 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwinVFTR: A Novel Volumetric Feature-learning Transformer for 3D OCT Fluid Segmentation
Mar 17, 2023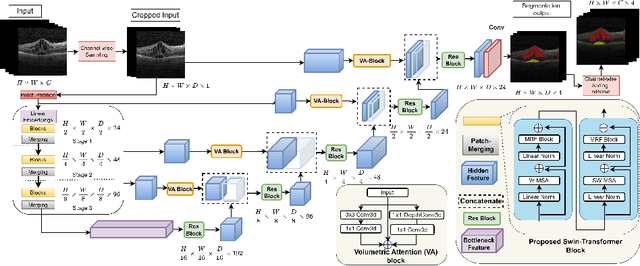
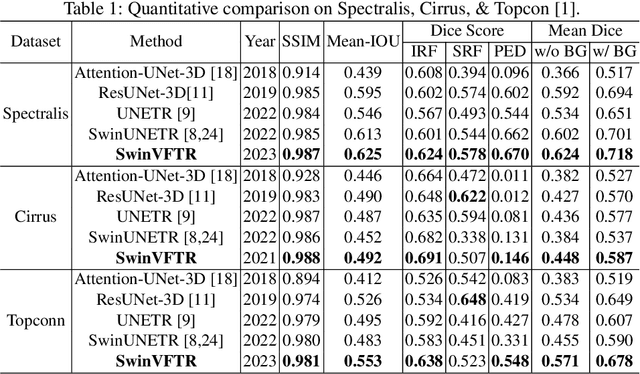
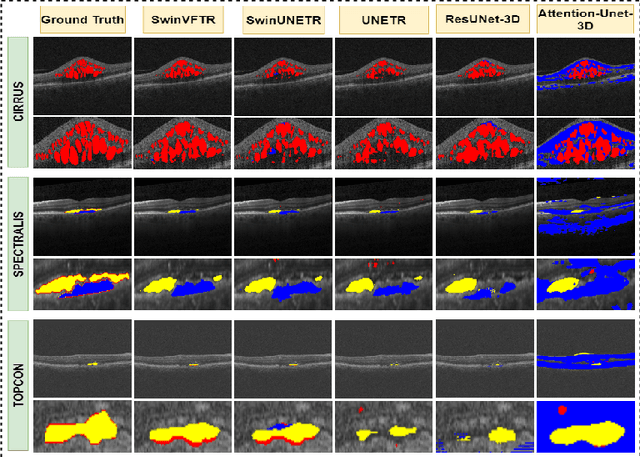
Accurately segmenting fluid in 3D volumetric optical coherence tomography (OCT) images is a crucial yet challenging task for detecting eye diseases. Traditional autoencoding-based segmentation approaches have limitations in extracting fluid regions due to successive resolution loss in the encoding phase and the inability to recover lost information in the decoding phase. Although current transformer-based models for medical image segmentation addresses this limitation, they are not designed to be applied out-of-the-box for 3D OCT volumes, which have a wide-ranging channel-axis size based on different vendor device and extraction technique. To address these issues, we propose SwinVFTR, a new transformer-based architecture designed for precise fluid segmentation in 3D volumetric OCT images. We first utilize a channel-wise volumetric sampling for training on OCT volumes with varying depths (B-scans). Next, the model uses a novel shifted window transformer block in the encoder to achieve better localization and segmentation of fluid regions. Additionally, we propose a new volumetric attention block for spatial and depth-wise attention, which improves upon traditional residual skip connections. Consequently, utilizing multi-class dice loss, the proposed architecture outperforms other existing architectures on the three publicly available vendor-specific OCT datasets, namely Spectralis, Cirrus, and Topcon, with mean dice scores of 0.72, 0.59, and 0.68, respectively. Additionally, SwinVFTR outperforms other architectures in two additional relevant metrics, mean intersection-over-union (Mean-IOU) and structural similarity measure (SSIM).
