 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAACHER: Assorted Actor-Critic Deep Reinforcement Learning with Hindsight Experience Replay
Oct 24, 2022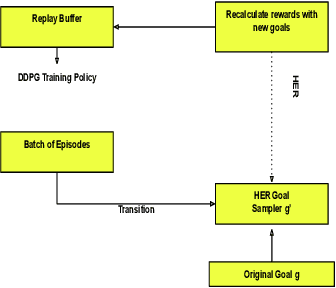



Actor learning and critic learning are two components of the outstanding and mostly used Deep Deterministic Policy Gradient (DDPG) reinforcement learning method. Since actor and critic learning plays a significant role in the overall robot's learning, the performance of the DDPG approach is relatively sensitive and unstable as a result. We propose a multi-actor-critic DDPG for reliable actor-critic learning to further enhance the performance and stability of DDPG. This multi-actor-critic DDPG is then integrated with Hindsight Experience Replay (HER) to form our new deep learning framework called AACHER. AACHER uses the average value of multiple actors or critics to substitute the single actor or critic in DDPG to increase resistance in the case when one actor or critic performs poorly. Numerous independent actors and critics can also gain knowledge from the environment more broadly. We implemented our proposed AACHER on goal-based environments: AuboReach, FetchReach-v1, FetchPush-v1, FetchSlide-v1, and FetchPickAndPlace-v1. For our experiments, we used various instances of actor/critic combinations, among which A10C10 and A20C20 were the best-performing combinations. Overall results show that AACHER outperforms the traditional algorithm (DDPG+HER) in all of the actor/critic number combinations that are used for evaluation. When used on FetchPickAndPlace-v1, the performance boost for A20C20 is as high as roughly 3.8 times the success rate in DDPG+HER.
Deep Learning Hyperparameter Optimization for Breast Mass Detection in Mammograms
Jul 22, 2022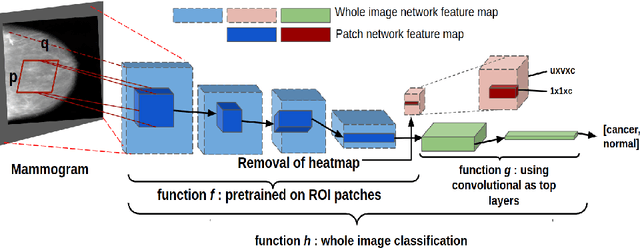
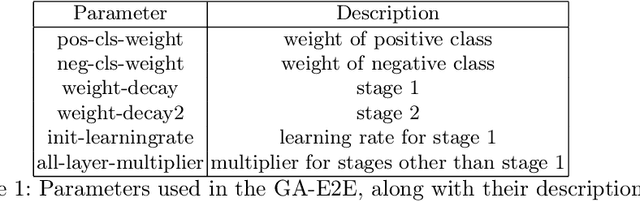
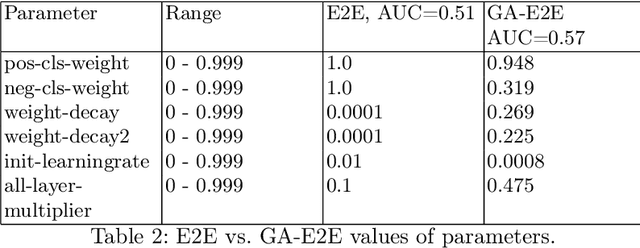
Accurate breast cancer diagnosis through mammography has the potential to save millions of lives around the world. Deep learning (DL) methods have shown to be very effective for mass detection in mammograms. Additional improvements of current DL models will further improve the effectiveness of these methods. A critical issue in this context is how to pick the right hyperparameters for DL models. In this paper, we present GA-E2E, a new approach for tuning the hyperparameters of DL models for brest cancer detection using Genetic Algorithms (GAs). Our findings reveal that differences in parameter values can considerably alter the area under the curve (AUC), which is used to determine a classifier's performance.
