso-depth contours. Through comprehensive experiments on challenging image sequences, we demonstrate that our method is able to significantly improve the accuracy of the depthmap as well as increase its density, specially in regions of poor texture.
Moving Object Detection under Discontinuous Change in Illumination Using Tensor Low-Rank and Invariant Sparse Decomposition
Apr 08, 2019
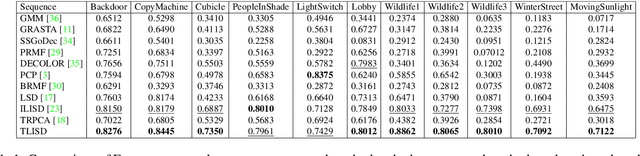

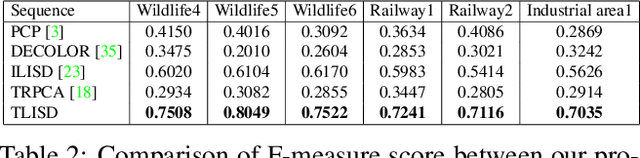
Although low-rank and sparse decomposition based methods have been successfully applied to the problem of moving object detection using structured sparsity-inducing norms, they are still vulnerable to significant illumination changes that arise in certain applications. We are interested in moving object detection in applications involving time-lapse image sequences for which current methods mistakenly group moving objects and illumination changes into foreground. Our method relies on the multilinear (tensor) data low-rank and sparse decomposition framework to address the weaknesses of existing methods. The key to our proposed method is to create first a set of prior maps that can characterize the changes in the image sequence due to illumination. We show that they can be detected by a k-support norm. To deal with concurrent, two types of changes, we employ two regularization terms, one for detecting moving objects and the other for accounting for illumination changes, in the tensor low-rank and sparse decomposition formulation. Through comprehensive experiments using challenging datasets, we show that our method demonstrates a remarkable ability to detect moving objects under discontinuous change in illumination, and outperforms the state-of-the-art solutions to this challenging problem.
Online Illumination Invariant Moving Object Detection by Generative Neural Network
Aug 03, 2018
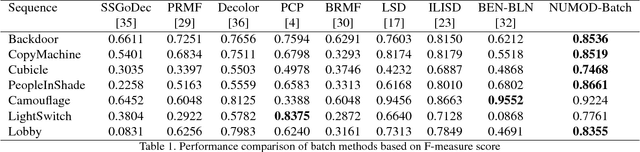

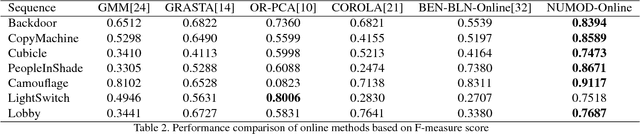
Moving object detection (MOD) is a significant problem in computer vision that has many real world applications. Different categories of methods have been proposed to solve MOD. One of the challenges is to separate moving objects from illumination changes and shadows that are present in most real world videos. State-of-the-art methods that can handle illumination changes and shadows work in a batch mode; thus, these methods are not suitable for long video sequences or real-time applications. In this paper, we propose an extension of a state-of-the-art batch MOD method (ILISD) to an online/incremental MOD using unsupervised and generative neural networks, which use illumination invariant image representations. For each image in a sequence, we use a low-dimensional representation of a background image by a neural network and then based on the illumination invariant representation, decompose the foreground image into: illumination change and moving objects. Optimization is performed by stochastic gradient descent in an end-to-end and unsupervised fashion. Our algorithm can work in both batch and online modes. In the batch mode, like other batch methods, optimizer uses all the images. In online mode, images can be incrementally fed into the optimizer. Based on our experimental evaluation on benchmark image sequences, both the online and the batch modes of our algorithm achieve state-of-the-art accuracy on most data sets.
Fast Shadow Detection from a Single Image Using a Patched Convolutional Neural Network
Mar 16, 2018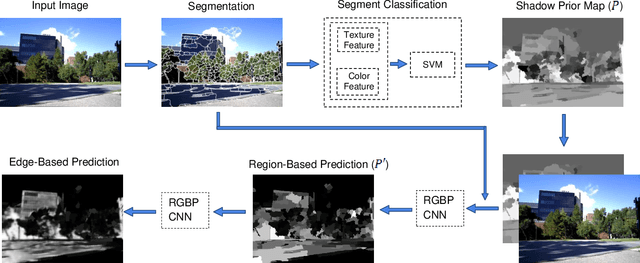



