 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaceGAN: A Framework for Preserving Individuality while Converting Racial Information for Image-to-Image Translation
Sep 18, 2025Generative adversarial networks (GANs) have demonstrated significant progress in unpaired image-to-image translation in recent years for several applications. CycleGAN was the first to lead the way, although it was restricted to a pair of domains. StarGAN overcame this constraint by tackling image-to-image translation across various domains, although it was not able to map in-depth low-level style changes for these domains. Style mapping via reference-guided image synthesis has been made possible by the innovations of StarGANv2 and StyleGAN. However, these models do not maintain individuality and need an extra reference image in addition to the input. Our study aims to translate racial traits by means of multi-domain image-to-image translation. We present RaceGAN, a novel framework capable of mapping style codes over several domains during racial attribute translation while maintaining individuality and high level semantics without relying on a reference image. RaceGAN outperforms other models in translating racial features (i.e., Asian, White, and Black) when tested on Chicago Face Dataset. We also give quantitative findings utilizing InceptionReNetv2-based classification to demonstrate the effectiveness of our racial translation. Moreover, we investigate how well the model partitions the latent space into distinct clusters of faces for each ethnic group.
Can Score-Based Generative Modeling Effectively Handle Medical Image Classification?
Feb 24, 2025
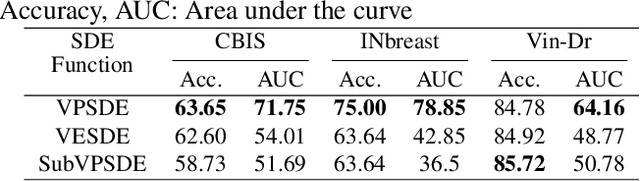
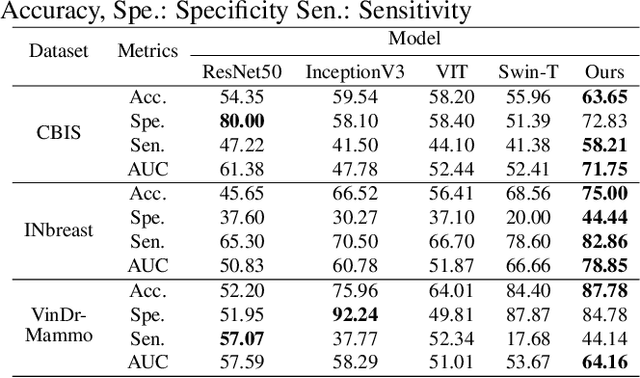
The remarkable success of deep learning in recent years has prompted applications in medical image classification and diagnosis tasks. While classification models have demonstrated robustness in classifying simpler datasets like MNIST or natural images such as ImageNet, this resilience is not consistently observed in complex medical image datasets where data is more scarce and lacks diversity. Moreover, previous findings on natural image datasets have indicated a potential trade-off between data likelihood and classification accuracy. In this study, we explore the use of score-based generative models as classifiers for medical images, specifically mammographic images. Our findings suggest that our proposed generative classifier model not only achieves superior classification results on CBIS-DDSM, INbreast and Vin-Dr Mammo datasets, but also introduces a novel approach to image classification in a broader context. Our code is publicly available at https://github.com/sushmitasarker/sgc_for_medical_image_classification
A comprehensive overview of deep learning techniques for 3D point cloud classification and semantic segmentation
May 20, 2024Point cloud analysis has a wide range of applications in many areas such as computer vision, robotic manipulation, and autonomous driving. While deep learning has achieved remarkable success on image-based tasks, there are many unique challenges faced by deep neural networks in processing massive, unordered, irregular and noisy 3D points. To stimulate future research, this paper analyzes recent progress in deep learning methods employed for point cloud processing and presents challenges and potential directions to advance this field. It serves as a comprehensive review on two major tasks in 3D point cloud processing-- namely, 3D shape classification and semantic segmentation.
