 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Parameter Optimization Using Genetic Algorithm in Deep Reinforcement Learning for Robotic Manipulation Tasks
Apr 07, 2022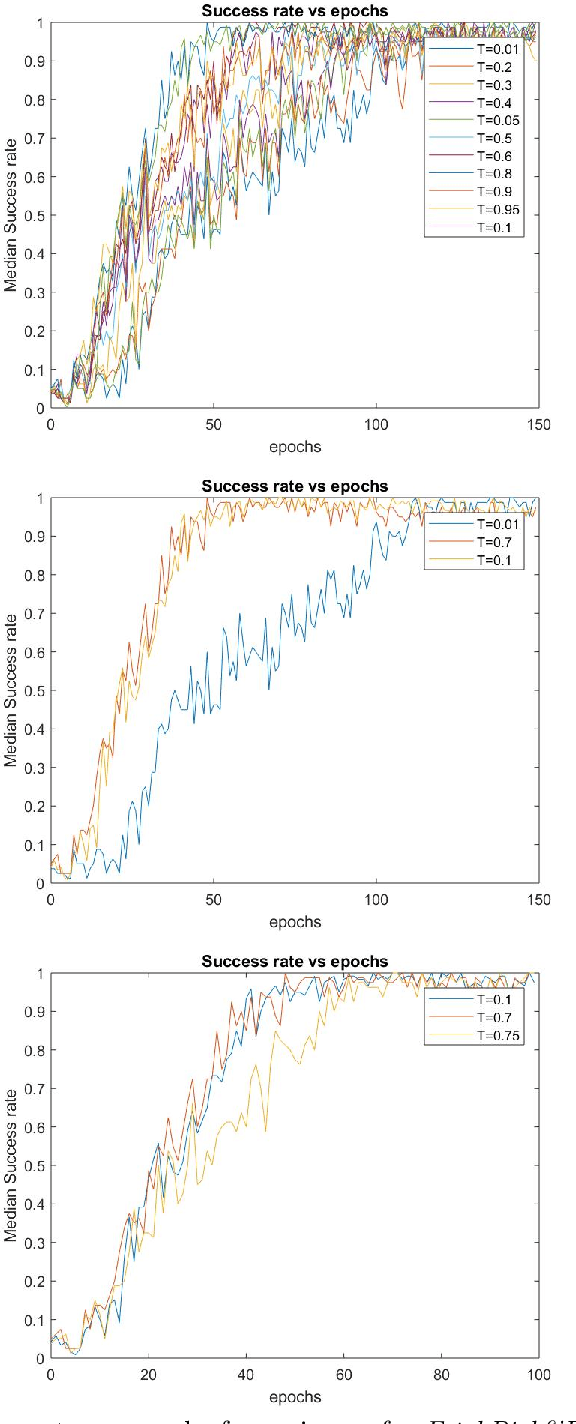
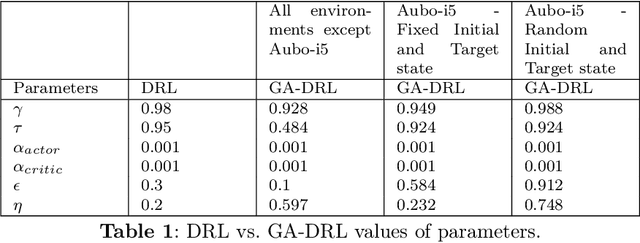
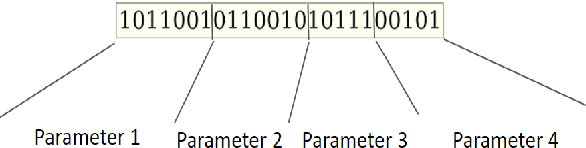
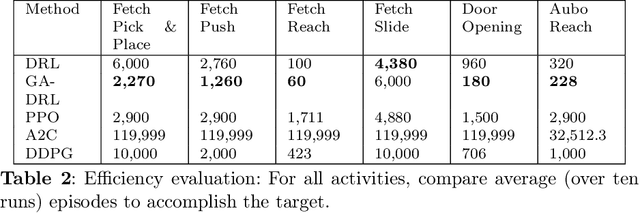
Learning agents can make use of Reinforcement Learning (RL) to decide their actions by using a reward function. However, the learning process is greatly influenced by the elect of values of the parameters used in the learning algorithm. This work proposed a Deep Deterministic Policy Gradient (DDPG) and Hindsight Experience Replay (HER) based method, which makes use of the Genetic Algorithm (GA) to fine-tune the parameters' values. This method (GA-DRL) experimented on six robotic manipulation tasks: fetch-reach; fetch-slide; fetch-push; fetch-pick and place; door-opening; and aubo-reach. Analysis of these results demonstrated a significant increase in performance and a decrease in learning time. Also, we compare and provide evidence that GA-DRL is better than the existing methods.
