 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedSAM-based lung masking for multi-label chest X-ray classification
Dec 28, 2025Chest X-ray (CXR) imaging is widely used for screening and diagnosing pulmonary abnormalities, yet automated interpretation remains challenging due to weak disease signals, dataset bias, and limited spatial supervision. Foundation models for medical image segmentation (MedSAM) provide an opportunity to introduce anatomically grounded priors that may improve robustness and interpretability in CXR analysis. We propose a segmentation-guided CXR classification pipeline that integrates MedSAM as a lung region extraction module prior to multi-label abnormality classification. MedSAM is fine-tuned using a public image-mask dataset from Airlangga University Hospital. We then apply it to a curated subset of the public NIH CXR dataset to train and evaluate deep convolutional neural networks for multi-label prediction of five abnormalities (Mass, Nodule, Pneumonia, Edema, and Fibrosis), with the normal case (No Finding) evaluated via a derived score. Experiments show that MedSAM produces anatomically plausible lung masks across diverse imaging conditions. We find that masking effects are both task-dependent and architecture-dependent. ResNet50 trained on original images achieves the strongest overall abnormality discrimination, while loose lung masking yields comparable macro AUROC but significantly improves No Finding discrimination, indicating a trade-off between abnormality-specific classification and normal case screening. Tight masking consistently reduces abnormality level performance but improves training efficiency. Loose masking partially mitigates this degradation by preserving perihilar and peripheral context. These results suggest that lung masking should be treated as a controllable spatial prior selected to match the backbone and clinical objective, rather than applied uniformly.
EduBench: A Comprehensive Benchmarking Dataset for Evaluating Large Language Models in Diverse Educational Scenarios
May 22, 2025As large language models continue to advance, their application in educational contexts remains underexplored and under-optimized. In this paper, we address this gap by introducing the first diverse benchmark tailored for educational scenarios, incorporating synthetic data containing 9 major scenarios and over 4,000 distinct educational contexts. To enable comprehensive assessment, we propose a set of multi-dimensional evaluation metrics that cover 12 critical aspects relevant to both teachers and students. We further apply human annotation to ensure the effectiveness of the model-generated evaluation responses. Additionally, we succeed to train a relatively small-scale model on our constructed dataset and demonstrate that it can achieve performance comparable to state-of-the-art large models (e.g., Deepseek V3, Qwen Max) on the test set. Overall, this work provides a practical foundation for the development and evaluation of education-oriented language models. Code and data are released at https://github.com/ybai-nlp/EduBench.
Enabling Multi-Agent Transfer Reinforcement Learning via Scenario Independent Representation
Feb 13, 2024



Multi-Agent Reinforcement Learning (MARL) algorithms are widely adopted in tackling complex tasks that require collaboration and competition among agents in dynamic Multi-Agent Systems (MAS). However, learning such tasks from scratch is arduous and may not always be feasible, particularly for MASs with a large number of interactive agents due to the extensive sample complexity. Therefore, reusing knowledge gained from past experiences or other agents could efficiently accelerate the learning process and upscale MARL algorithms. In this study, we introduce a novel framework that enables transfer learning for MARL through unifying various state spaces into fixed-size inputs that allow one unified deep-learning policy viable in different scenarios within a MAS. We evaluated our approach in a range of scenarios within the StarCraft Multi-Agent Challenge (SMAC) environment, and the findings show significant enhancements in multi-agent learning performance using maneuvering skills learned from other scenarios compared to agents learning from scratch. Furthermore, we adopted Curriculum Transfer Learning (CTL), enabling our deep learning policy to progressively acquire knowledge and skills across pre-designed homogeneous learning scenarios organized by difficulty levels. This process promotes inter- and intra-agent knowledge transfer, leading to high multi-agent learning performance in more complicated heterogeneous scenarios.
