 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevolutionizing Space Health (Swin-FSR): Advancing Super-Resolution of Fundus Images for SANS Visual Assessment Technology
Aug 11, 2023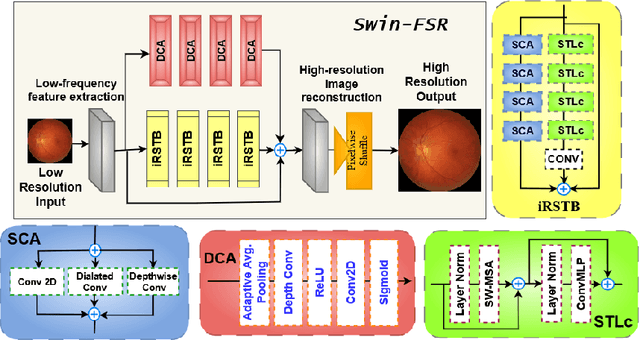
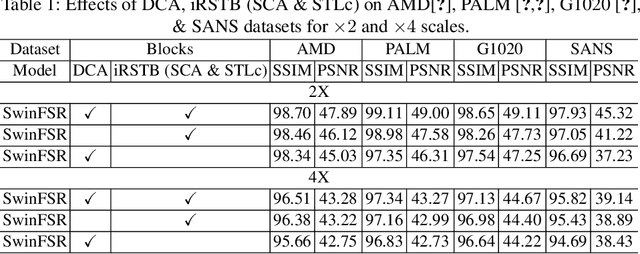
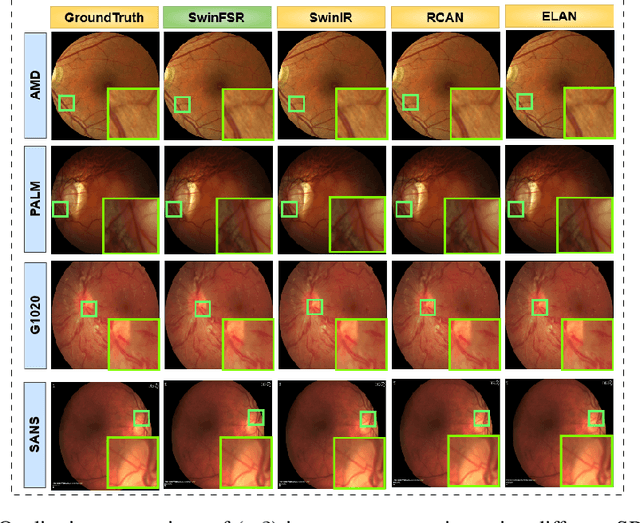
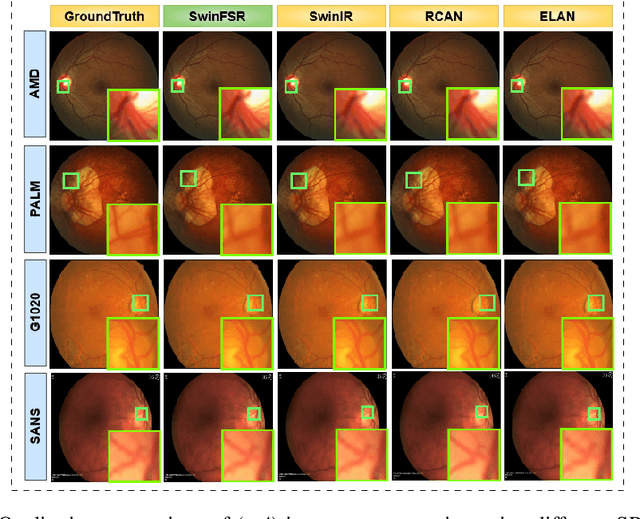
The rapid accessibility of portable and affordable retinal imaging devices has made early differential diagnosis easier. For example, color funduscopy imaging is readily available in remote villages, which can help to identify diseases like age-related macular degeneration (AMD), glaucoma, or pathological myopia (PM). On the other hand, astronauts at the International Space Station utilize this camera for identifying spaceflight-associated neuro-ocular syndrome (SANS). However, due to the unavailability of experts in these locations, the data has to be transferred to an urban healthcare facility (AMD and glaucoma) or a terrestrial station (e.g, SANS) for more precise disease identification. Moreover, due to low bandwidth limits, the imaging data has to be compressed for transfer between these two places. Different super-resolution algorithms have been proposed throughout the years to address this. Furthermore, with the advent of deep learning, the field has advanced so much that x2 and x4 compressed images can be decompressed to their original form without losing spatial information. In this paper, we introduce a novel model called Swin-FSR that utilizes Swin Transformer with spatial and depth-wise attention for fundus image super-resolution. Our architecture achieves Peak signal-to-noise-ratio (PSNR) of 47.89, 49.00 and 45.32 on three public datasets, namely iChallenge-AMD, iChallenge-PM, and G1020. Additionally, we tested the model's effectiveness on a privately held dataset for SANS provided by NASA and achieved comparable results against previous architectures.
