 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoton Absorption Remote Sensing Virtual Histopathology: Diagnostic Equivalence to Gold-Standard H&E Staining in Skin Cancer Excisional Biopsies
Apr 25, 2025Photon Absorption Remote Sensing (PARS) enables label-free imaging of subcellular morphology by observing biomolecule specific absorption interactions. Coupled with deep-learning, PARS produces label-free virtual Hematoxylin and Eosin (H&E) stained images in unprocessed tissues. This study evaluates the diagnostic performance of these PARS-derived virtual H&E images in benign and malignant excisional skin biopsies, including Squamous (SCC), Basal (BCC) Cell Carcinoma, and normal skin. Sixteen unstained formalin-fixed paraffin-embedded skin excisions were PARS imaged, virtually H&E stained, then chemically stained and imaged at 40x. Seven fellowship trained dermatopathologists assessed all 32 images in a masked randomized fashion. Concordance analysis indicates 95.5% agreement between primary diagnoses rendered on PARS versus H&E images (Cohen's k=0.93). Inter-rater reliability was near-perfect for both image types (Fleiss' k=0.89 for PARS, k=0.80 for H&E). For subtype classification, agreement was near-perfect 91% (k=0.73) for SCC and was perfect for BCC. When assessing malignancy confinement (e.g., cancer margins), agreement was 92% between PARS and H&E (k=0.718). During assessment dermatopathologists could not reliably distinguish image origin (PARS vs. H&E), and diagnostic confidence was equivalent between the modalities. Inter-rater reliability for PARS virtual H&E was consistent with reported benchmarks for histologic evaluation. These results indicate that PARS virtual histology may be diagnostically equivalent to traditional H&E staining in dermatopathology diagnostics, while enabling assessment directly from unlabeled, or unprocessed slides. In turn, the label-free PARS virtual H&E imaging workflow may preserve tissue for downstream analysis while producing data well-suited for AI integration potentially accelerating and enhancing the accuracy of skin cancer diagnostics.
Predicting Ki67, ER, PR, and HER2 Statuses from H&E-stained Breast Cancer Images
Aug 03, 2023



Despite the advances in machine learning and digital pathology, it is not yet clear if machine learning methods can accurately predict molecular information merely from histomorphology. In a quest to answer this question, we built a large-scale dataset (185538 images) with reliable measurements for Ki67, ER, PR, and HER2 statuses. The dataset is composed of mirrored images of H\&E and corresponding images of immunohistochemistry (IHC) assays (Ki67, ER, PR, and HER2. These images are mirrored through registration. To increase reliability, individual pairs were inspected and discarded if artifacts were present (tissue folding, bubbles, etc). Measurements for Ki67, ER and PR were determined by calculating H-Score from image analysis. HER2 measurement is based on binary classification: 0 and 1+ (IHC scores representing a negative subset) vs 3+ (IHC score positive subset). Cases with IHC equivocal score (2+) were excluded. We show that a standard ViT-based pipeline can achieve prediction performances around 90% in terms of Area Under the Curve (AUC) when trained with a proper labeling protocol. Finally, we shed light on the ability of the trained classifiers to localize relevant regions, which encourages future work to improve the localizations. Our proposed dataset is publicly available: https://ihc4bc.github.io/
GPEX, A Framework For Interpreting Artificial Neural Networks
Dec 18, 2021
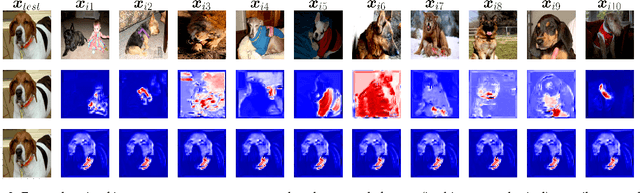
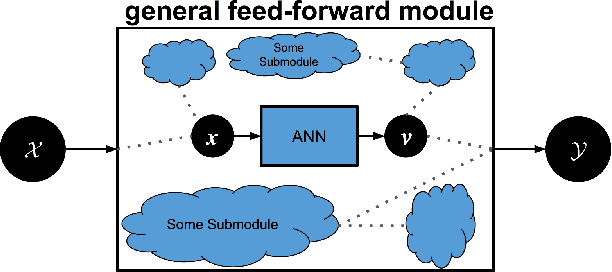
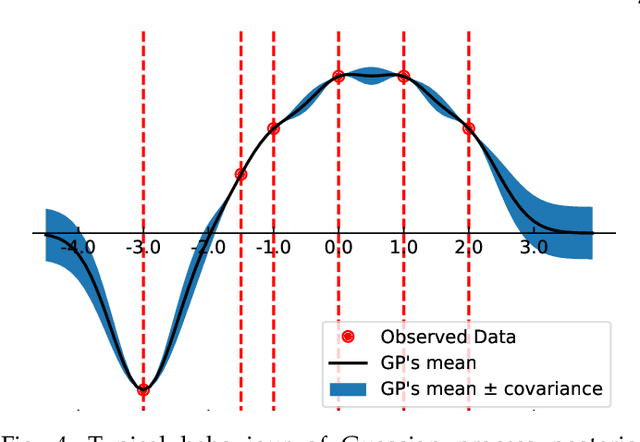
Machine learning researchers have long noted a trade-off between interpretability and prediction performance. On the one hand, traditional models are often interpretable to humans but they cannot achieve high prediction performances. At the opposite end of the spectrum, deep models can achieve state-of-the-art performances in many tasks. However, deep models' predictions are known to be uninterpretable to humans. In this paper we present a framework that shortens the gap between the two aforementioned groups of methods. Given an artificial neural network (ANN), our method finds a Gaussian process (GP) whose predictions almost match those of the ANN. As GPs are highly interpretable, we use the trained GP to explain the ANN's decisions. We use our method to explain ANNs' decisions on may datasets. The explanations provide intriguing insights about the ANNs' decisions. With the best of our knowledge, our inference formulation for GPs is the first one in which an ANN and a similarly behaving Gaussian process naturally appear. Furthermore, we examine some of the known theoretical conditions under which an ANN is interpretable by GPs. Some of those theoretical conditions are too restrictive for modern architectures. However, we hypothesize that only a subset of those theoretical conditions are sufficient. Finally, we implement our framework as a publicly available tool called GPEX. Given any pytorch feed-forward module, GPEX allows users to interpret any ANN subcomponent of the module effortlessly and without having to be involved in the inference algorithm. GPEX is publicly available online:www.github.com/Nilanjan-Ray/gpex
Training Convolutional Neural Networks and Compressed Sensing End-to-End for Microscopy Cell Detection
Oct 07, 2018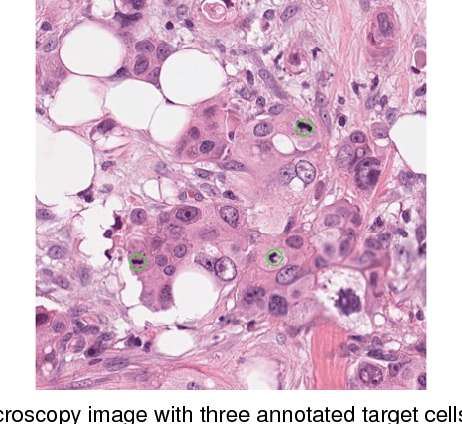