MAIDCRL: Semi-centralized Multi-Agent Influence Dense-CNN Reinforcement Learning
Feb 12, 2024



Distributed decision-making in multi-agent systems presents difficult challenges for interactive behavior learning in both cooperative and competitive systems. To mitigate this complexity, MAIDRL presents a semi-centralized Dense Reinforcement Learning algorithm enhanced by agent influence maps (AIMs), for learning effective multi-agent control on StarCraft Multi-Agent Challenge (SMAC) scenarios. In this paper, we extend the DenseNet in MAIDRL and introduce semi-centralized Multi-Agent Dense-CNN Reinforcement Learning, MAIDCRL, by incorporating convolutional layers into the deep model architecture, and evaluate the performance on both homogeneous and heterogeneous scenarios. The results show that the CNN-enabled MAIDCRL significantly improved the learning performance and achieved a faster learning rate compared to the existing MAIDRL, especially on more complicated heterogeneous SMAC scenarios. We further investigate the stability and robustness of our model. The statistics reflect that our model not only achieves higher winning rate in all the given scenarios but also boosts the agent's learning process in fine-grained decision-making.
Crowd Scene Analysis by Output Encoding
Jan 27, 2020
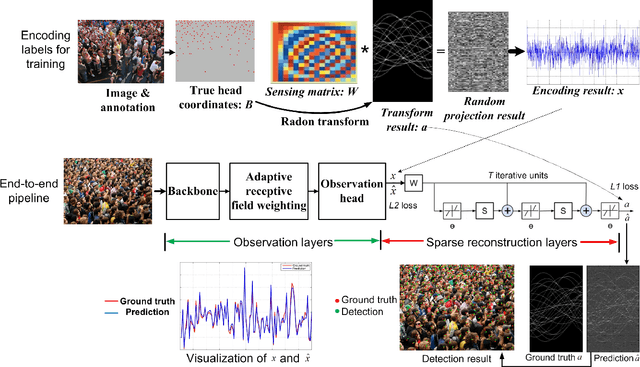
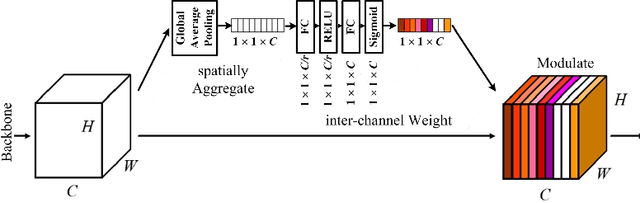

Crowd scene analysis receives growing attention due to its wide applications. Grasping the accurate crowd location (rather than merely crowd count) is important for spatially identifying high-risk regions in congested scenes. In this paper, we propose a Compressed Sensing based Output Encoding (CSOE) scheme, which casts detecting pixel coordinates of small objects into a task of signal regression in encoding signal space. CSOE helps to boost localization performance in circumstances where targets are highly crowded without huge scale variation. In addition, proper receptive field sizes are crucial for crowd analysis due to human size variations. We create Multiple Dilated Convolution Branches (MDCB) that offers a set of different receptive field sizes, to improve localization accuracy when objects sizes change drastically in an image. Also, we develop an Adaptive Receptive Field Weighting (ARFW) module, which further deals with scale variation issue by adaptively emphasizing informative channels that have proper receptive field size. Experiments demonstrate the effectiveness of the proposed method, which achieves state-of-the-art performance across four mainstream datasets, especially achieves excellent results in highly crowded scenes. More importantly, experiments support our insights that it is crucial to tackle target size variation issue in crowd analysis task, and casting crowd localization as regression in encoding signal space is quite effective for crowd analysis.
