 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Prompt Ensemble for Reliable Medical Entity Recognition from EHRs
May 13, 2025Electronic Health Records (EHRs) are digital records of patient information, often containing unstructured clinical text. Named Entity Recognition (NER) is essential in EHRs for extracting key medical entities like problems, tests, and treatments to support downstream clinical applications. This paper explores prompt-based medical entity recognition using large language models (LLMs), specifically GPT-4o and DeepSeek-R1, guided by various prompt engineering techniques, including zero-shot, few-shot, and an ensemble approach. Among all strategies, GPT-4o with prompt ensemble achieved the highest classification performance with an F1-score of 0.95 and recall of 0.98, outperforming DeepSeek-R1 on the task. The ensemble method improved reliability by aggregating outputs through embedding-based similarity and majority voting.
How Reliable AI Chatbots are for Disease Prediction from Patient Complaints?
May 21, 2024Artificial Intelligence (AI) chatbots leveraging Large Language Models (LLMs) are gaining traction in healthcare for their potential to automate patient interactions and aid clinical decision-making. This study examines the reliability of AI chatbots, specifically GPT 4.0, Claude 3 Opus, and Gemini Ultra 1.0, in predicting diseases from patient complaints in the emergency department. The methodology includes few-shot learning techniques to evaluate the chatbots' effectiveness in disease prediction. We also fine-tune the transformer-based model BERT and compare its performance with the AI chatbots. Results suggest that GPT 4.0 achieves high accuracy with increased few-shot data, while Gemini Ultra 1.0 performs well with fewer examples, and Claude 3 Opus maintains consistent performance. BERT's performance, however, is lower than all the chatbots, indicating limitations due to limited labeled data. Despite the chatbots' varying accuracy, none of them are sufficiently reliable for critical medical decision-making, underscoring the need for rigorous validation and human oversight. This study reflects that while AI chatbots have potential in healthcare, they should complement, not replace, human expertise to ensure patient safety. Further refinement and research are needed to improve AI-based healthcare applications' reliability for disease prediction.
Enabling Multi-Agent Transfer Reinforcement Learning via Scenario Independent Representation
Feb 13, 2024



Multi-Agent Reinforcement Learning (MARL) algorithms are widely adopted in tackling complex tasks that require collaboration and competition among agents in dynamic Multi-Agent Systems (MAS). However, learning such tasks from scratch is arduous and may not always be feasible, particularly for MASs with a large number of interactive agents due to the extensive sample complexity. Therefore, reusing knowledge gained from past experiences or other agents could efficiently accelerate the learning process and upscale MARL algorithms. In this study, we introduce a novel framework that enables transfer learning for MARL through unifying various state spaces into fixed-size inputs that allow one unified deep-learning policy viable in different scenarios within a MAS. We evaluated our approach in a range of scenarios within the StarCraft Multi-Agent Challenge (SMAC) environment, and the findings show significant enhancements in multi-agent learning performance using maneuvering skills learned from other scenarios compared to agents learning from scratch. Furthermore, we adopted Curriculum Transfer Learning (CTL), enabling our deep learning policy to progressively acquire knowledge and skills across pre-designed homogeneous learning scenarios organized by difficulty levels. This process promotes inter- and intra-agent knowledge transfer, leading to high multi-agent learning performance in more complicated heterogeneous scenarios.
MAIDCRL: Semi-centralized Multi-Agent Influence Dense-CNN Reinforcement Learning
Feb 12, 2024