Feature Representation Learning for Robust Retinal Disease Detection from Optical Coherence Tomography Images
Jun 24, 2022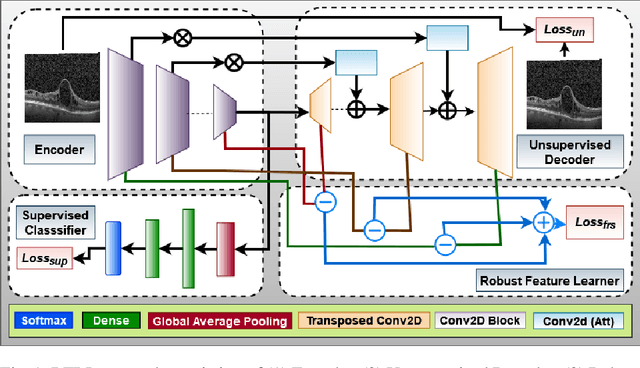
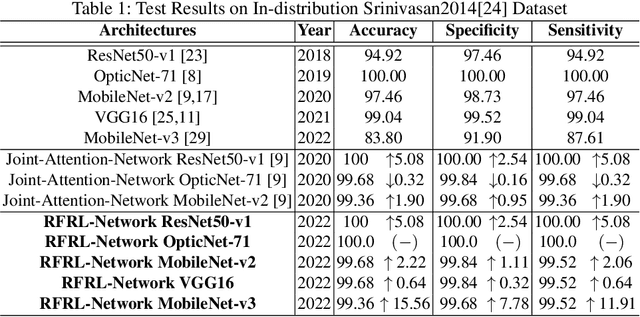
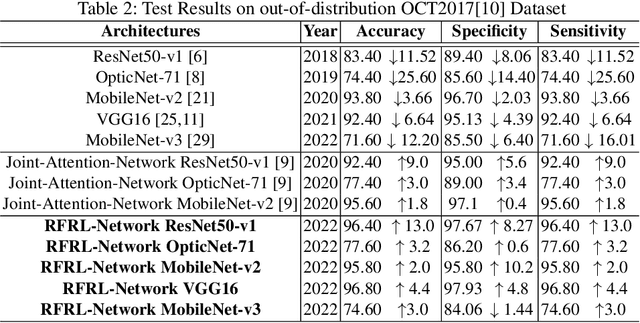
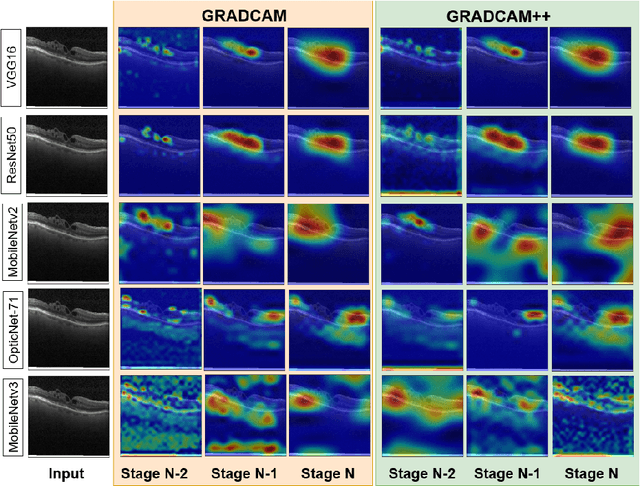
Ophthalmic images may contain identical-looking pathologies that can cause failure in automated techniques to distinguish different retinal degenerative diseases. Additionally, reliance on large annotated datasets and lack of knowledge distillation can restrict ML-based clinical support systems' deployment in real-world environments. To improve the robustness and transferability of knowledge, an enhanced feature-learning module is required to extract meaningful spatial representations from the retinal subspace. Such a module, if used effectively, can detect unique disease traits and differentiate the severity of such retinal degenerative pathologies. In this work, we propose a robust disease detection architecture with three learning heads, i) A supervised encoder for retinal disease classification, ii) An unsupervised decoder for the reconstruction of disease-specific spatial information, and iii) A novel representation learning module for learning the similarity between encoder-decoder feature and enhancing the accuracy of the model. Our experimental results on two publicly available OCT datasets illustrate that the proposed model outperforms existing state-of-the-art models in terms of accuracy, interpretability, and robustness for out-of-distribution retinal disease detection.