* Published in Springer Nature (Machine Vision and Applications)
MV-Swin-T: Mammogram Classification with Multi-view Swin Transformer
Feb 26, 2024Traditional deep learning approaches for breast cancer classification has predominantly concentrated on single-view analysis. In clinical practice, however, radiologists concurrently examine all views within a mammography exam, leveraging the inherent correlations in these views to effectively detect tumors. Acknowledging the significance of multi-view analysis, some studies have introduced methods that independently process mammogram views, either through distinct convolutional branches or simple fusion strategies, inadvertently leading to a loss of crucial inter-view correlations. In this paper, we propose an innovative multi-view network exclusively based on transformers to address challenges in mammographic image classification. Our approach introduces a novel shifted window-based dynamic attention block, facilitating the effective integration of multi-view information and promoting the coherent transfer of this information between views at the spatial feature map level. Furthermore, we conduct a comprehensive comparative analysis of the performance and effectiveness of transformer-based models under diverse settings, employing the CBIS-DDSM and Vin-Dr Mammo datasets. Our code is publicly available at https://github.com/prithuls/MV-Swin-T
Revolutionizing Space Health (Swin-FSR): Advancing Super-Resolution of Fundus Images for SANS Visual Assessment Technology
Aug 11, 2023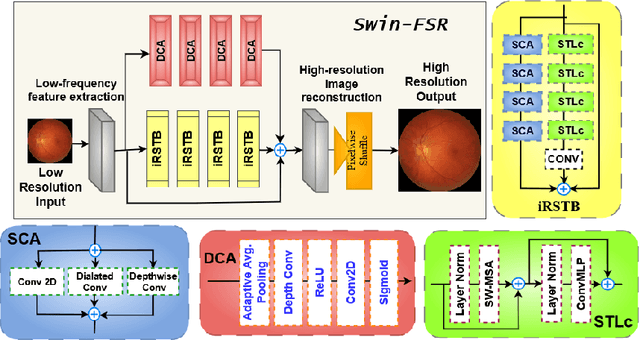
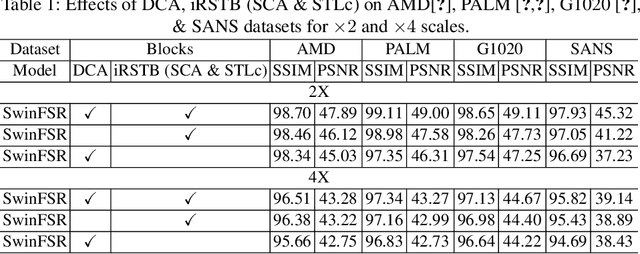
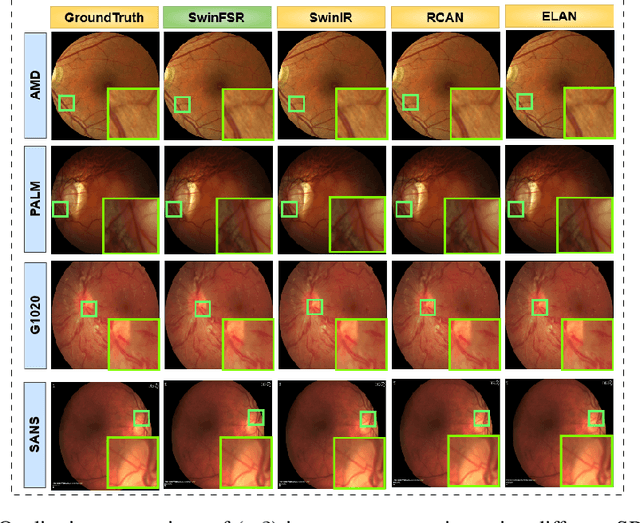
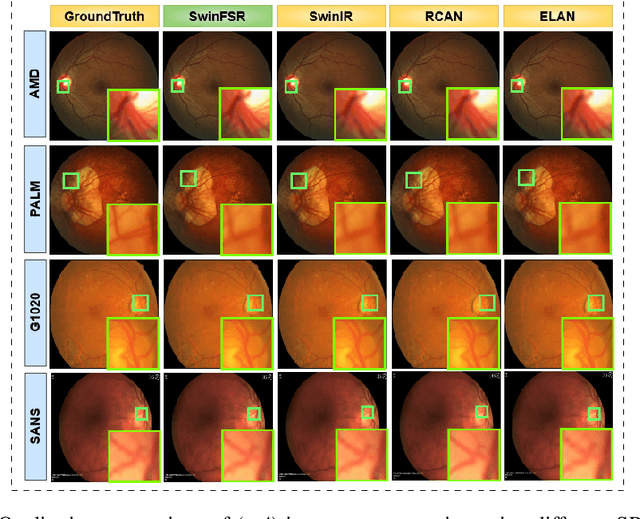