SwinVFTR: A Novel Volumetric Feature-learning Transformer for 3D OCT Fluid Segmentation
Mar 17, 2023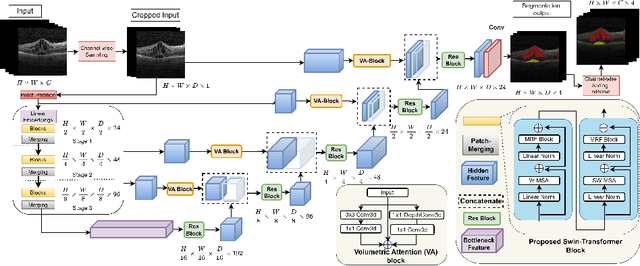
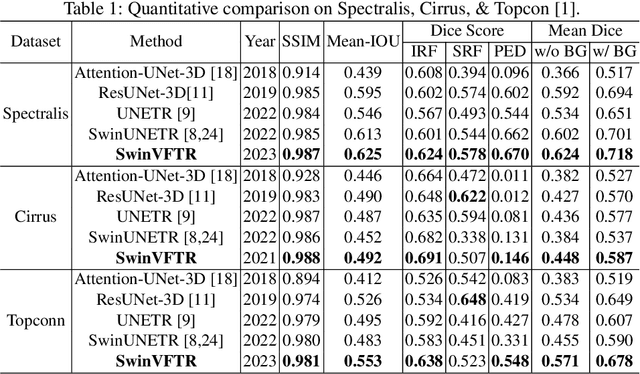
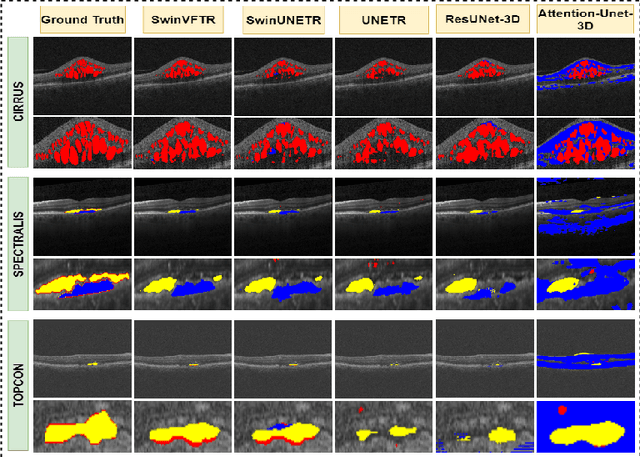
Accurately segmenting fluid in 3D volumetric optical coherence tomography (OCT) images is a crucial yet challenging task for detecting eye diseases. Traditional autoencoding-based segmentation approaches have limitations in extracting fluid regions due to successive resolution loss in the encoding phase and the inability to recover lost information in the decoding phase. Although current transformer-based models for medical image segmentation addresses this limitation, they are not designed to be applied out-of-the-box for 3D OCT volumes, which have a wide-ranging channel-axis size based on different vendor device and extraction technique. To address these issues, we propose SwinVFTR, a new transformer-based architecture designed for precise fluid segmentation in 3D volumetric OCT images. We first utilize a channel-wise volumetric sampling for training on OCT volumes with varying depths (B-scans). Next, the model uses a novel shifted window transformer block in the encoder to achieve better localization and segmentation of fluid regions. Additionally, we propose a new volumetric attention block for spatial and depth-wise attention, which improves upon traditional residual skip connections. Consequently, utilizing multi-class dice loss, the proposed architecture outperforms other existing architectures on the three publicly available vendor-specific OCT datasets, namely Spectralis, Cirrus, and Topcon, with mean dice scores of 0.72, 0.59, and 0.68, respectively. Additionally, SwinVFTR outperforms other architectures in two additional relevant metrics, mean intersection-over-union (Mean-IOU) and structural similarity measure (SSIM).