VTGAN: Semi-supervised Retinal Image Synthesis and Disease Prediction using Vision Transformers
Apr 14, 2021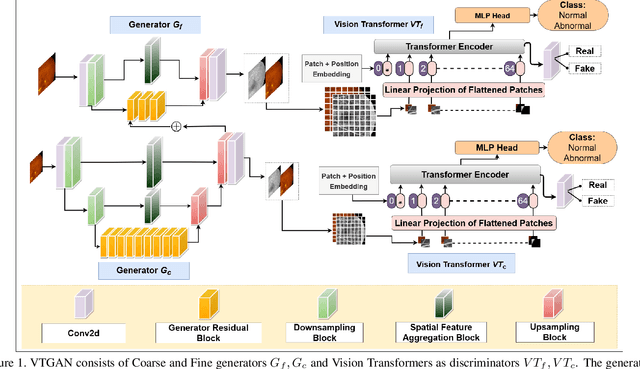
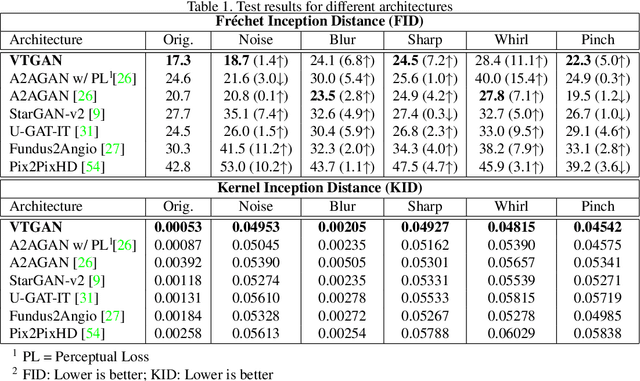
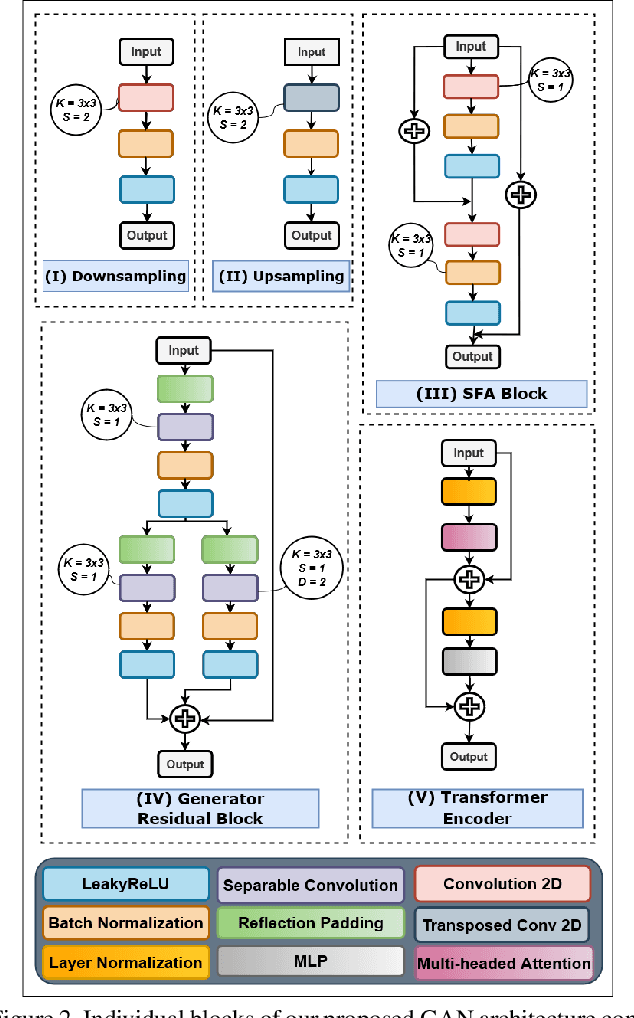
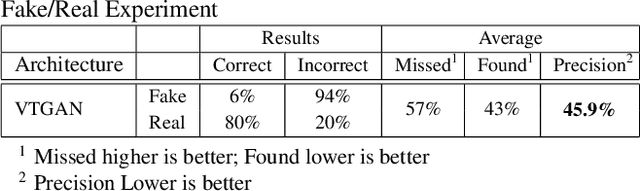
In Fluorescein Angiography (FA), an exogenous dye is injected in the bloodstream to image the vascular structure of the retina. The injected dye can cause adverse reactions such as nausea, vomiting, anaphylactic shock, and even death. In contrast, color fundus imaging is a non-invasive technique used for photographing the retina but does not have sufficient fidelity for capturing its vascular structure. The only non-invasive method for capturing retinal vasculature is optical coherence tomography-angiography (OCTA). However, OCTA equipment is quite expensive, and stable imaging is limited to small areas on the retina. In this paper, we propose a novel conditional generative adversarial network (GAN) capable of simultaneously synthesizing FA images from fundus photographs while predicting retinal degeneration. The proposed system has the benefit of addressing the problem of imaging retinal vasculature in a non-invasive manner as well as predicting the existence of retinal abnormalities. We use a semi-supervised approach to train our GAN using multiple weighted losses on different modalities of data. Our experiments validate that the proposed architecture exceeds recent state-of-the-art generative networks for fundus-to-angiography synthesis. Moreover, our vision transformer-based discriminators generalize quite well on out-of-distribution data sets for retinal disease prediction.