In recent years, various shadow detection methods from a single image have been proposed and used in vision systems; however, most of them are not appropriate for the robotic applications due to the expensive time complexity. This paper introduces a fast shadow detection method using a deep learning framework, with a time cost that is appropriate for robotic applications. In our solution, we first obtain a shadow prior map with the help of multi-class support vector machine using statistical features. Then, we use a semantic- aware patch-level Convolutional Neural Network that efficiently trains on shadow examples by combining the original image and the shadow prior map. Experiments on benchmark datasets demonstrate the proposed method significantly decreases the time complexity of shadow detection, by one or two orders of magnitude compared with state-of-the-art methods, without losing accuracy.
Face Recognition using Multi-Modal Low-Rank Dictionary Learning
Mar 15, 2017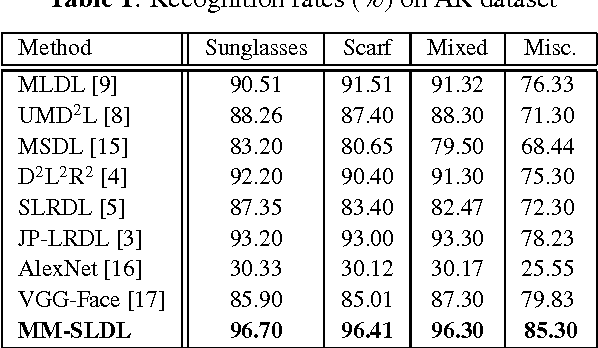

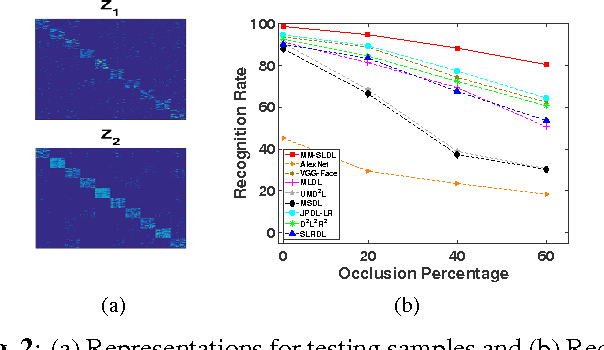
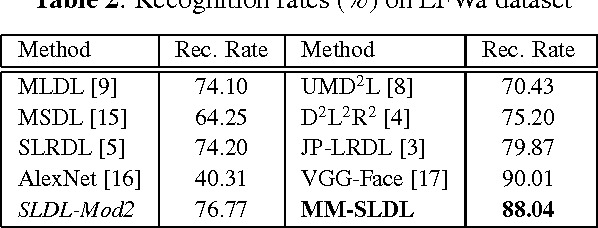
Face recognition has been widely studied due to its importance in different applications; however, most of the proposed methods fail when face images are occluded or captured under illumination and pose variations. Recently several low-rank dictionary learning methods have been proposed and achieved promising results for noisy observations. While these methods are mostly developed for single-modality scenarios, recent studies demonstrated the advantages of feature fusion from multiple inputs. We propose a multi-modal structured low-rank dictionary learning method for robust face recognition, using raw pixels of face images and their illumination invariant representation. The proposed method learns robust and discriminative representations from contaminated face images, even if there are few training samples with large intra-class variations. Extensive experiments on different datasets validate the superior performance and robustness of our method to severe illumination variations and occlusion.
COROLA: A Sequential Solution to Moving Object Detection Using Low-rank Approximation
Jan 28, 2016
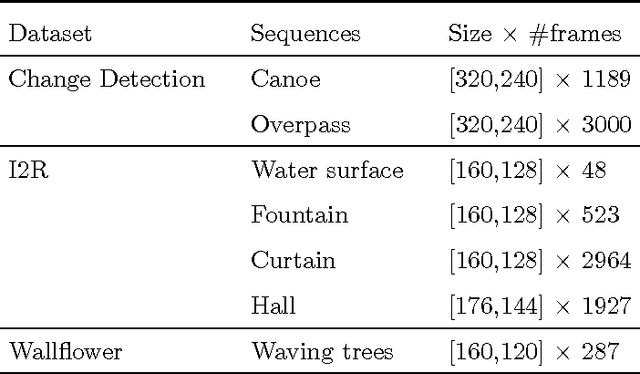

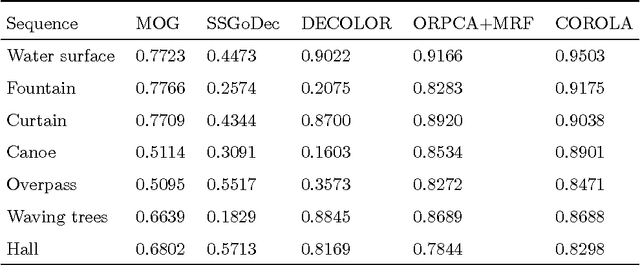
Extracting moving objects from a video sequence and estimating the background of each individual image are fundamental issues in many practical applications such as visual surveillance, intelligent vehicle navigation, and traffic monitoring. Recently, some methods have been proposed to detect moving objects in a video via low-rank approximation and sparse outliers where the background is modeled with the computed low-rank component of the video and the foreground objects are detected as the sparse outliers in the low-rank approximation. All of these existing methods work in a batch manner, preventing them from being applied in real time and long duration tasks. In this paper, we present an online sequential framework, namely contiguous outliers representation via online low-rank approximation (COROLA), to detect moving objects and learn the background model at the same time. We also show that our model can detect moving objects with a moving camera. Our experimental evaluation uses simulated data and real public datasets and demonstrates the superior performance of COROLA in terms of both accuracy and execution time.