The rapid accessibility of portable and affordable retinal imaging devices has made early differential diagnosis easier. For example, color funduscopy imaging is readily available in remote villages, which can help to identify diseases like age-related macular degeneration (AMD), glaucoma, or pathological myopia (PM). On the other hand, astronauts at the International Space Station utilize this camera for identifying spaceflight-associated neuro-ocular syndrome (SANS). However, due to the unavailability of experts in these locations, the data has to be transferred to an urban healthcare facility (AMD and glaucoma) or a terrestrial station (e.g, SANS) for more precise disease identification. Moreover, due to low bandwidth limits, the imaging data has to be compressed for transfer between these two places. Different super-resolution algorithms have been proposed throughout the years to address this. Furthermore, with the advent of deep learning, the field has advanced so much that x2 and x4 compressed images can be decompressed to their original form without losing spatial information. In this paper, we introduce a novel model called Swin-FSR that utilizes Swin Transformer with spatial and depth-wise attention for fundus image super-resolution. Our architecture achieves Peak signal-to-noise-ratio (PSNR) of 47.89, 49.00 and 45.32 on three public datasets, namely iChallenge-AMD, iChallenge-PM, and G1020. Additionally, we tested the model's effectiveness on a privately held dataset for SANS provided by NASA and achieved comparable results against previous architectures.
SwinVFTR: A Novel Volumetric Feature-learning Transformer for 3D OCT Fluid Segmentation
Mar 17, 2023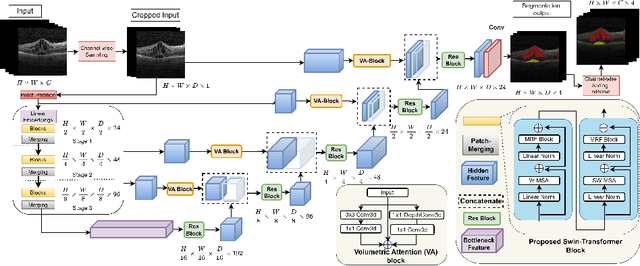
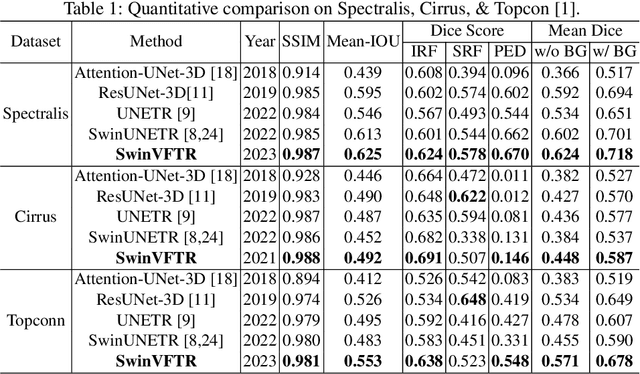
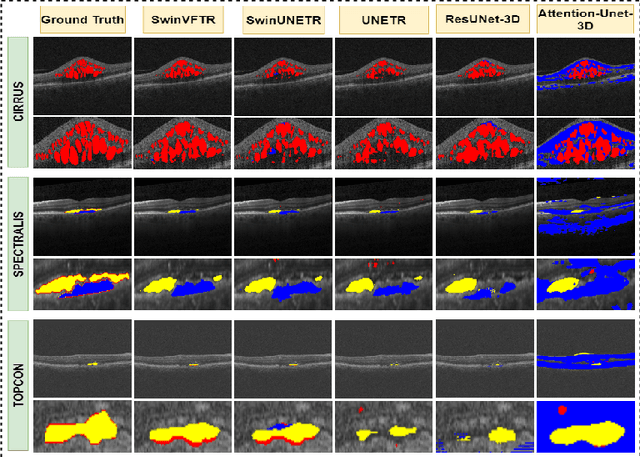