Evolutionary Multi-objective Optimization of Real-Time Strategy Micro
Mar 27, 2018
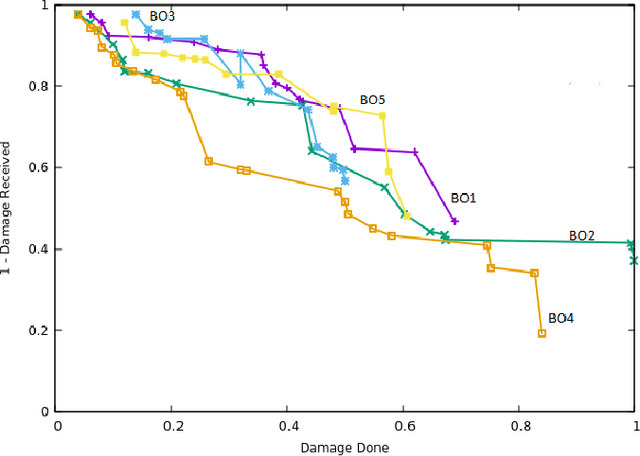
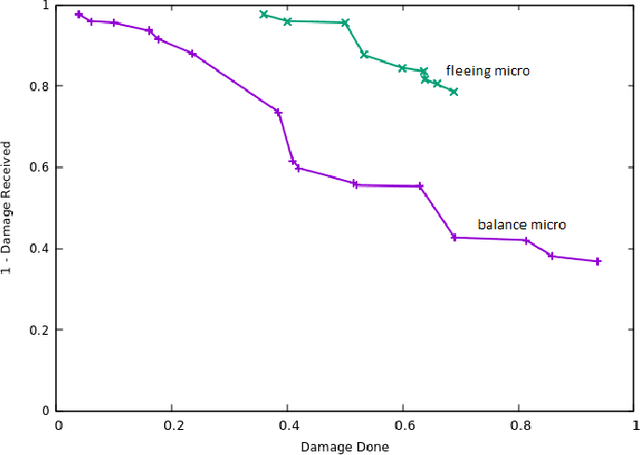
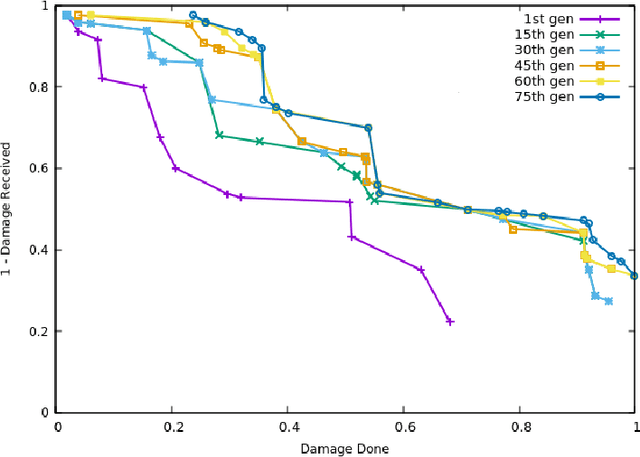
We investigate an evolutionary multi-objective approach to good micro for real-time strategy games. Good micro helps a player win skirmishes and is one of the keys to developing better real-time strategy game play. In prior work, the same multi-objective approach of maximizing damage done while minimizing damage received was used to evolve micro for a group of ranged units versus a group of melee units. We extend this work to consider groups composed from two types of units. Specifically, this paper uses evolutionary multi-objective optimization to generate micro for one group composed from both ranged and melee units versus another group of ranged and melee units. Our micro behavior representation uses influence maps to represent enemy spatial information and potential fields generated from distance, health, and weapons cool down to guide unit movement. Experimental results indicate that our multi-objective approach leads to a Pareto front of diverse high-quality micro encapsulating multiple possible tactics. This range of micro provided by the Pareto front enables a human or AI player to trade-off among short term tactics that better suit the player's longer term strategy - for example, choosing to minimize friendly unit damage at the cost of only lightly damaging the enemy versus maximizing damage to the enemy units at the cost of increased damage to friendly units. We believe that our results indicate the usefulness of potential fields as a representation, and of evolutionary multi-objective optimization as an approach, for generating good micro.