GA-DRL: Genetic Algorithm-Based Function Optimizer in Deep Reinforcement Learning for Robotic Manipulation Tasks
Feb 28, 2022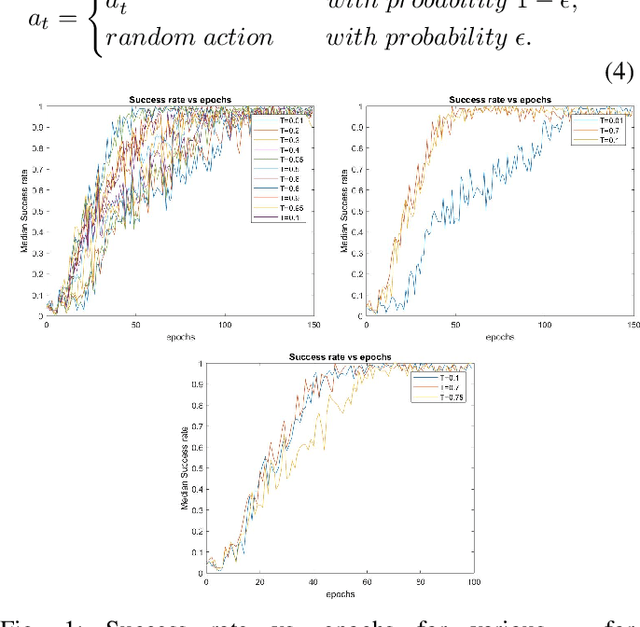
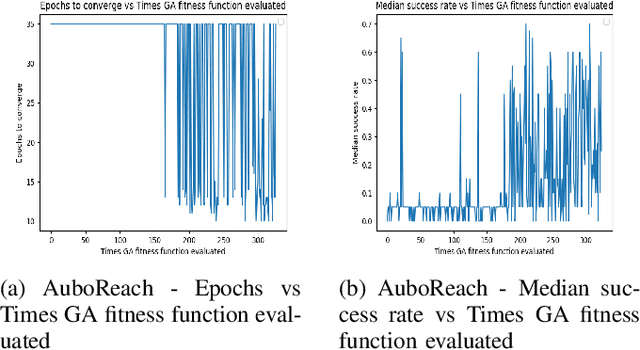
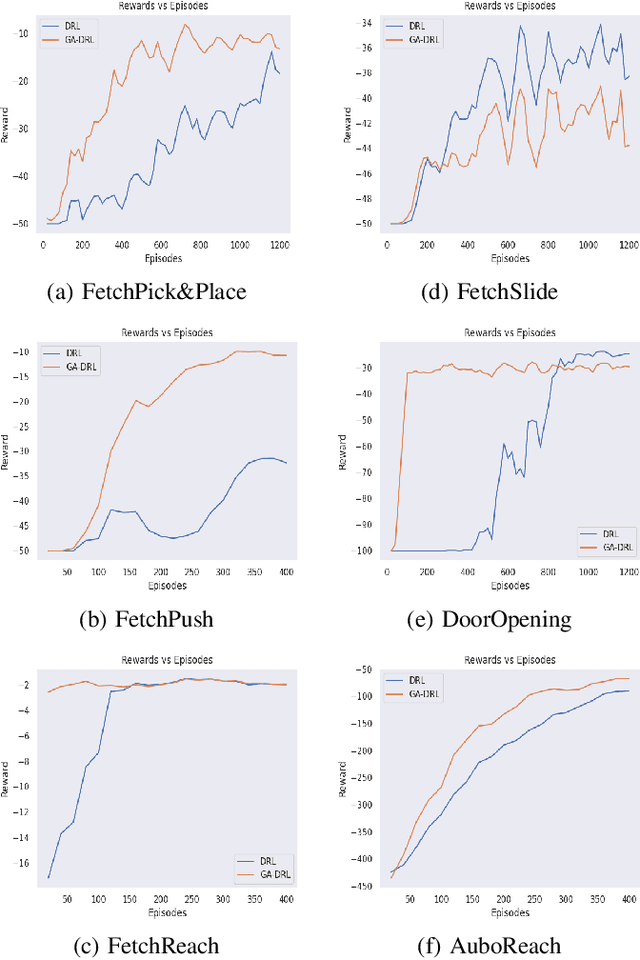
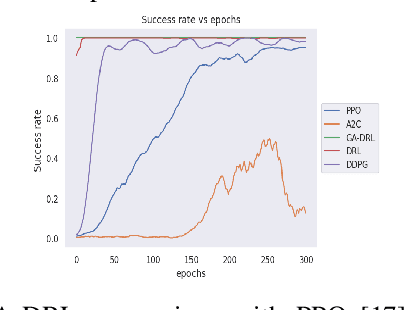
Reinforcement learning (RL) enables agents to make a decision based on a reward function. However, in the process of learning, the choice of values for learning algorithm parameters can significantly impact the overall learning process. In this paper, we proposed a Genetic Algorithm-based Deep Deterministic Policy Gradient and Hindsight Experience Replay method (called GA-DRL) to find near-optimal values of learning parameters. We used the proposed GA-DRL method on fetch-reach, slide, push, pick and place, and door opening in robotic manipulation tasks. With some modifications, our proposed GA-DRL method was also applied to the auboreach environment. Our experimental evaluation shows that our method leads to significantly better performance, faster than the original algorithm. Also, we provide evidence that GA-DRL performs better than the existing methods.
Evolutionary Multi-objective Optimization of Real-Time Strategy Micro