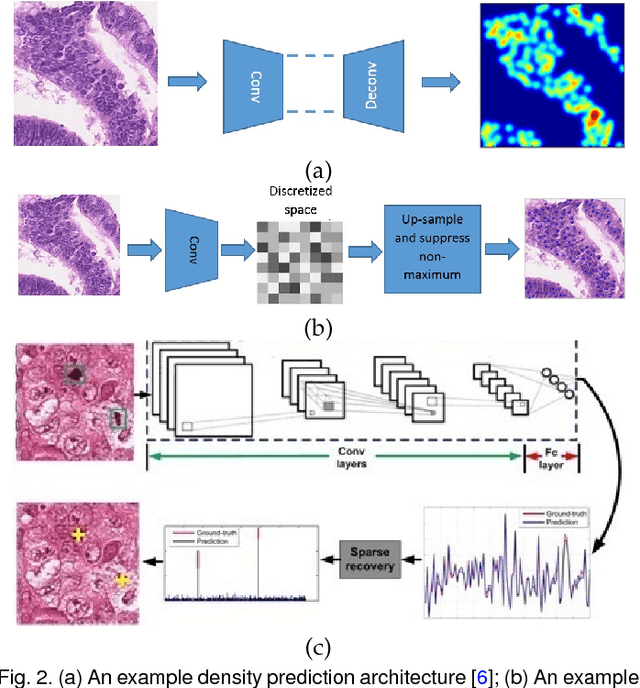

Automated cell detection and localization from microscopy images are significant tasks in biomedical research and clinical practice. In this paper, we design a new cell detection and localization algorithm that combines deep convolutional neural network (CNN) and compressed sensing (CS) or sparse coding (SC) for end-to-end training. We also derive, for the first time, a backpropagation rule, which is applicable to train any algorithm that implements a sparse code recovery layer. The key observation behind our algorithm is that cell detection task is a point object detection task in computer vision, where the cell centers (i.e., point objects) occupy only a tiny fraction of the total number of pixels in an image. Thus, we can apply compressed sensing (or, equivalently sparse coding) to compactly represent a variable number of cells in a projected space. Then, CNN regresses this compressed vector from the input microscopy image. Thanks to the SC/CS recovery algorithm (L1 optimization) that can recover sparse cell locations from the output of CNN. We train this entire processing pipeline end-to-end and demonstrate that end-to-end training provides accuracy improvements over a training paradigm that treats CNN and CS-recovery layers separately. Our algorithm design also takes into account a form of ensemble average of trained models naturally to further boost accuracy of cell detection. We have validated our algorithm on benchmark datasets and achieved excellent performances.