SWIN-SFTNet : Spatial Feature Expansion and Aggregation using Swin Transformer For Whole Breast micro-mass segmentation
Nov 16, 2022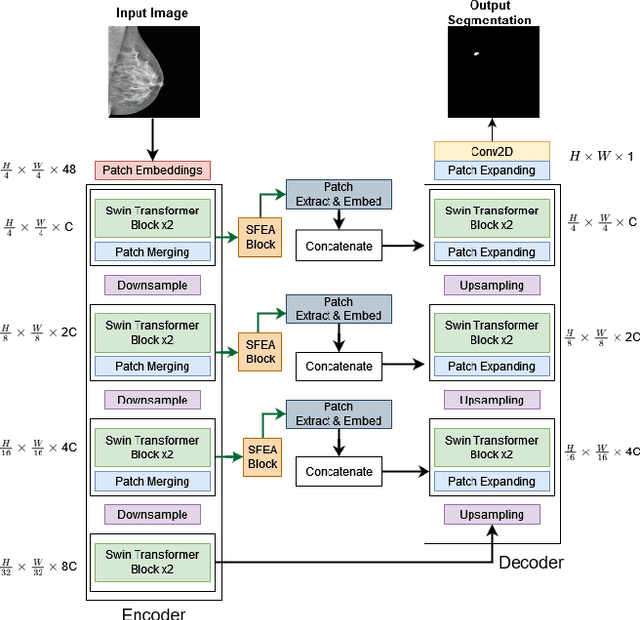
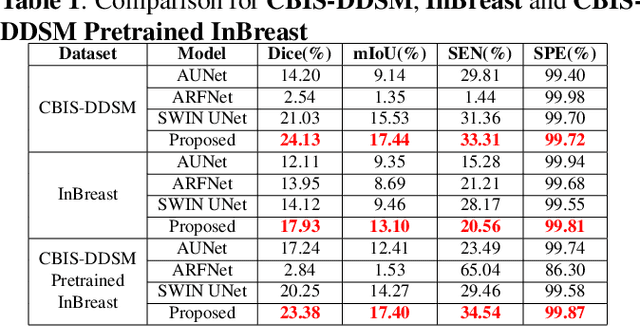
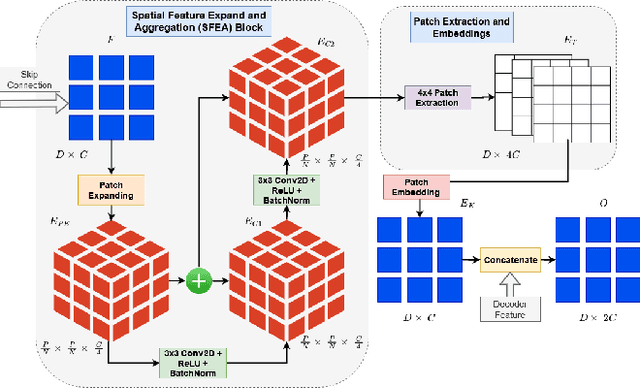

Incorporating various mass shapes and sizes in training deep learning architectures has made breast mass segmentation challenging. Moreover, manual segmentation of masses of irregular shapes is time-consuming and error-prone. Though Deep Neural Network has shown outstanding performance in breast mass segmentation, it fails in segmenting micro-masses. In this paper, we propose a novel U-net-shaped transformer-based architecture, called Swin-SFTNet, that outperforms state-of-the-art architectures in breast mammography-based micro-mass segmentation. Firstly to capture the global context, we designed a novel Spatial Feature Expansion and Aggregation Block(SFEA) that transforms sequential linear patches into a structured spatial feature. Next, we combine it with the local linear features extracted by the swin transformer block to improve overall accuracy. We also incorporate a novel embedding loss that calculates similarities between linear feature embeddings of the encoder and decoder blocks. With this approach, we achieve higher segmentation dice over the state-of-the-art by 3.10% on CBIS-DDSM, 3.81% on InBreast, and 3.13% on CBIS pre-trained model on the InBreast test data set.
