 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Influence of Information Entropy Change in Learning Systems
Sep 19, 2023



In this work, we explore the influence of entropy change in deep learning systems by adding noise to the inputs/latent features. The applications in this paper focus on deep learning tasks within computer vision, but the proposed theory can be further applied to other fields. Noise is conventionally viewed as a harmful perturbation in various deep learning architectures, such as convolutional neural networks (CNNs) and vision transformers (ViTs), as well as different learning tasks like image classification and transfer learning. However, this paper aims to rethink whether the conventional proposition always holds. We demonstrate that specific noise can boost the performance of various deep architectures under certain conditions. We theoretically prove the enhancement gained from positive noise by reducing the task complexity defined by information entropy and experimentally show the significant performance gain in large image datasets, such as the ImageNet. Herein, we use the information entropy to define the complexity of the task. We categorize the noise into two types, positive noise (PN) and harmful noise (HN), based on whether the noise can help reduce the complexity of the task. Extensive experiments of CNNs and ViTs have shown performance improvements by proactively injecting positive noise, where we achieved an unprecedented top 1 accuracy of over 95% on ImageNet. Both theoretical analysis and empirical evidence have confirmed that the presence of positive noise can benefit the learning process, while the traditionally perceived harmful noise indeed impairs deep learning models. The different roles of noise offer new explanations for deep models on specific tasks and provide a new paradigm for improving model performance. Moreover, it reminds us that we can influence the performance of learning systems via information entropy change.
Crowd Scene Analysis by Output Encoding
Jan 27, 2020
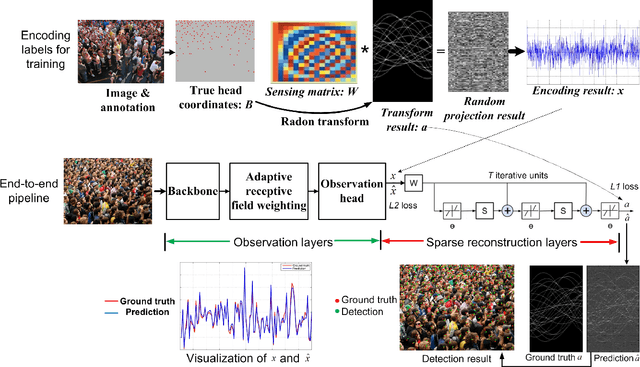
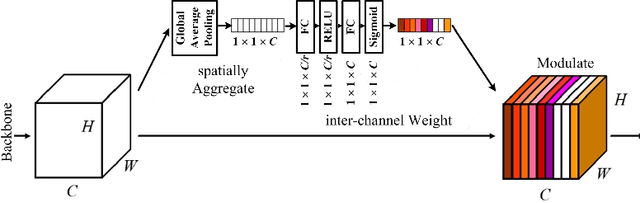

Crowd scene analysis receives growing attention due to its wide applications. Grasping the accurate crowd location (rather than merely crowd count) is important for spatially identifying high-risk regions in congested scenes. In this paper, we propose a Compressed Sensing based Output Encoding (CSOE) scheme, which casts detecting pixel coordinates of small objects into a task of signal regression in encoding signal space. CSOE helps to boost localization performance in circumstances where targets are highly crowded without huge scale variation. In addition, proper receptive field sizes are crucial for crowd analysis due to human size variations. We create Multiple Dilated Convolution Branches (MDCB) that offers a set of different receptive field sizes, to improve localization accuracy when objects sizes change drastically in an image. Also, we develop an Adaptive Receptive Field Weighting (ARFW) module, which further deals with scale variation issue by adaptively emphasizing informative channels that have proper receptive field size. Experiments demonstrate the effectiveness of the proposed method, which achieves state-of-the-art performance across four mainstream datasets, especially achieves excellent results in highly crowded scenes. More importantly, experiments support our insights that it is crucial to tackle target size variation issue in crowd analysis task, and casting crowd localization as regression in encoding signal space is quite effective for crowd analysis.
Training Convolutional Neural Networks and Compressed Sensing End-to-End for Microscopy Cell Detection
Oct 07, 2018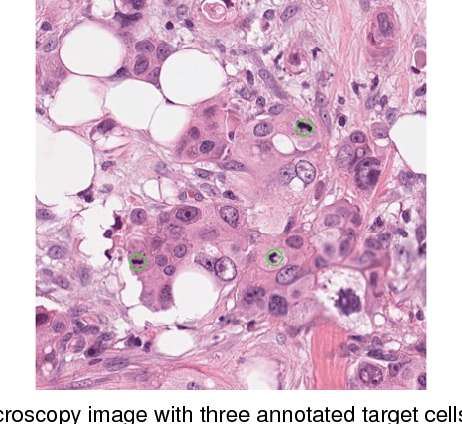