Mar 27, 2018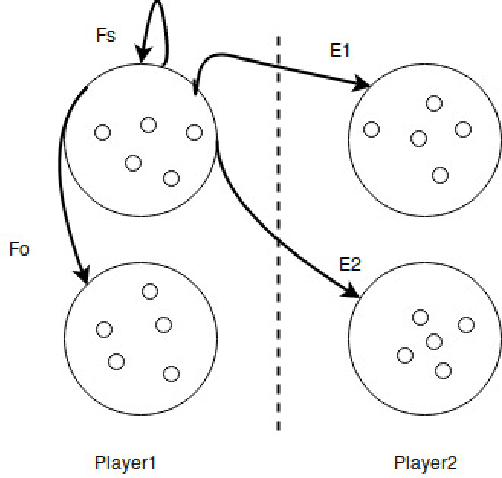
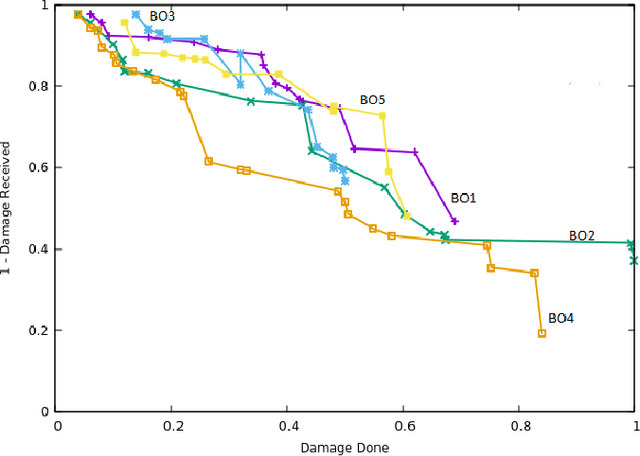
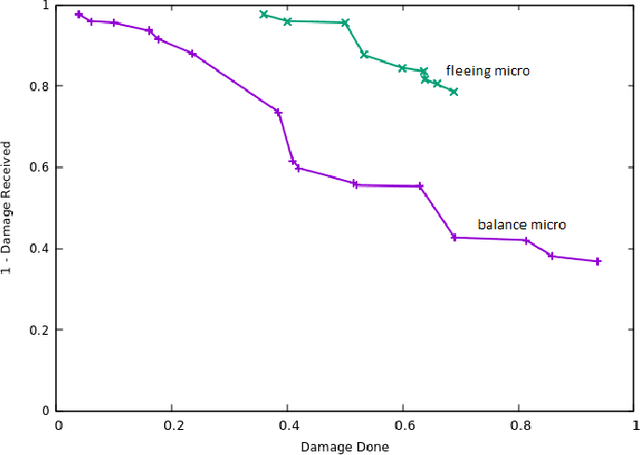
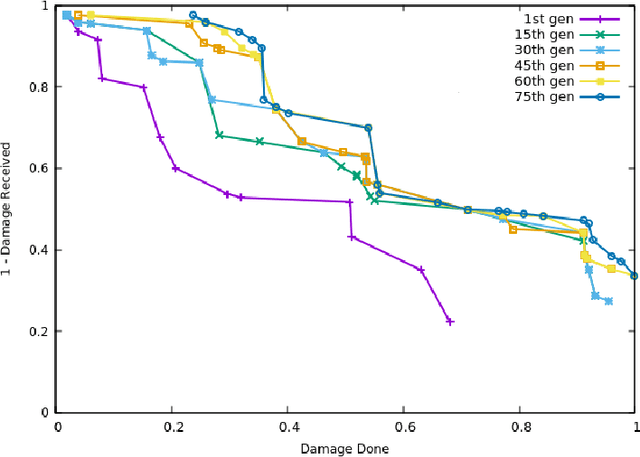
We investigate an evolutionary multi-objective approach to good micro for real-time strategy games. Good micro helps a player win skirmishes and is one of the keys to developing better real-time strategy game play. In prior work, the same multi-objective approach of maximizing damage done while minimizing damage received was used to evolve micro for a group of ranged units versus a group of melee units. We extend this work to consider groups composed from two types of units. Specifically, this paper uses evolutionary multi-objective optimization to generate micro for one group composed from both ranged and melee units versus another group of ranged and melee units. Our micro behavior representation uses influence maps to represent enemy spatial information and potential fields generated from distance, health, and weapons cool down to guide unit movement. Experimental results indicate that our multi-objective approach leads to a Pareto front of diverse high-quality micro encapsulating multiple possible tactics. This range of micro provided by the Pareto