Accurately segmenting fluid in 3D volumetric optical coherence tomography (OCT) images is a crucial yet challenging task for detecting eye diseases. Traditional autoencoding-based segmentation approaches have limitations in extracting fluid regions due to successive resolution loss in the encoding phase and the inability to recover lost information in the decoding phase. Although current transformer-based models for medical image segmentation addresses this limitation, they are not designed to be applied out-of-the-box for 3D OCT volumes, which have a wide-ranging channel-axis size based on different vendor device and extraction technique. To address these issues, we propose SwinVFTR, a new transformer-based architecture designed for precise fluid segmentation in 3D volumetric OCT images. We first utilize a channel-wise volumetric sampling for training on OCT volumes with varying depths (B-scans). Next, the model uses a novel shifted window transformer block in the encoder to achieve better localization and segmentation of fluid regions. Additionally, we propose a new volumetric attention block for spatial and depth-wise attention, which improves upon traditional residual skip connections. Consequently, utilizing multi-class dice loss, the proposed architecture outperforms other existing architectures on the three publicly available vendor-specific OCT datasets, namely Spectralis, Cirrus, and Topcon, with mean dice scores of 0.72, 0.59, and 0.68, respectively. Additionally, SwinVFTR outperforms other architectures in two additional relevant metrics, mean intersection-over-union (Mean-IOU) and structural similarity measure (SSIM).
SWIN-SFTNet : Spatial Feature Expansion and Aggregation using Swin Transformer For Whole Breast micro-mass segmentation
Nov 16, 2022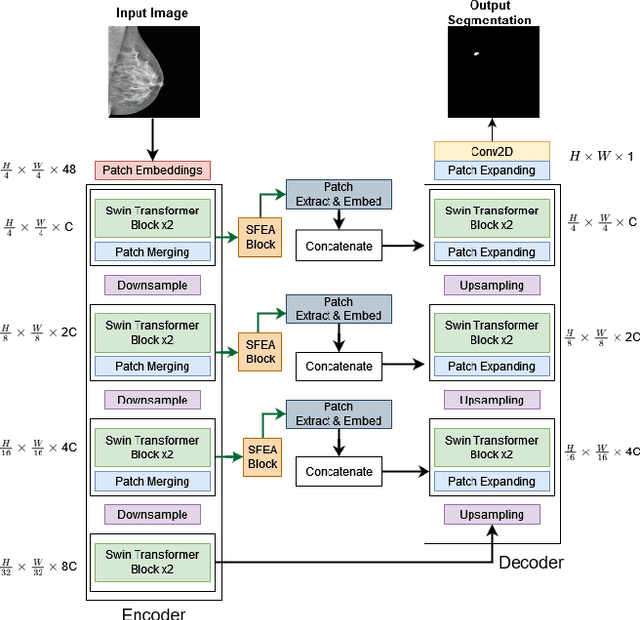
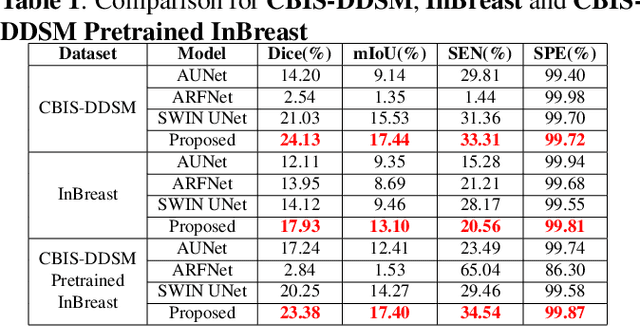
