 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepRelativeFusion: Dense Monocular SLAM using Single-Image Relative Depth Prediction
Paper and Code

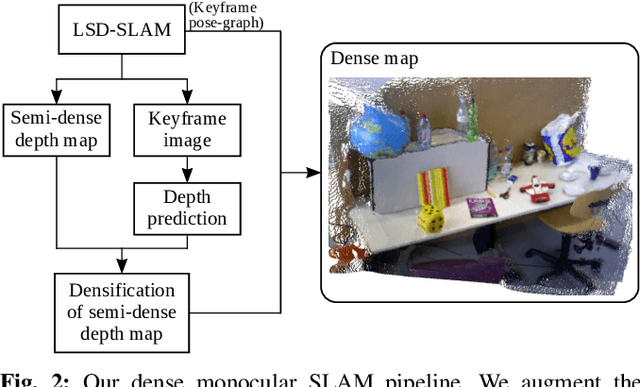
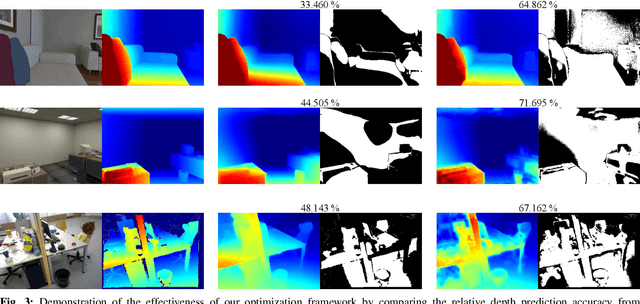

Traditional monocular visual simultaneous localization and mapping (SLAM) algorithms have been extensively studied and proven to reliably recover a sparse structure and camera motion. Nevertheless, the sparse structure is still insufficient for scene interaction, e.g., visual navigation and augmented reality applications. To densify the scene reconstruction, the use of single-image absolute depth prediction from convolutional neural networks (CNNs) for filling in the missing structure has been proposed. However, the prediction accuracy tends to not generalize well on scenes that are different from the training datasets. In this paper, we propose a dense monocular SLAM system, named DeepRelativeFusion, that is capable to recover a globally consistent 3D structure. To this end, we use a visual SLAM algorithm to reliably recover the camera poses and semi-dense depth maps of the keyframes, and then combine the keyframe pose-graph with the densified keyframe depth maps to reconstruct the scene. To perform the densification, we introduce two incremental improvements upon the energy minimization framework proposed by DeepFusion: (1) an additional image gradient term in the cost function, and (2) the use of single-image relative depth prediction. Despite the absence of absolute scale and depth range, the relative depth maps can be corrected using their respective semi-dense depth maps from the SLAM algorithm. We show that the corrected relative depth maps are sufficiently accurate to be used as priors for the densification. To demonstrate the generalizability of relative depth prediction, we illustrate qualitatively the dense reconstruction on two outdoor sequences. Our system also outperforms the state-of-the-art dense SLAM systems quantitatively in dense reconstruction accuracy by a large margin.