Co-evolving Real-Time Strategy Game Micro
Mar 27, 2018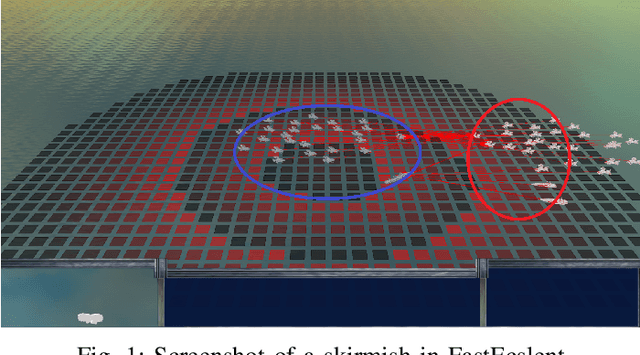
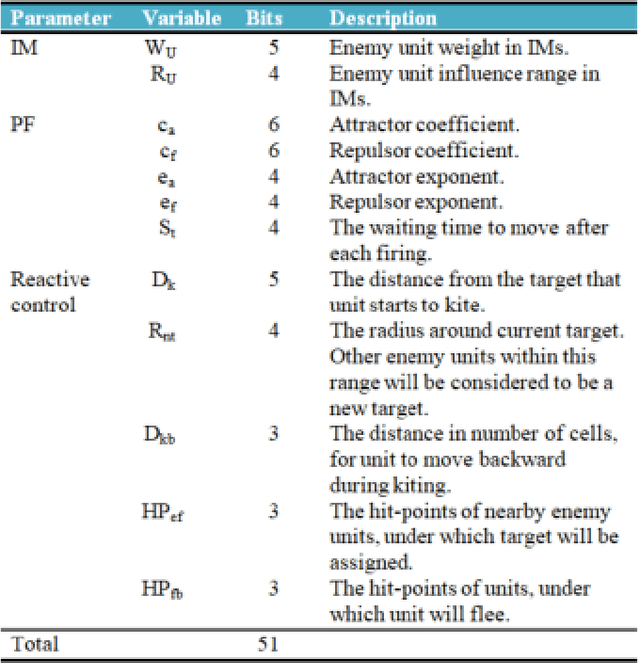
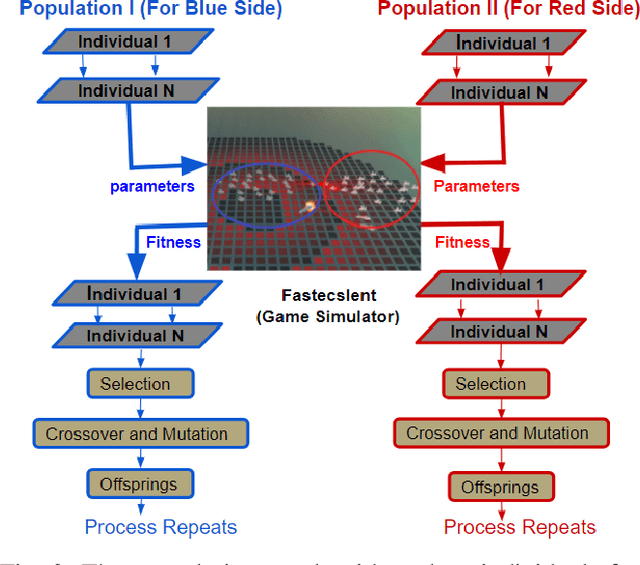
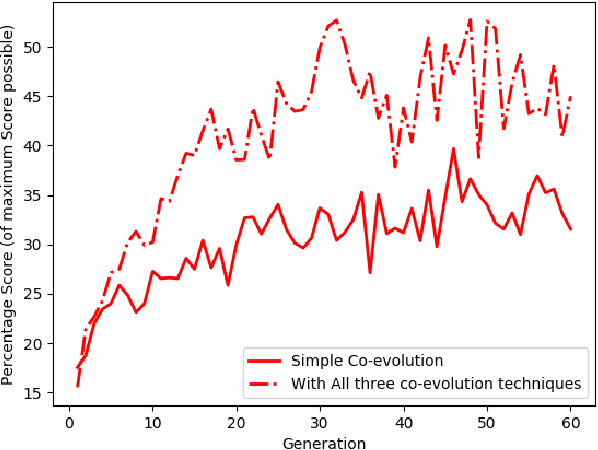
We investigate competitive co-evolution of unit micromanagement in real-time strategy games. Although good long-term macro-strategy and good short-term unit micromanagement both impact real-time strategy games performance, this paper focuses on generating quality micro. Better micro, for example, can help players win skirmishes and battles even when outnumbered. Prior work has shown that we can evolve micro to beat a given opponent. We remove the need for a good opponent to evolve against by using competitive co-evolution to evolve high-quality micro for both sides from scratch. We first co-evolve micro to control a group of ranged units versus a group of melee units. We then move to co-evolve micro for a group of ranged and melee units versus a group of ranged and melee units. Results show that competitive co-evolution produces good quality micro and when combined with the well-known techniques of fitness sharing, shared sampling, and a hall of fame takes less time to produce better quality micro than simple co-evolution. We believe these results indicate the viability of co-evolutionary approaches for generating good unit micro-management.