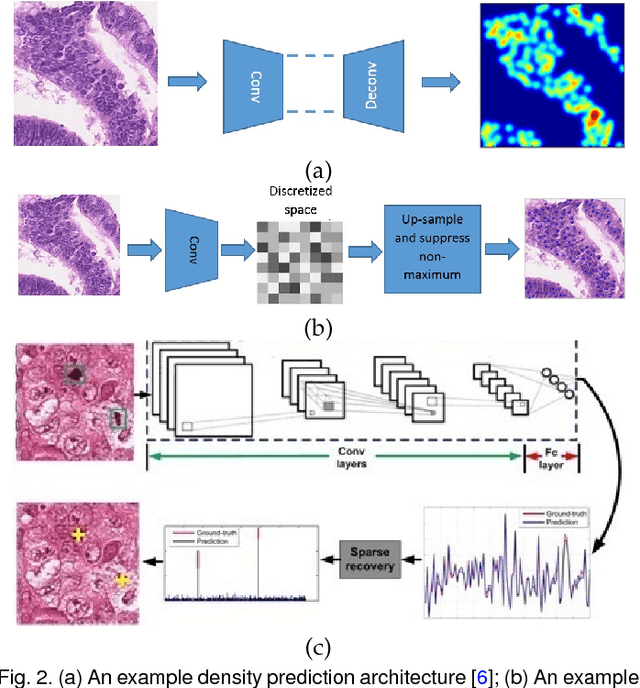

Automated cell detection and localization from microscopy images are significant tasks in biomedical research and clinical practice. In this paper, we design a new cell detection and localization algorithm that combines deep convolutional neural network (CNN) and compressed sensing (CS) or sparse coding (SC) for end-to-end training. We also derive, for the first time, a backpropagation rule, which is applicable to train any algorithm that implements a sparse code recovery layer. The key observation behind our algorithm is that cell detection task is a point object detection task in computer vision, where the cell centers (i.e., point objects) occupy only a tiny fraction of the total number of pixels in an image. Thus, we can apply compressed sensing (or, equivalently sparse coding) to compactly represent a variable number of cells in a projected space. Then, CNN regresses this compressed vector from the input microscopy image. Thanks to the SC/CS recovery algorithm (L1 optimization) that can recover sparse cell locations from the output of CNN. We train this entire processing pipeline end-to-end and demonstrate that end-to-end training provides accuracy improvements over a training paradigm that treats CNN and CS-recovery layers separately. Our algorithm design also takes into account a form of ensemble average of trained models naturally to further boost accuracy of cell detection. We have validated our algorithm on benchmark datasets and achieved excellent performances.
Cell Detection in Microscopy Images with Deep Convolutional Neural Network and Compressed Sensing
Feb 21, 2018
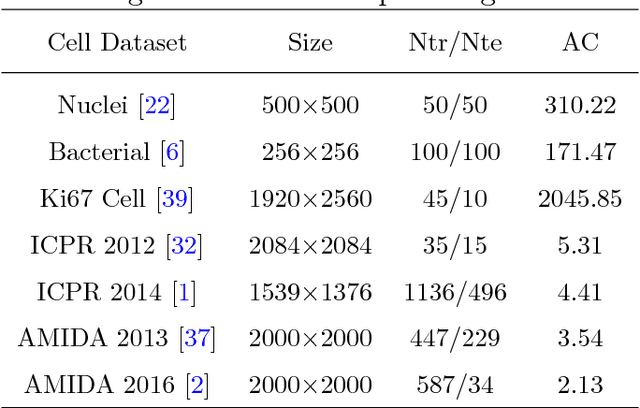


The ability to automatically detect certain types of cells or cellular subunits in microscopy images is of significant interest to a wide range of biomedical research and clinical practices. Cell detection methods have evolved from employing hand-crafted features to deep learning-based techniques. The essential idea of these methods is that their cell classifiers or detectors are trained in the pixel space, where the locations of target cells are labeled. In this paper, we seek a different route and propose a convolutional neural network (CNN)-based cell detection method that uses encoding of the output pixel space. For the cell detection problem, the output space is the sparsely labeled pixel locations indicating cell centers. We employ random projections to encode the output space to a compressed vector of fixed dimension. Then, CNN regresses this compressed vector from the input pixels. Furthermore, it is possible to stably recover sparse cell locations on the output pixel space from the predicted compressed vector using $L_1$-norm optimization. In the past, output space encoding using compressed sensing (CS) has been used in conjunction with linear and non-linear predictors. To the best of our knowledge, this is the first successful use of CNN with CS-based output space encoding. We made substantial experiments on several benchmark datasets, where the proposed CNN + CS framework (referred to as CNNCS) achieved the highest or at least top-3 performance in terms of F1-score, compared with other state-of-the-art methods.