 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Mutual Adaptation of Deep Depth Prediction and Visual SLAM
Nov 27, 2021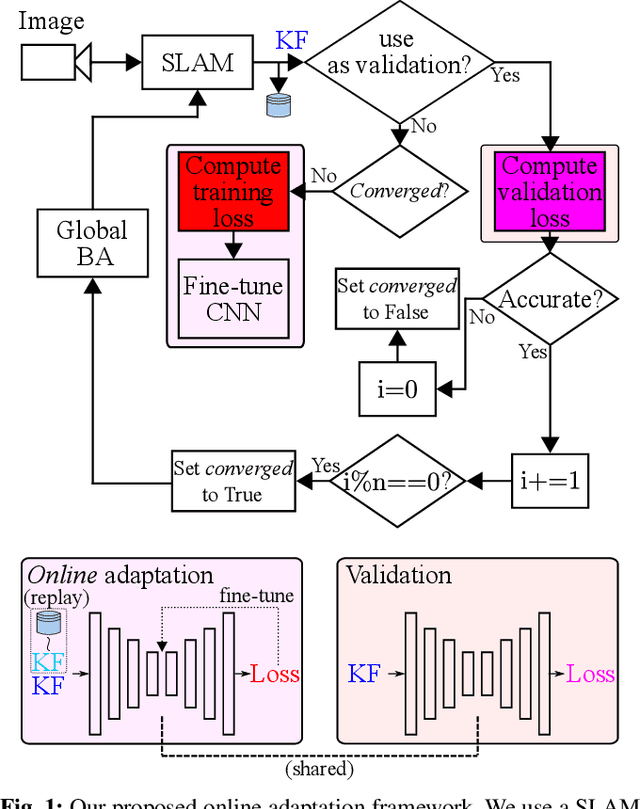
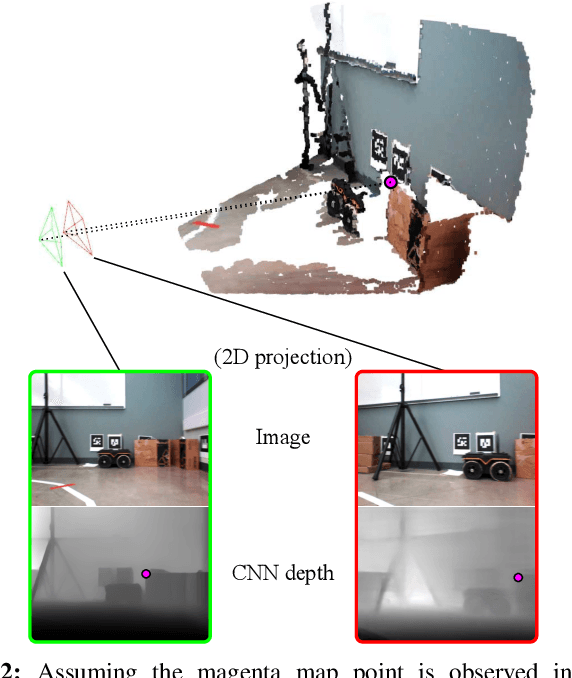


The ability of accurate depth prediction by a CNN is a major challenge for its wide use in practical visual SLAM applications, such as enhanced camera tracking and dense mapping. This paper is set out to answer the following question: Can we tune a depth prediction CNN with the help of a visual SLAM algorithm even if the CNN is not trained for the current operating environment in order to benefit the SLAM performance? To this end, we propose a novel online adaptation framework consisting of two complementary processes: a SLAM algorithm that is used to generate keyframes to fine-tune the depth prediction and another algorithm that uses the online adapted depth to improve map quality. Once the potential noisy map points are removed, we perform global photometric bundle adjustment (BA) to improve the overall SLAM performance. Experimental results on both benchmark datasets and a real robot in our own experimental environments show that our proposed method improves the overall SLAM accuracy. We demonstrate the use of regularization in the training loss as an effective means to prevent catastrophic forgetting. In addition, we compare our online adaptation framework against the state-of-the-art pre-trained depth prediction CNNs to show that our online adapted depth prediction CNN outperforms the depth prediction CNNs that have been trained on a large collection of datasets.