Neuroevolution for RTS Micro
Mar 27, 2018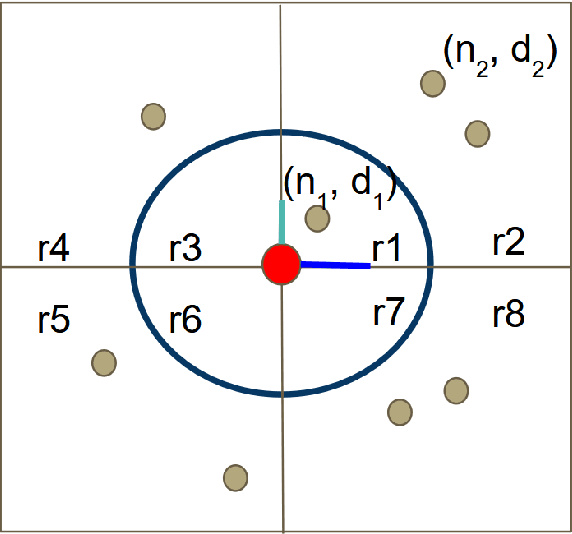
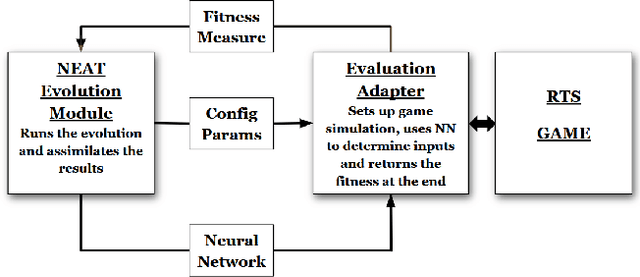
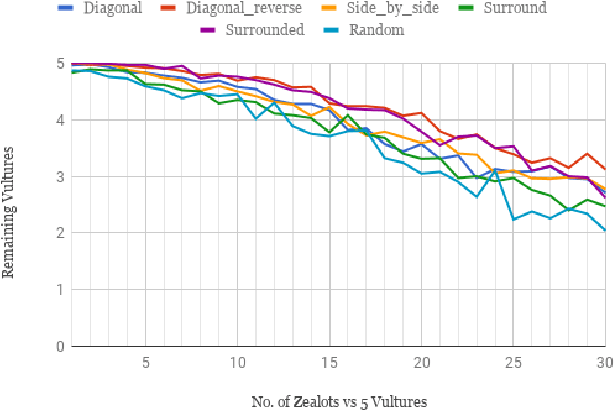
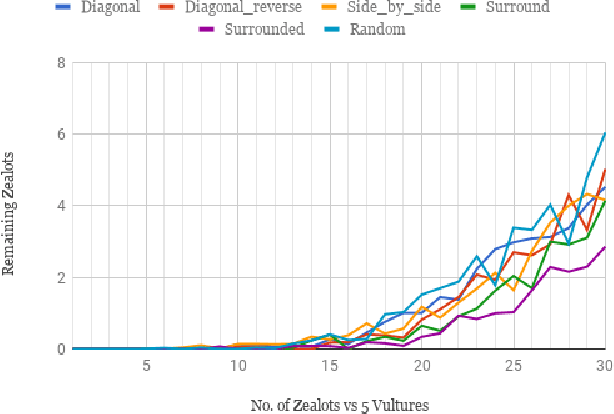
This paper uses neuroevolution of augmenting topologies to evolve control tactics for groups of units in real-time strategy games. In such games, players build economies to generate armies composed of multiple types of units with different attack and movement characteristics to combat each other. This paper evolves neural networks to control movement and attack commands, also called micro, for a group of ranged units skirmishing with a group of melee units. Our results show that neuroevolution of augmenting topologies can effectively generate neural networks capable of good micro for our ranged units against a group of hand-coded melee units. The evolved neural networks lead to kiting behavior for the ranged units which is a common tactic used by professional players in ranged versus melee skirmishes in popular real-time strategy games like Starcraft. The evolved neural networks also generalized well to other starting positions and numbers of units. We believe these results indicate the potential of neuroevolution for generating effective micro in real-time strategy games.