Virtual-Reality based Vestibular Ocular Motor Screening for Concussion Detection using Machine-Learning
Oct 13, 2022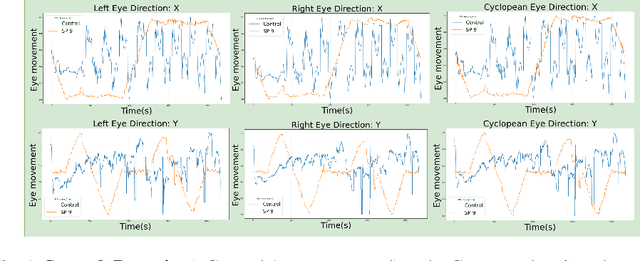

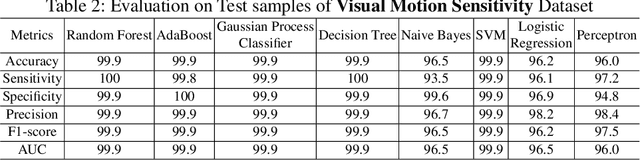
Sport-related concussion (SRC) depends on sensory information from visual, vestibular, and somatosensory systems. At the same time, the current clinical administration of Vestibular/Ocular Motor Screening (VOMS) is subjective and deviates among administrators. Therefore, for the assessment and management of concussion detection, standardization is required to lower the risk of injury and increase the validation among clinicians. With the advancement of technology, virtual reality (VR) can be utilized to advance the standardization of the VOMS, increasing the accuracy of testing administration and decreasing overall false positive rates. In this paper, we experimented with multiple machine learning methods to detect SRC on VR-generated data using VOMS. In our observation, the data generated from VR for smooth pursuit (SP) and the Visual Motion Sensitivity (VMS) tests are highly reliable for concussion detection. Furthermore, we train and evaluate these models, both qualitatively and quantitatively. Our findings show these models can reach high true-positive-rates of around 99.9 percent of symptom provocation on the VR stimuli-based VOMS vs. current clinical manual VOMS.
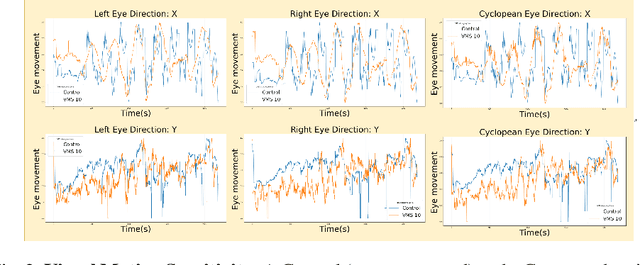
Analysis of Smooth Pursuit Assessment in Virtual Reality and Concussion Detection using BiLSTM
Oct 12, 2022
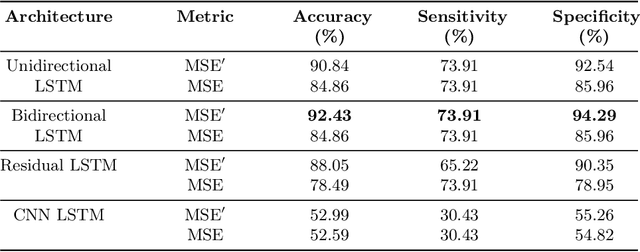
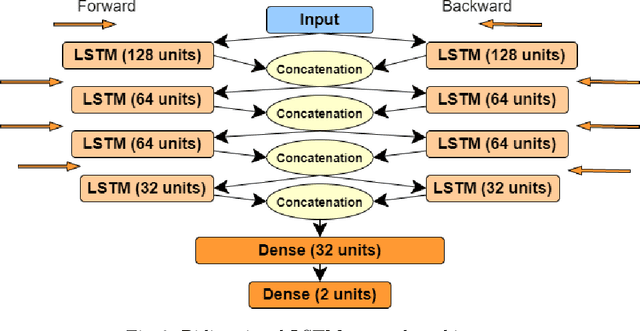
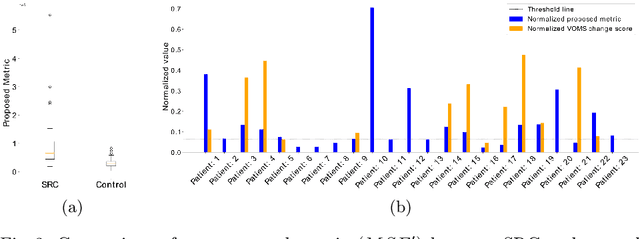
The sport-related concussion (SRC) battery relies heavily upon subjective symptom reporting in order to determine the diagnosis of a concussion. Unfortunately, athletes with SRC may return-to-play (RTP) too soon if they are untruthful of their symptoms. It is critical to provide accurate assessments that can overcome underreporting to prevent further injury. To lower the risk of injury, a more robust and precise method for detecting concussion is needed to produce reliable and objective results. In this paper, we propose a novel approach to detect SRC using long short-term memory (LSTM) recurrent neural network (RNN) architectures from oculomotor data. In particular, we propose a new error metric that incorporates mean squared error in different proportions. The experimental results on the smooth pursuit test of the VR-VOMS dataset suggest that the proposed approach can predict concussion symptoms with higher accuracy compared to symptom provocation on the vestibular ocular motor screening (VOMS).