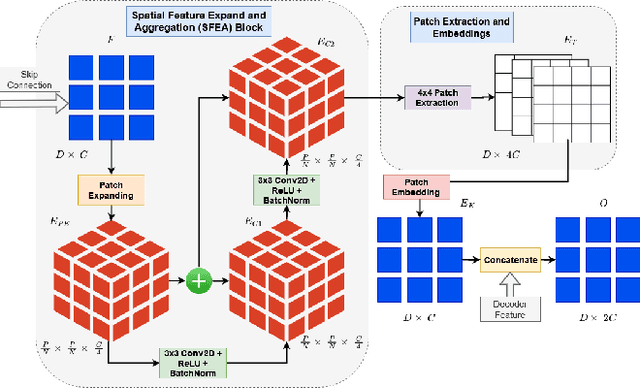

Incorporating various mass shapes and sizes in training deep learning architectures has made breast mass segmentation challenging. Moreover, manual segmentation of masses of irregular shapes is time-consuming and error-prone. Though Deep Neural Network has shown outstanding performance in breast mass segmentation, it fails in segmenting micro-masses. In this paper, we propose a novel U-net-shaped transformer-based architecture, called Swin-SFTNet, that outperforms state-of-the-art architectures in breast mammography-based micro-mass segmentation. Firstly to capture the global context, we designed a novel Spatial Feature Expansion and Aggregation Block(SFEA) that transforms sequential linear patches into a structured spatial feature. Next, we combine it with the local linear features extracted by the swin transformer block to improve overall accuracy. We also incorporate a novel embedding loss that calculates similarities between linear feature embeddings of the encoder and decoder blocks. With this approach, we achieve higher segmentation dice over the state-of-the-art by 3.10% on CBIS-DDSM, 3.81% on InBreast, and 3.13% on CBIS pre-trained model on the InBreast test data set.
ConnectedUNets++: Mass Segmentation from Whole Mammographic Images
Nov 04, 2022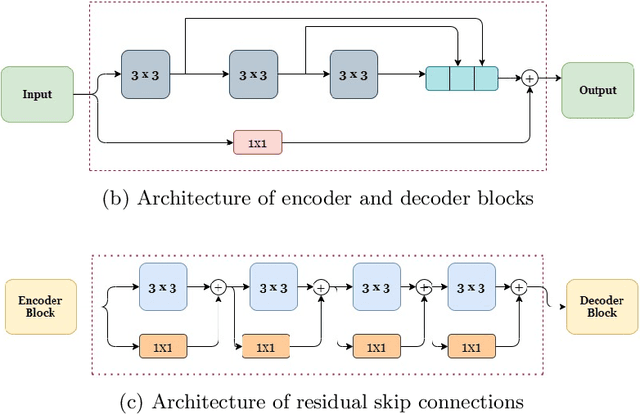
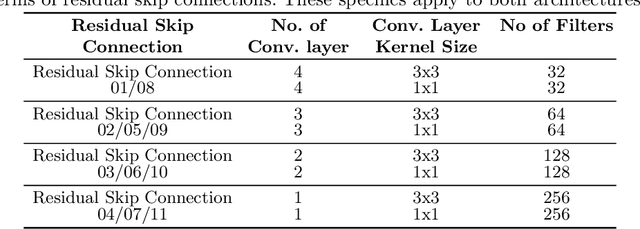
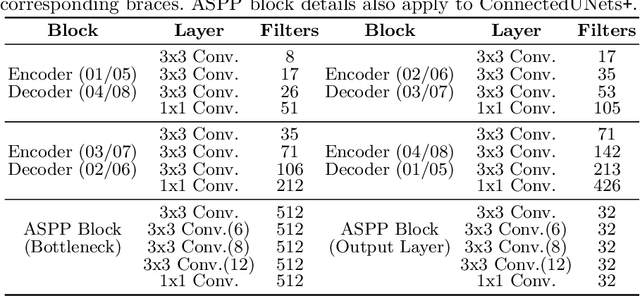
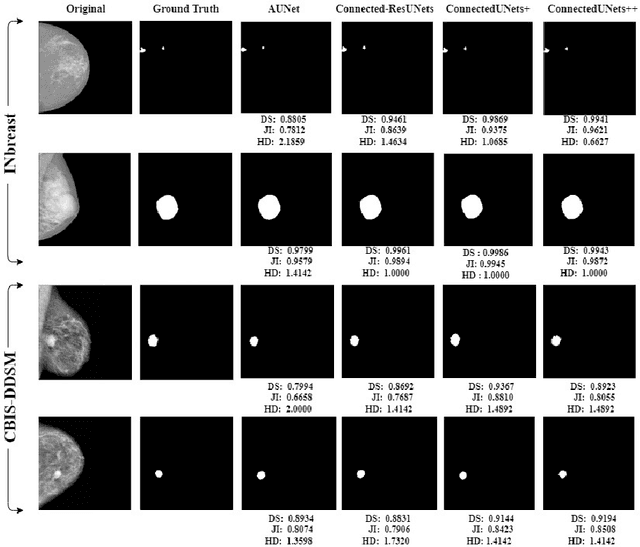
Deep learning has made a breakthrough in medical image segmentation in recent years due to its ability to extract high-level features without the need for prior knowledge. In this context, U-Net is one of the most advanced medical image segmentation models, with promising results in mammography. Despite its excellent overall performance