DeepRelativeFusion: Dense Monocular SLAM using Single-Image Relative Depth Prediction
Jun 07, 2020
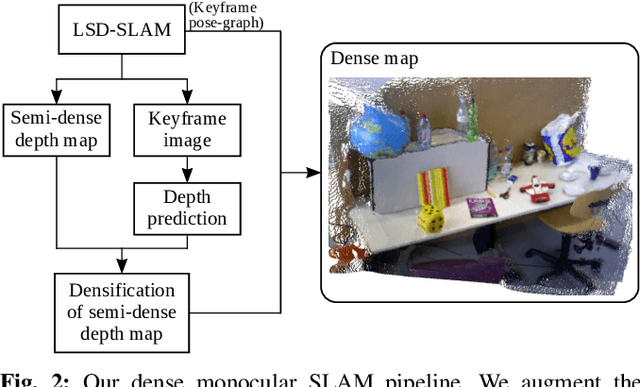
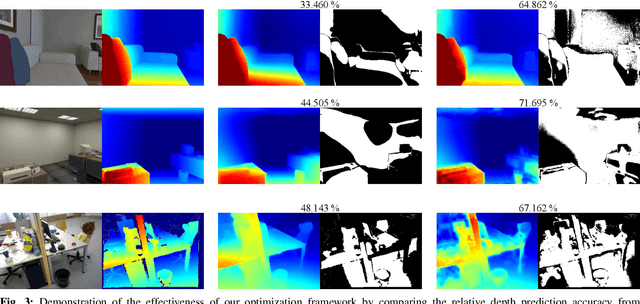

Traditional monocular visual simultaneous localization and mapping (SLAM) algorithms have been extensively studied and proven to reliably recover a sparse structure and camera motion. Nevertheless, the sparse structure is still insufficient for scene interaction, e.g., visual navigation and augmented reality applications. To densify the scene reconstruction, the use of single-image absolute depth prediction from convolutional neural networks (CNNs) for filling in the missing structure has been proposed. However, the prediction accuracy tends to not generalize well on scenes that are different from the training datasets. In this paper, we propose a dense monocular SLAM system, named DeepRelativeFusion, that is capable to recover a globally consistent 3D structure. To this end, we use a visual SLAM algorithm to reliably recover the camera poses and semi-dense depth maps of the keyframes, and then combine the keyframe pose-graph with the densified keyframe depth maps to reconstruct the scene. To perform the densification, we introduce two incremental improvements upon the energy minimization framework proposed by DeepFusion: (1) an additional image gradient term in the cost function, and (2) the use of single-image relative depth prediction. Despite the absence of absolute scale and depth range, the relative depth maps can be corrected using their respective semi-dense depth maps from the SLAM algorithm. We show that the corrected relative depth maps are sufficiently accurate to be used as priors for the densification. To demonstrate the generalizability of relative depth prediction, we illustrate qualitatively the dense reconstruction on two outdoor sequences. Our system also outperforms the state-of-the-art dense SLAM systems quantitatively in dense reconstruction accuracy by a large margin.