Automatic Parameter Optimization Using Genetic Algorithm in Deep Reinforcement Learning for Robotic Manipulation Tasks
Apr 07, 2022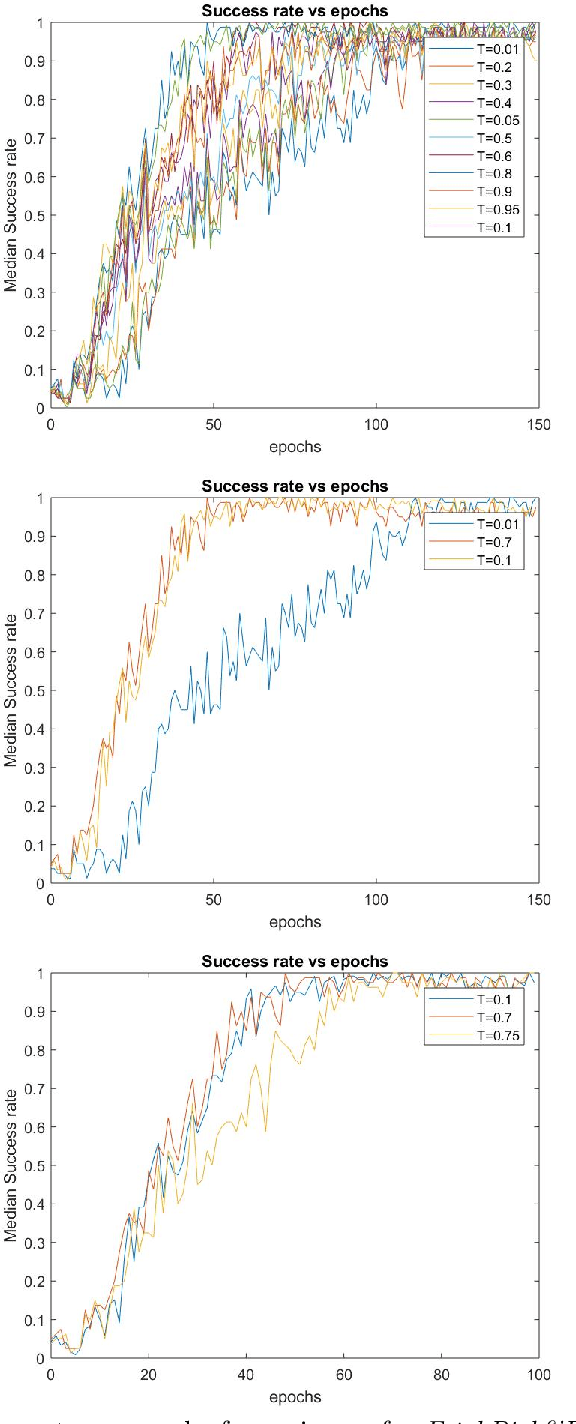
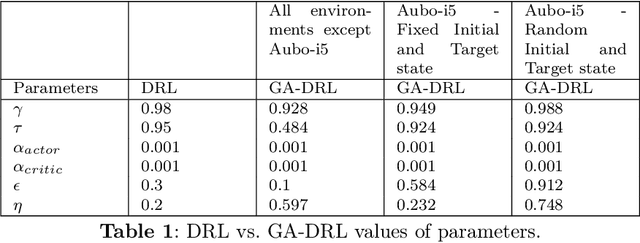
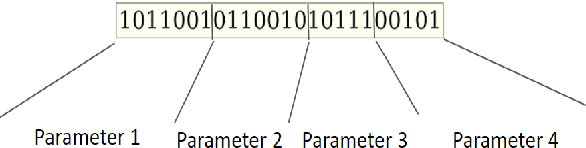
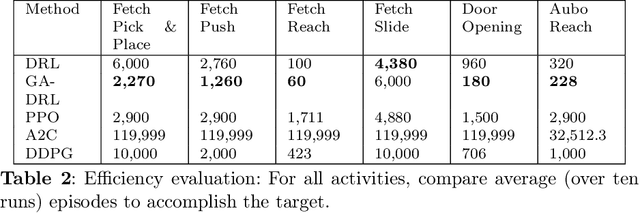
Learning agents can make use of Reinforcement Learning (RL) to decide their actions by using a reward function. However, the learning process is greatly influenced by the elect of values of the parameters used in the learning algorithm. This work proposed a Deep Deterministic Policy Gradient (DDPG) and Hindsight Experience Replay (HER) based method, which makes use of the Genetic Algorithm (GA) to fine-tune the parameters' values. This method (GA-DRL) experimented on six robotic manipulation tasks: fetch-reach; fetch-slide; fetch-push; fetch-pick and place; door-opening; and aubo-reach. Analysis of these results demonstrated a significant increase in performance and a decrease in learning time. Also, we compare and provide evidence that GA-DRL is better than the existing methods.
