 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplicity Prevails: Rethinking Negative Preference Optimization for LLM Unlearning
Paper and Code
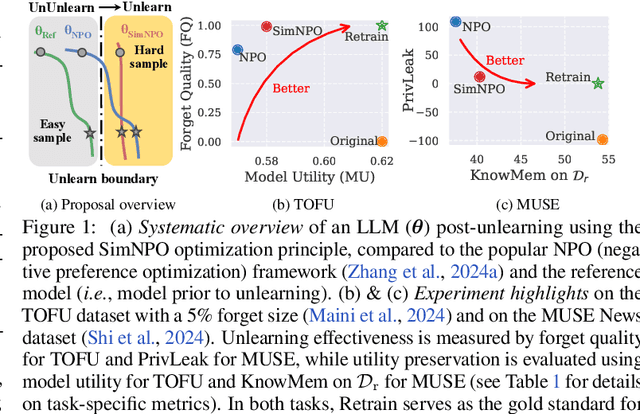
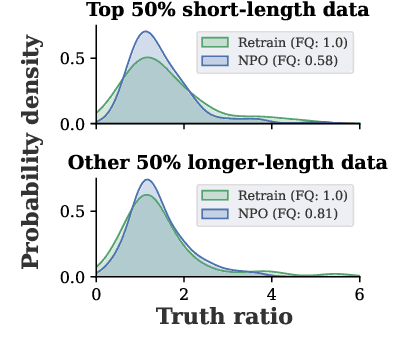
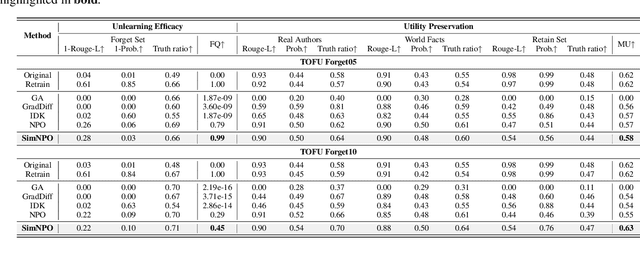
In this work, we address the problem of large language model (LLM) unlearning, aiming to remove unwanted data influences and associated model capabilities (e.g., copyrighted data or harmful content generation) while preserving essential model utilities, without the need for retraining from scratch. Despite the growing need for LLM unlearning, a principled optimization framework remains lacking. To this end, we revisit the state-of-the-art approach, negative preference optimization (NPO), and identify the issue of reference model bias, which could undermine NPO's effectiveness, particularly when unlearning forget data of varying difficulty. Given that, we propose a simple yet effective unlearning optimization framework, called SimNPO, showing that 'simplicity' in removing the reliance on a reference model (through the lens of simple preference optimization) benefits unlearning. We also provide deeper insights into SimNPO's advantages, supported by analysis using mixtures of Markov chains. Furthermore, we present extensive experiments validating SimNPO's superiority over existing unlearning baselines in benchmarks like TOFU and MUSE, and robustness against relearning attacks. Codes are available at https://github.com/OPTML-Group/Unlearn-Simple.