in segmenting multimodal medical images, the traditional U-Net structure appears to be inadequate in various ways. There are certain U-Net design modifications, such as MultiResUNet, Connected-UNets, and AU-Net, that have improved overall performance in areas where the conventional U-Net architecture appears to be deficient. Following the success of UNet and its variants, we have presented two enhanced versions of the Connected-UNets architecture: ConnectedUNets+ and ConnectedUNets++. In ConnectedUNets+, we have replaced the simple skip connections of Connected-UNets architecture with residual skip connections, while in ConnectedUNets++, we have modified the encoder-decoder structure along with employing residual skip connections. We have evaluated our proposed architectures on two publicly available datasets, the Curated Breast Imaging Subset of Digital Database for Screening Mammography (CBIS-DDSM) and INbreast.
Virtual-Reality based Vestibular Ocular Motor Screening for Concussion Detection using Machine-Learning
Oct 13, 2022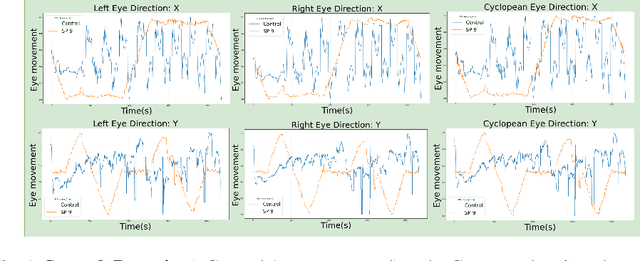

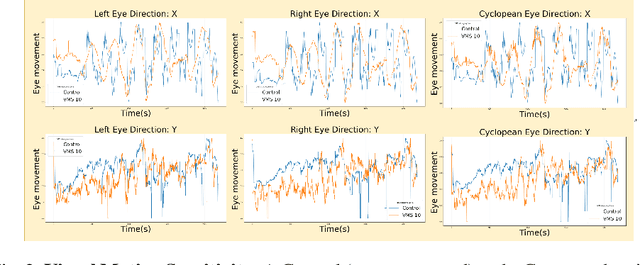
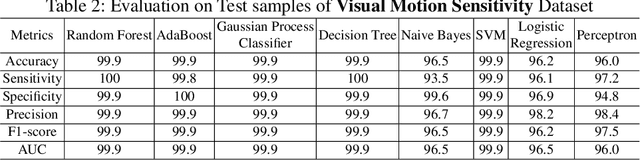
Sport-related concussion (SRC) depends on sensory information from visual, vestibular, and somatosensory systems. At the same time, the current clinical administration of Vestibular/Ocular Motor Screening (VOMS) is subjective and deviates among administrators. Therefore, for the assessment and management of concussion detection, standardization is required to lower the risk of injury and increase the validation among clinicians. With the advancement of technology, virtual reality (VR) can be utilized to advance the standardization of the VOMS, increasing the accuracy of testing administration and decreasing overall false