GA-DRL: Genetic Algorithm-Based Function Optimizer in Deep Reinforcement Learning for Robotic Manipulation Tasks
Feb 28, 2022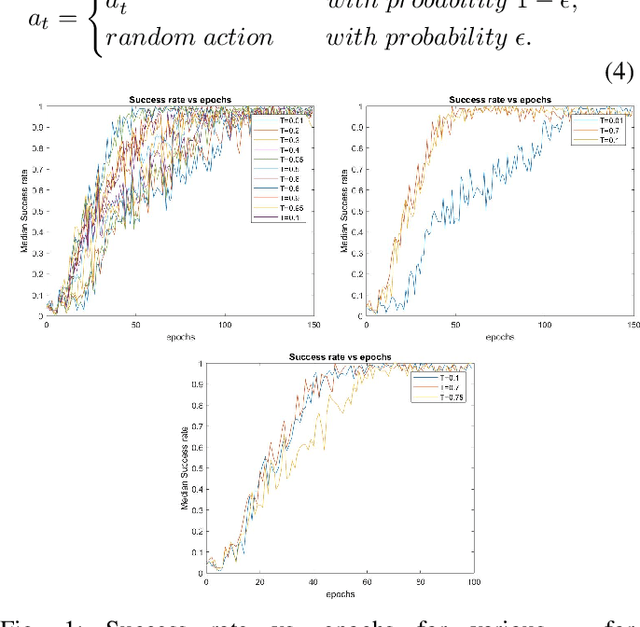
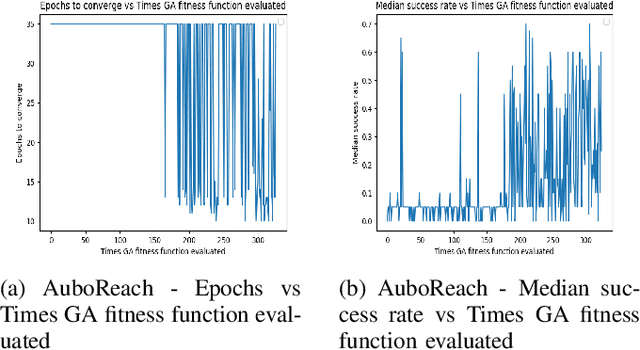
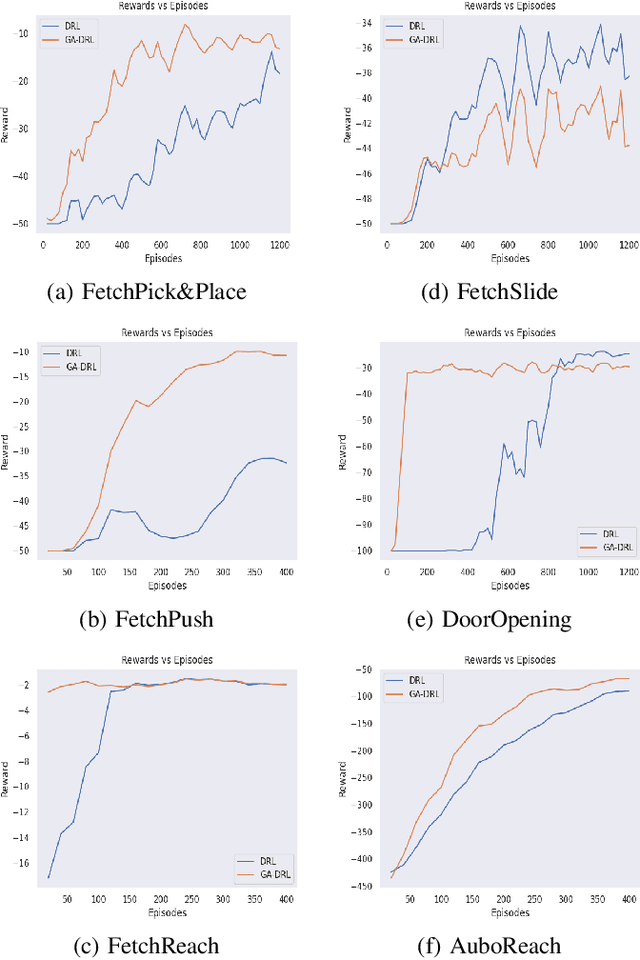
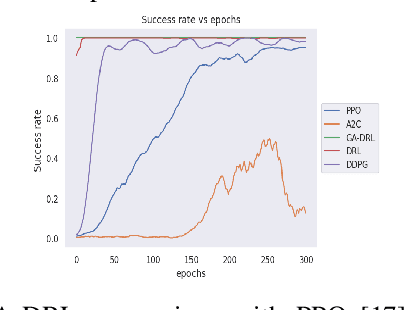
Reinforcement learning (RL) enables agents to make a decision based on a reward function. However, in the process of learning, the choice of values for learning algorithm parameters can significantly impact the overall learning process. In this paper, we proposed a Genetic Algorithm-based Deep Deterministic Policy Gradient and Hindsight Experience Replay method (called GA-DRL) to find near-optimal values of learning parameters. We used the proposed GA-DRL method on fetch-reach, slide, push, pick and place, and door opening in robotic manipulation tasks. With some modifications, our proposed GA-DRL method was also applied to the auboreach environment. Our experimental evaluation shows that our method leads to significantly better performance, faster than the original algorithm. Also, we provide evidence that GA-DRL performs better than the existing methods.
