 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Representation Learning for Robust Retinal Disease Detection from Optical Coherence Tomography Images
Paper and Code
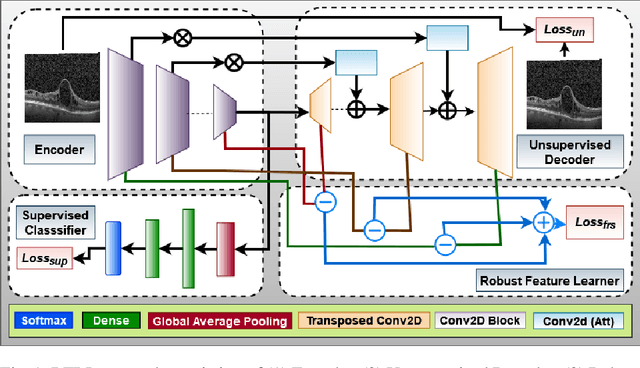
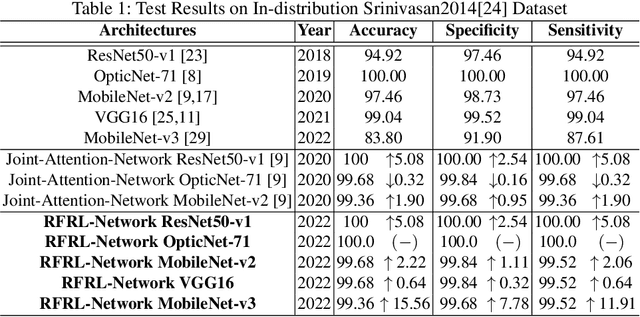
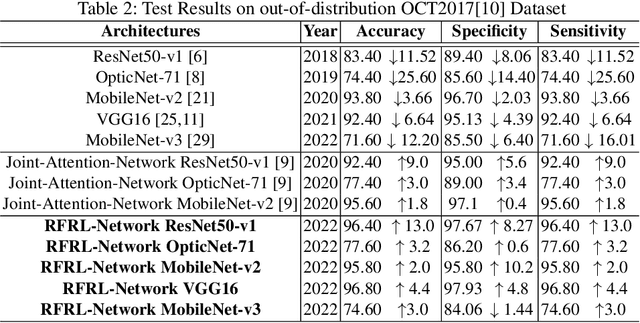
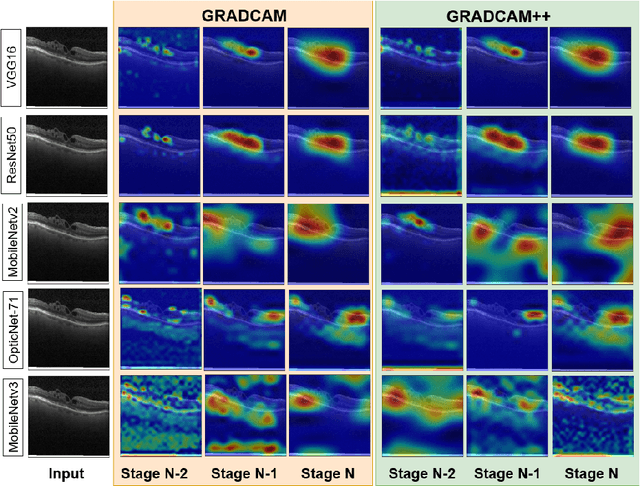
Ophthalmic images may contain identical-looking pathologies that can cause failure in automated techniques to distinguish different retinal degenerative diseases. Additionally, reliance on large annotated datasets and lack of knowledge distillation can restrict ML-based clinical support systems' deployment in real-world environments. To improve the robustness and transferability of knowledge, an enhanced feature-learning module is required to extract meaningful spatial representations from the retinal subspace. Such a module, if used effectively, can detect unique disease traits and differentiate the severity of such retinal degenerative pathologies. In this work, we propose a robust disease detection architecture with three learning heads, i) A supervised encoder for retinal disease classification, ii) An unsupervised decoder for the reconstruction of disease-specific spatial information, and iii) A novel representation learning module for learning the similarity between encoder-decoder feature and enhancing the accuracy of the model. Our experimental results on two publicly available OCT datasets illustrate that the proposed model outperforms existing state-of-the-art models in terms of accuracy, interpretability, and robustness for out-of-distribution retinal disease detection.