Feature Representation Learning for Robust Retinal Disease Detection from Optical Coherence Tomography Images
Jun 24, 2022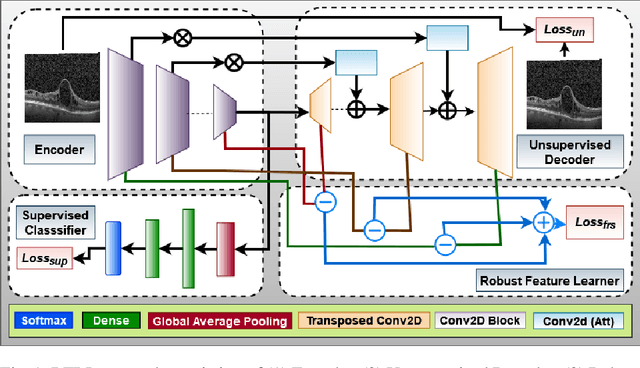
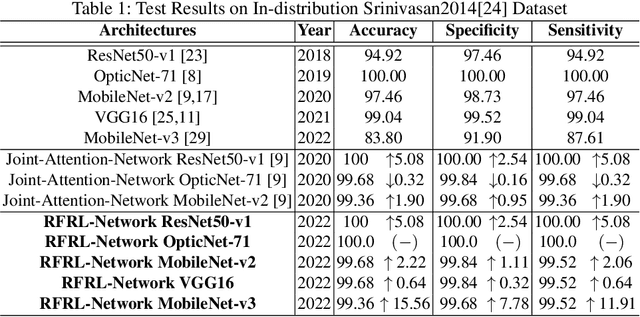
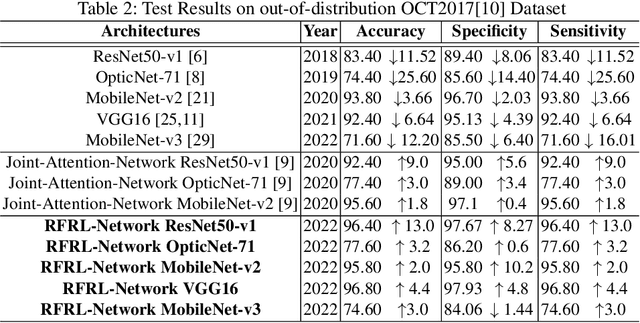
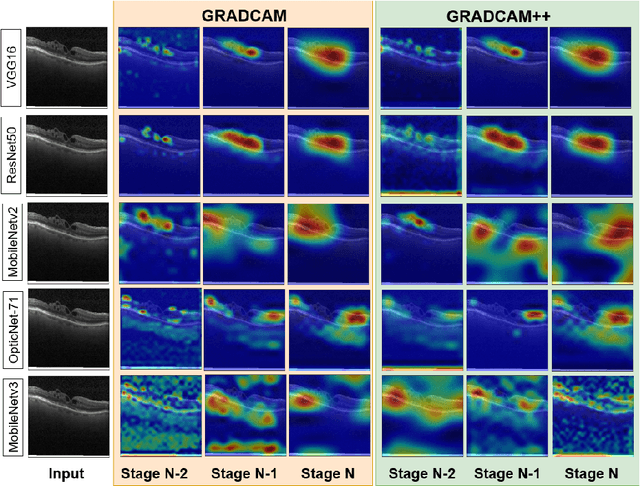
Ophthalmic images may contain identical-looking pathologies that can cause failure in automated techniques to distinguish different retinal degenerative diseases. Additionally, reliance on large annotated datasets and lack of knowledge distillation can restrict ML-based clinical support systems' deployment in real-world environments. To improve the robustness and transferability of knowledge, an enhanced feature-learning module is required to extract meaningful spatial representations from the retinal subspace. Such a module, if used effectively, can detect unique disease traits and differentiate the severity of such retinal degenerative pathologies. In this work, we propose a robust disease detection architecture with three learning heads, i) A supervised encoder for retinal disease classification, ii) An unsupervised decoder for the reconstruction of disease-specific spatial information, and iii) A novel representation learning module for learning the similarity between encoder-decoder feature and enhancing the accuracy of the model. Our experimental results on two publicly available OCT datasets illustrate that the proposed model outperforms existing state-of-the-art models in terms of accuracy, interpretability, and robustness for out-of-distribution retinal disease detection.