front enables a human or AI player to trade-off among short term tactics that better suit the player's longer term strategy - for example, choosing to minimize friendly unit damage at the cost of only lightly damaging the enemy versus maximizing damage to the enemy units at the cost of increased damage to friendly units. We believe that our results indicate the usefulness of potential fields as a representation, and of evolutionary multi-objective optimization as an approach, for generating good micro.
Development of a Swarm UAV Simulator Integrating Realistic Motion Control Models For Disaster Operations
Nov 01, 2017

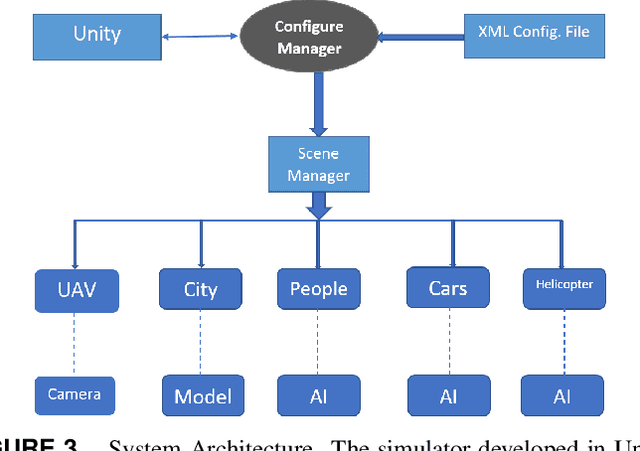
Simulation environments for Unmanned Aerial Vehicles (UAVs) can be very useful for prototyping user interfaces and training personnel that will operate UAVs in the real world. The realistic operation of such simulations will only enhance the value of such training. In this paper, we present the integration of a model-based waypoint navigation controller into the Reno Rescue Simulator for the purposes of providing a more realistic user interface in simulated environments. We also present potential uses for such simulations, even for real-world operation of UAVs.