RV-GAN : Retinal Vessel Segmentation from Fundus Images using Multi-scale Generative Adversarial Networks
Jan 03, 2021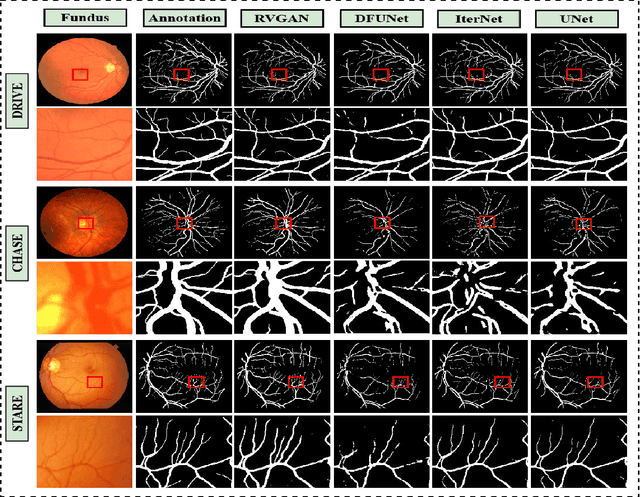
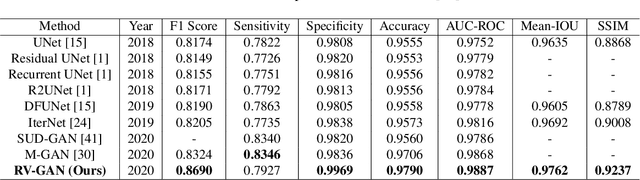
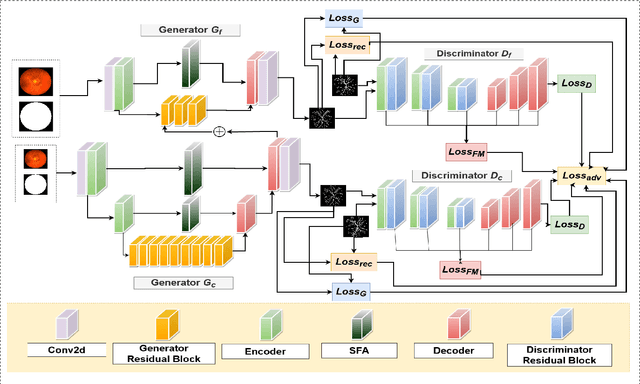
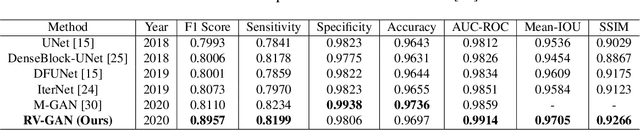
Retinal vessel segmentation contributes significantly to the domain of retinal image analysis for the diagnosis of vision-threatening diseases. With existing techniques the generated segmentation result deteriorates when thresholded with higher confidence value. To alleviate from this, we propose RVGAN, a new multi-scale generative architecture for accurate retinal vessel segmentation. Our architecture uses two generators and two multi-scale autoencoder based discriminators, for better microvessel localization and segmentation. By combining reconstruction and weighted feature matching loss, our adversarial training scheme generates highly accurate pixel-wise segmentation of retinal vessels with threshold >= 0.5. The architecture achieves AUC of 0.9887, 0.9814, and 0.9887 on three publicly available datasets, namely DRIVE, CHASE-DB1, and STARE, respectively. Additionally, RV-GAN outperforms other architectures in two additional relevant metrics, Mean-IOU and SSIM.