ECG-ATK-GAN: Robustness against Adversarial Attacks on ECG using Conditional Generative Adversarial Networks
Oct 17, 2021

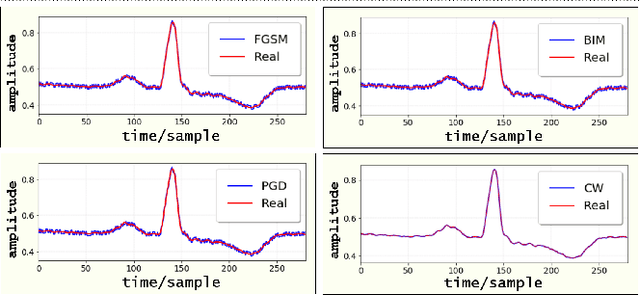
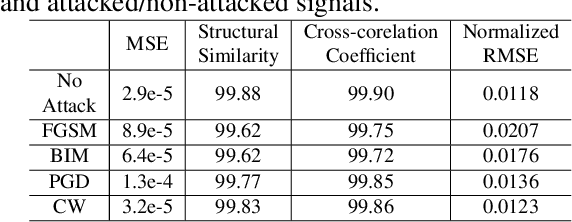
Recently deep learning has reached human-level performance in classifying arrhythmia from Electrocardiogram (ECG). However, deep neural networks (DNN) are vulnerable to adversarial attacks, which can misclassify ECG signals by decreasing the model's precision. Adversarial attacks are crafted perturbations injected in data that manifest the conventional DNN models to misclassify the correct class. Thus, safety concerns arise as it becomes challenging to establish the system's reliability, given that clinical applications require high levels of trust. To mitigate this problem and make DNN models more robust in clinical and real-life settings, we introduce a novel Conditional Generative Adversarial Network (GAN), robust against adversarial attacked ECG signals and retaining high accuracy. Furthermore, we compared it with other state-of-art models to detect cardiac abnormalities from indistinguishable adversarial attacked ECGs. The experiment confirms, our model is more robust against adversarial attacks compared to other architectures.
ECG-Adv-GAN: Detecting ECG Adversarial Examples with Conditional Generative Adversarial Networks
Jul 16, 2021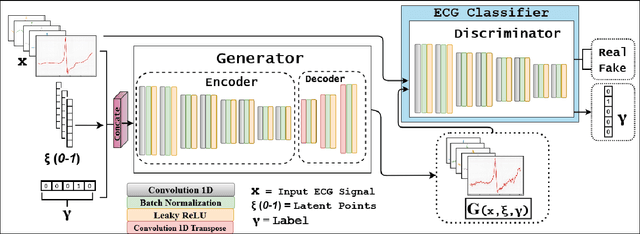
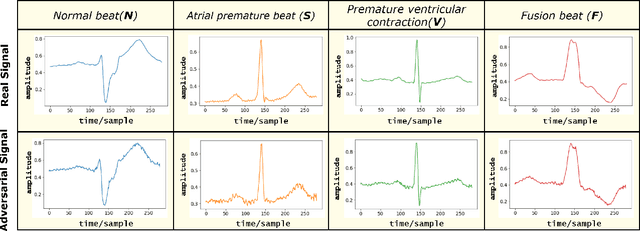
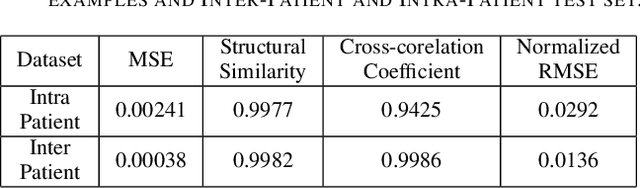
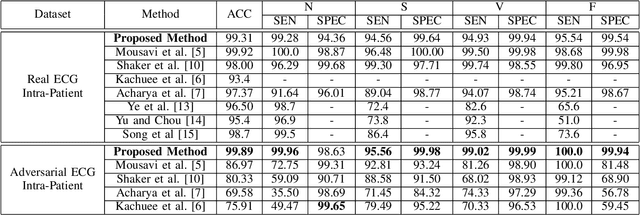
Electrocardiogram (ECG) acquisition requires an automated system and analysis pipeline for understanding specific rhythm irregularities. Deep neural networks have become a popular technique for tracing ECG signals, outperforming human experts. Despite this, convolutional neural networks are susceptible to adversarial examples that can misclassify ECG signals and decrease the model's precision. Moreover, they do not generalize well on the out-of-distribution dataset. The GAN architecture has been employed in recent works to synthesize adversarial ECG signals to increase existing training data. However, they use a disjointed CNN-based classification architecture to detect arrhythmia. Till now, no versatile architecture has been proposed that can detect adversarial examples and classify arrhythmia simultaneously. To alleviate this, we propose a novel Conditional Generative Adversarial Network to simultaneously generate ECG signals for different categories and detect cardiac abnormalities. Moreover, the model is conditioned on class-specific ECG signals to synthesize realistic adversarial examples. Consequently, we compare our architecture and show how it outperforms other classification models in normal/abnormal ECG signal detection by benchmarking real world and adversarial signals.