Lidar-Monocular Visual Odometry with Genetic Algorithm for Parameter Optimization
Mar 05, 2019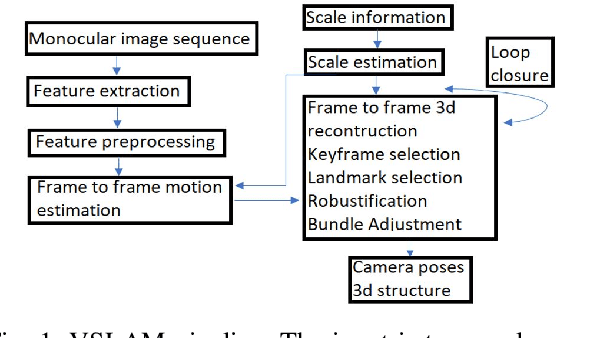

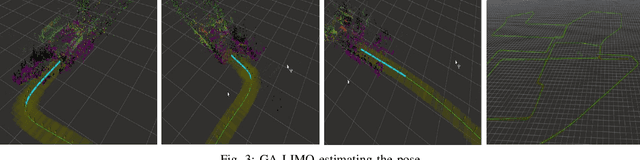

Lidar-Monocular Visual Odometry (LIMO), a odometry estimation algorithm, combines camera and LIght Detection And Ranging sensor (LIDAR) for visual localization by tracking camera features as well as features from LIDAR measurements, and it estimates the motion using Bundle Adjustment based on robust key frames. For rejecting the outliers, LIMO uses semantic labelling and weights of the vegetation landmarks. A drawback of LIMO as well as many other odometry estimation algorithms is that it has many parameters that need to be manually adjusted according to the dynamic changes in the environment in order to decrease the translational errors. In this paper, we present and argue the use of Genetic Algorithm to optimize parameters with reference to LIMO and maximize LIMO's localization and motion estimation performance. We evaluate our approach on the well known KITTI odometry dataset and show that the genetic algorithm helps LIMO to reduce translation error in different datasets.