 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Recognition using Multi-Modal Low-Rank Dictionary Learning
Paper and Code
Mar 15, 2017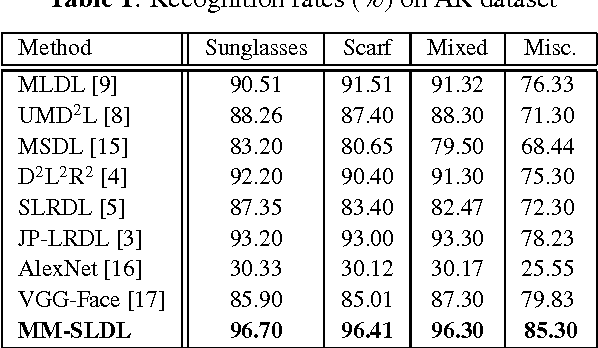

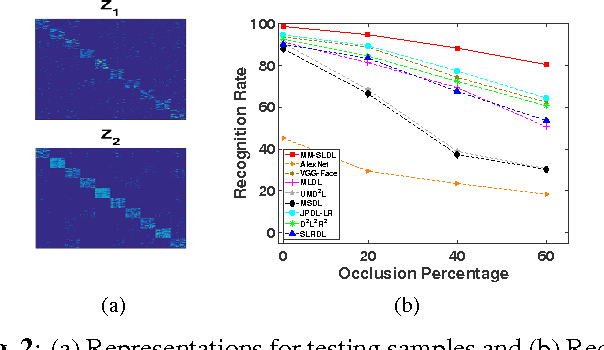
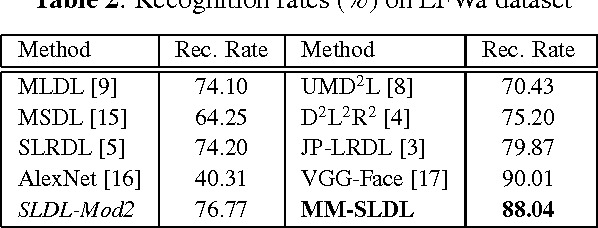
Face recognition has been widely studied due to its importance in different applications; however, most of the proposed methods fail when face images are occluded or captured under illumination and pose variations. Recently several low-rank dictionary learning methods have been proposed and achieved promising results for noisy observations. While these methods are mostly developed for single-modality scenarios, recent studies demonstrated the advantages of feature fusion from multiple inputs. We propose a multi-modal structured low-rank dictionary learning method for robust face recognition, using raw pixels of face images and their illumination invariant representation. The proposed method learns robust and discriminative representations from contaminated face images, even if there are few training samples with large intra-class variations. Extensive experiments on different datasets validate the superior performance and robustness of our method to severe illumination variations and occlusion.