VTGAN: Semi-supervised Retinal Image Synthesis and Disease Prediction using Vision Transformers
Apr 14, 2021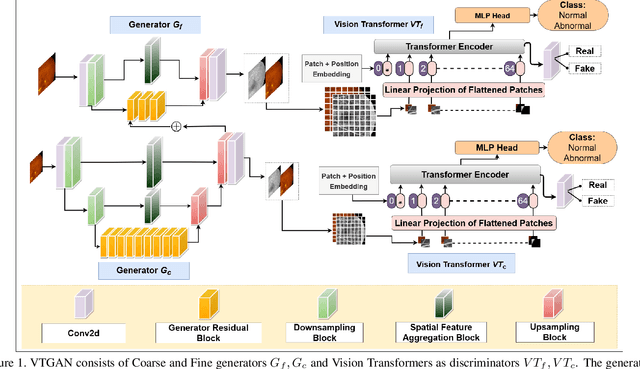
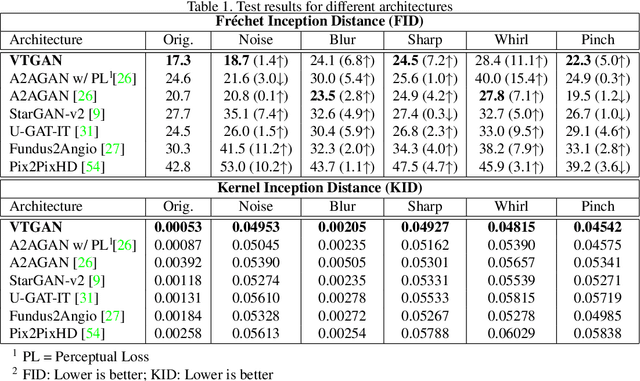
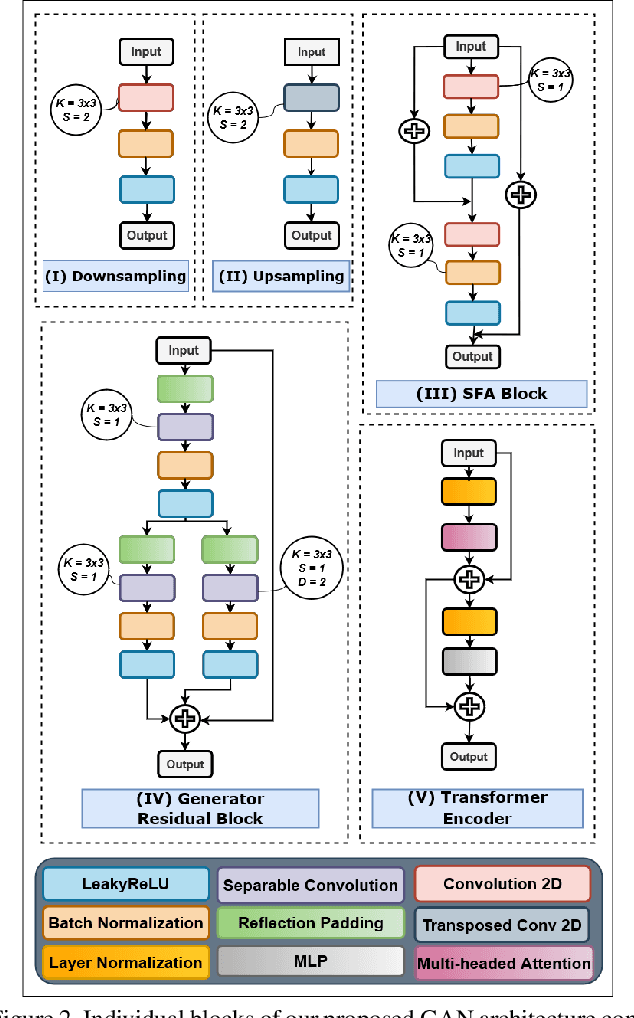
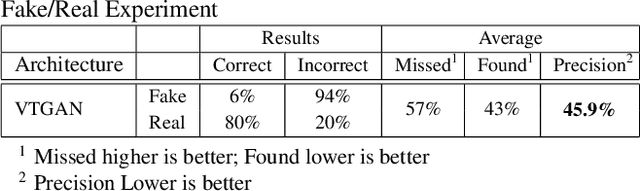
In Fluorescein Angiography (FA), an exogenous dye is injected in the bloodstream to image the vascular structure of the retina. The injected dye can cause adverse reactions such as nausea, vomiting, anaphylactic shock, and even death. In contrast, color fundus imaging is a non-invasive technique used for photographing the retina but does not have sufficient fidelity for capturing its vascular structure. The only non-invasive method for capturing retinal vasculature is optical coherence tomography-angiography (OCTA). However, OCTA equipment is quite expensive, and stable imaging is limited to small areas on the retina. In this paper, we propose a novel conditional generative adversarial network (GAN) capable of simultaneously synthesizing FA images from fundus photographs while predicting retinal degeneration. The proposed system has the benefit of addressing the problem of imaging retinal vasculature in a non-invasive manner as well as predicting the existence of retinal abnormalities. We use a semi-supervised approach to train our GAN using multiple weighted losses on different modalities of data. Our experiments validate that the proposed architecture exceeds recent state-of-the-art generative networks for fundus-to-angiography synthesis. Moreover, our vision transformer-based discriminators generalize quite well on out-of-distribution data sets for retinal disease prediction.