Multi-objective evolution for 3D RTS Micro
Mar 08, 2018
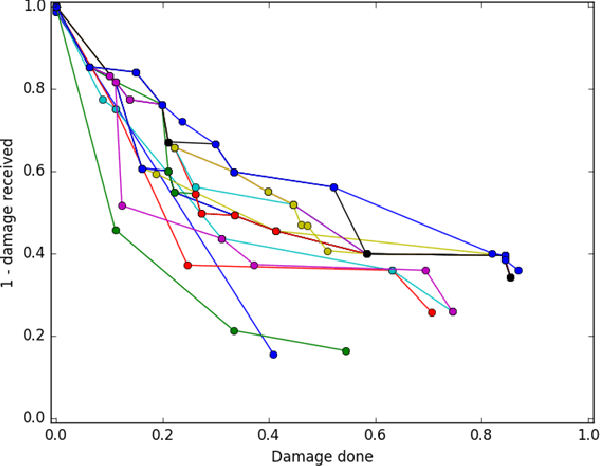


We attack the problem of controlling teams of autonomous units during skirmishes in real-time strategy games. Earlier work had shown promise in evolving control algorithm parameters that lead to high performance team behaviors similar to those favored by good human players in real-time strategy games like Starcraft. This algorithm specifically encoded parameterized kiting and fleeing behaviors and the genetic algorithm evolved these parameter values. In this paper we investigate using influence maps and potential fields alone to compactly represent and control real-time team behavior for entities that can maneuver in three dimensions. A two-objective fitness function that maximizes damage done and minimizes damage taken guides our multi-objective evolutionary algorithm. Preliminary results indicate that evolving friend and enemy unit potential field parameters for distance, weapon characteristics, and entity health suffice to produce complex, high performing, three-dimensional, team tactics.
Development of a Swarm UAV Simulator Integrating Realistic Motion Control Models For Disaster Operations
Nov 01, 2017

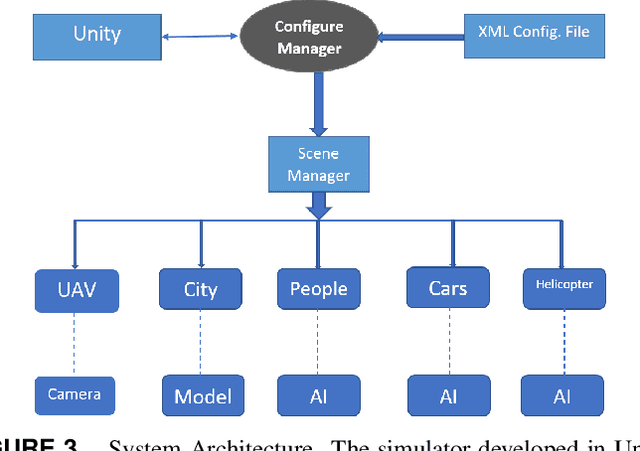
Simulation environments for Unmanned Aerial Vehicles (UAVs) can be very useful for prototyping user interfaces and training personnel that will operate UAVs in the real world. The realistic operation of such simulations will only enhance the value of such training. In this paper, we present the integration of a model-based waypoint navigation controller into the Reno Rescue Simulator for the purposes of providing a more realistic user interface in simulated environments. We also present potential uses for such simulations, even for real-world operation of UAVs.