 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPEX, A Framework For Interpreting Artificial Neural Networks
Paper and Code

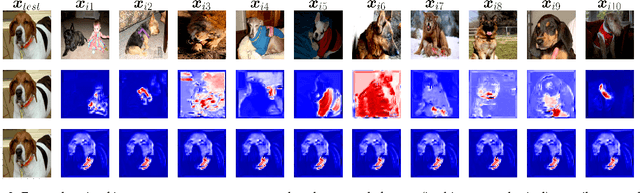
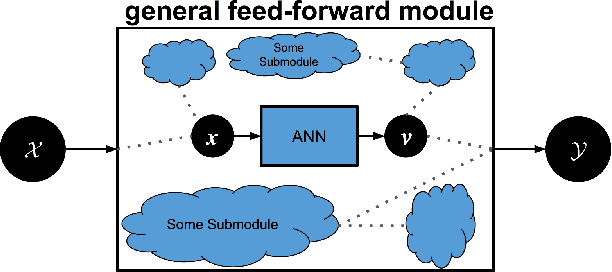
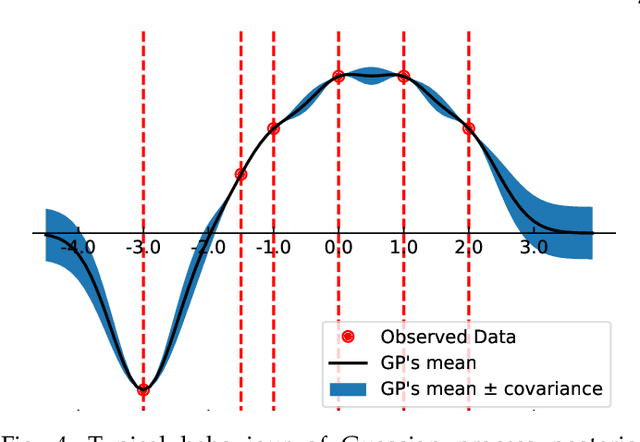
Machine learning researchers have long noted a trade-off between interpretability and prediction performance. On the one hand, traditional models are often interpretable to humans but they cannot achieve high prediction performances. At the opposite end of the spectrum, deep models can achieve state-of-the-art performances in many tasks. However, deep models' predictions are known to be uninterpretable to humans. In this paper we present a framework that shortens the gap between the two aforementioned groups of methods. Given an artificial neural network (ANN), our method finds a Gaussian process (GP) whose predictions almost match those of the ANN. As GPs are highly interpretable, we use the trained GP to explain the ANN's decisions. We use our method to explain ANNs' decisions on may datasets. The explanations provide intriguing insights about the ANNs' decisions. With the best of our knowledge, our inference formulation for GPs is the first one in which an ANN and a similarly behaving Gaussian process naturally appear. Furthermore, we examine some of the known theoretical conditions under which an ANN is interpretable by GPs. Some of those theoretical conditions are too restrictive for modern architectures. However, we hypothesize that only a subset of those theoretical conditions are sufficient. Finally, we implement our framework as a publicly available tool called GPEX. Given any pytorch feed-forward module, GPEX allows users to interpret any ANN subcomponent of the module effortlessly and without having to be involved in the inference algorithm. GPEX is publicly available online:www.github.com/Nilanjan-Ray/gpex