RV-GAN : Retinal Vessel Segmentation from Fundus Images using Multi-scale Generative Adversarial Networks
Jan 03, 2021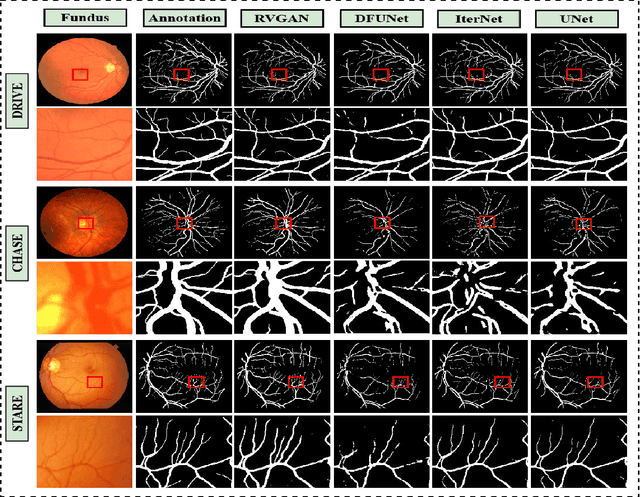
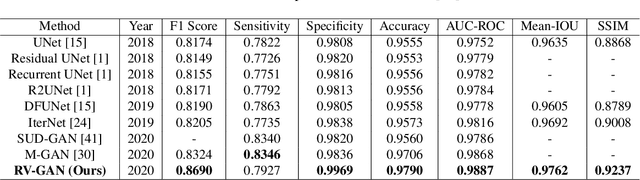
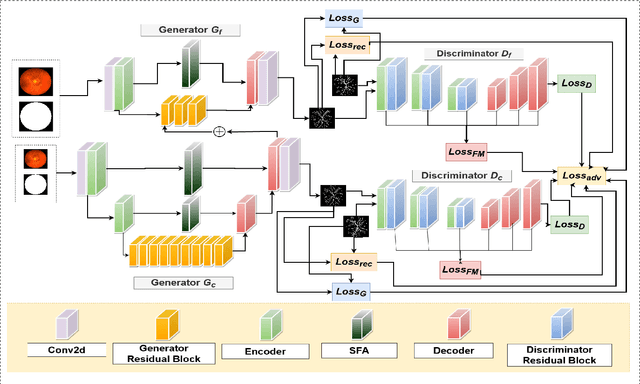
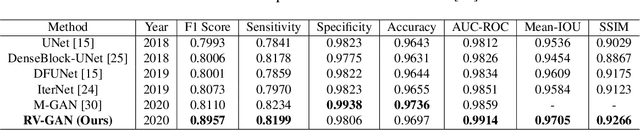
Retinal vessel segmentation contributes significantly to the domain of retinal image analysis for the diagnosis of vision-threatening diseases. With existing techniques the generated segmentation result deteriorates when thresholded with higher confidence value. To alleviate from this, we propose RVGAN, a new multi-scale generative architecture for accurate retinal vessel segmentation. Our architecture uses two generators and two multi-scale autoencoder based discriminators, for better microvessel localization and segmentation. By combining reconstruction and weighted feature matching loss, our adversarial training scheme generates highly accurate pixel-wise segmentation of retinal vessels with threshold >= 0.5. The architecture achieves AUC of 0.9887, 0.9814, and 0.9887 on three publicly available datasets, namely DRIVE, CHASE-DB1, and STARE, respectively. Additionally, RV-GAN outperforms other architectures in two additional relevant metrics, Mean-IOU and SSIM.