Distributed decision-making in multi-agent systems presents difficult challenges for interactive behavior learning in both cooperative and competitive systems. To mitigate this complexity, MAIDRL presents a semi-centralized Dense Reinforcement Learning algorithm enhanced by agent influence maps (AIMs), for learning effective multi-agent control on StarCraft Multi-Agent Challenge (SMAC) scenarios. In this paper, we extend the DenseNet in MAIDRL and introduce semi-centralized Multi-Agent Dense-CNN Reinforcement Learning, MAIDCRL, by incorporating convolutional layers into the deep model architecture, and evaluate the performance on both homogeneous and heterogeneous scenarios. The results show that the CNN-enabled MAIDCRL significantly improved the learning performance and achieved a faster learning rate compared to the existing MAIDRL, especially on more complicated heterogeneous SMAC scenarios. We further investigate the stability and robustness of our model. The statistics reflect that our model not only achieves higher winning rate in all the given scenarios but also boosts the agent's learning process in fine-grained decision-making.
Autocompletion of Chief Complaints in the Electronic Health Records using Large Language Models
Jan 11, 2024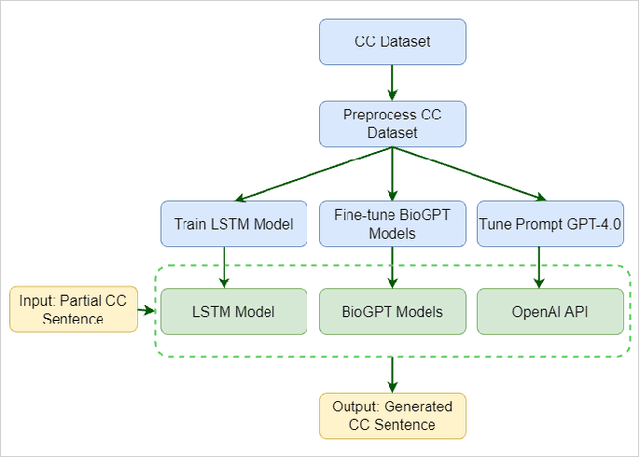
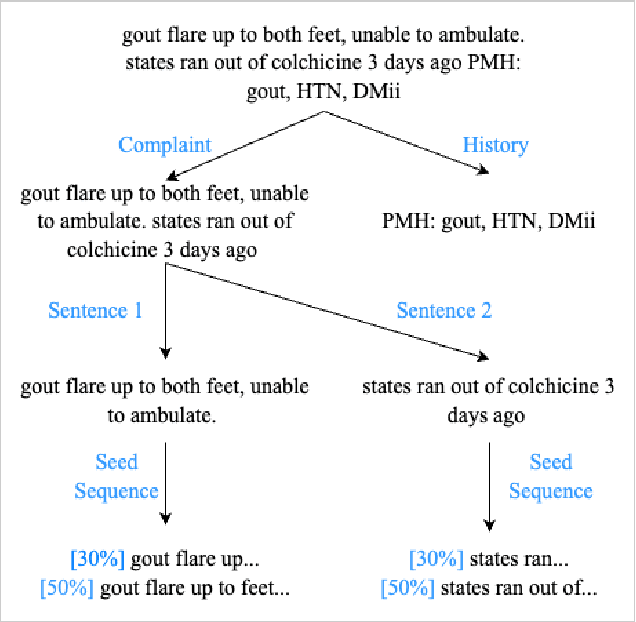


The Chief Complaint (CC) is a crucial component of a patient's medical record as it describes the main reason or concern for seeking medical care. It provides critical information for healthcare providers to make informed decisions about patient care. However, documenting CCs can be time-consuming for healthcare providers, especially in busy emergency departments. To address this issue, an autocompletion tool that suggests accurate and well-formatted phrases or sentences for clinical notes can be a valuable resource for triage nurses. In this study, we utilized text generation techniques to develop machine learning models using CC data. In our proposed work, we train a Long Short-Term Memory (LSTM) model and fine-tune three different variants of Biomedical Generative Pretrained Transformers (BioGPT), namely microsoft/biogpt, microsoft/BioGPT-Large, and microsoft/BioGPT-Large-PubMedQA. Additionally, we tune a prompt by incorporating exemplar CC sentences, utilizing the OpenAI API of GPT-4. We evaluate the models' performance based on the perplexity score, modified BERTScore, and cosine similarity score. The results show that BioGPT-Large exhibits superior performance compared to the other models. It consistently achieves a remarkably low perplexity score of 1.65 when generating CC, whereas the baseline LSTM model achieves the best perplexity score of 170. Further, we evaluate and assess the proposed models' performance and the outcome of GPT-4.0. Our study demonstrates that utilizing LLMs such as BioGPT, leads to the development of an effective autocompletion tool for generating CC documentation in healthcare settings.