CNN-SVO: Improving the Mapping in Semi-Direct Visual Odometry Using Single-Image Depth Prediction
Oct 01, 2018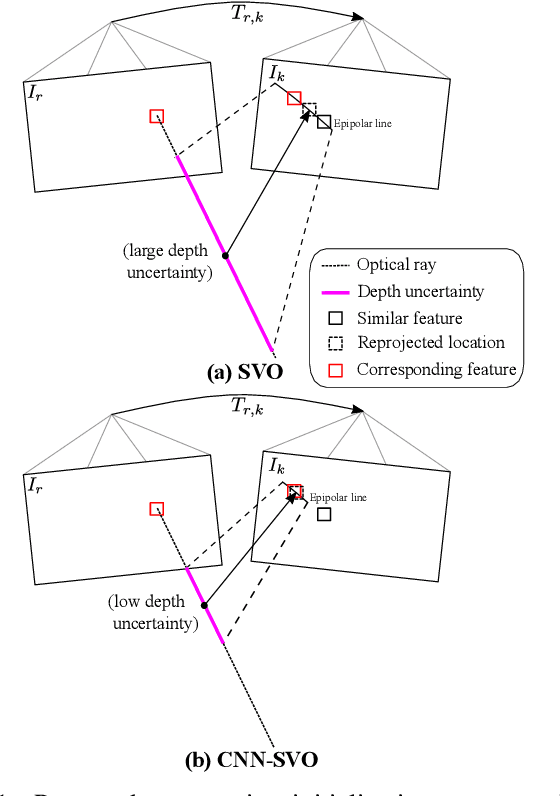
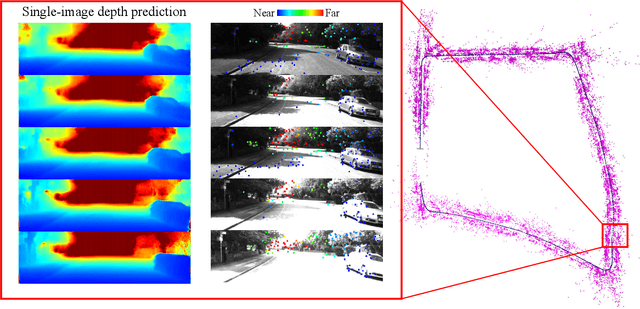
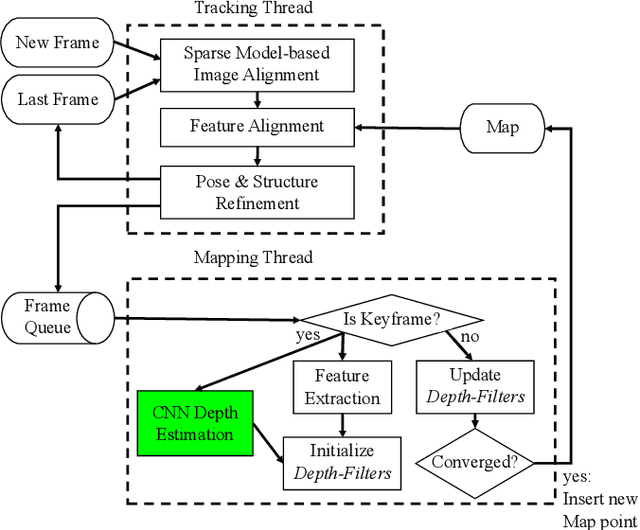
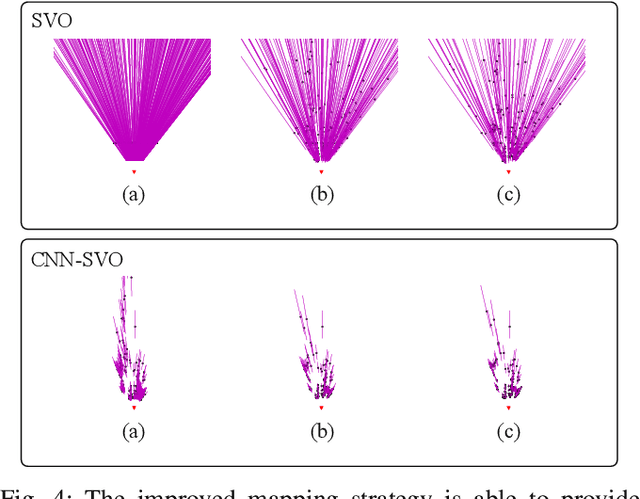
Reliable feature correspondence between frames is a critical step in visual odometry (VO) and visual simultaneous localization and mapping (V-SLAM) algorithms. In comparison with existing VO and V-SLAM algorithms, semi-direct visual odometry (SVO) has two main advantages that lead to state-of-the-art frame rate camera motion estimation: direct pixel correspondence and efficient implementation of probabilistic mapping method. This paper improves the SVO mapping by initializing the mean and the variance of the depth at a feature location according to the depth prediction from a single-image depth prediction network. By significantly reducing the depth uncertainty of the initialized map point (i.e., small variance centred about the depth prediction), the benefits are twofold: reliable feature correspondence between views and fast convergence to the true depth in order to create new map points. We evaluate our method with two outdoor datasets: KITTI dataset and Oxford Robotcar dataset. The experimental results indicate that the improved SVO mapping results in increased robustness and camera tracking accuracy.