positive rates. In this paper, we experimented with multiple machine learning methods to detect SRC on VR-generated data using VOMS. In our observation, the data generated from VR for smooth pursuit (SP) and the Visual Motion Sensitivity (VMS) tests are highly reliable for concussion detection. Furthermore, we train and evaluate these models, both qualitatively and quantitatively. Our findings show these models can reach high true-positive-rates of around 99.9 percent of symptom provocation on the VR stimuli-based VOMS vs. current clinical manual VOMS.
Analysis of Smooth Pursuit Assessment in Virtual Reality and Concussion Detection using BiLSTM
Oct 12, 2022
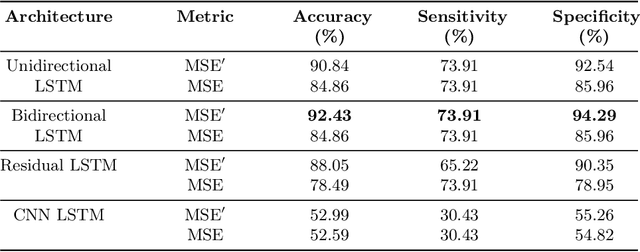
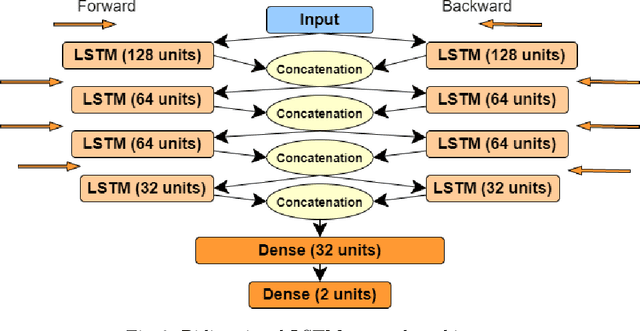
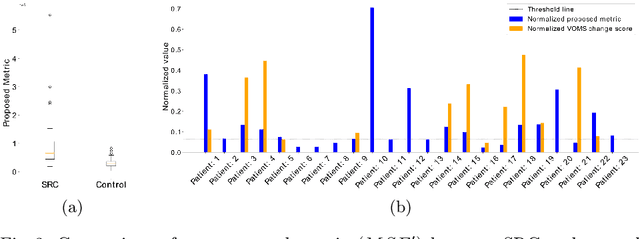
The sport-related concussion (SRC) battery relies heavily upon subjective symptom reporting in order to determine the diagnosis of a concussion. Unfortunately, athletes with SRC may return-to-play (RTP) too soon if they are untruthful of their symptoms. It is critical to provide accurate assessments that can overcome underreporting to prevent further injury. To lower the risk of injury, a more robust and precise method for detecting concussion is needed to produce reliable and objective results. In this paper, we propose a novel approach to detect SRC using long short-term memory (LSTM) recurrent neural network (RNN) architectures from oculomotor data. In particular, we propose a new error metric that incorporates mean squared error in different proportions. The experimental results on the smooth pursuit test of the VR-VOMS dataset suggest that the proposed approach can predict concussion symptoms with higher accuracy compared to symptom provocation on the vestibular ocular motor screening (VOMS).