 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-MTLLMF: Resilient Multi-Task Large Language Model Fusion at the Wireless Edge
Nov 27, 2024



Multi-task large language models (MTLLMs) are important for many applications at the wireless edge, where users demand specialized models to handle multiple tasks efficiently. However, training MTLLMs is complex and exhaustive, particularly when tasks are subject to change. Recently, the concept of model fusion via task vectors has emerged as an efficient approach for combining fine-tuning parameters to produce an MTLLM. In this paper, the problem of enabling edge users to collaboratively craft such MTTLMs via tasks vectors is studied, under the assumption of worst-case adversarial attacks. To this end, first the influence of adversarial noise to multi-task model fusion is investigated and a relationship between the so-called weight disentanglement error and the mean squared error (MSE) is derived. Using hypothesis testing, it is directly shown that the MSE increases interference between task vectors, thereby rendering model fusion ineffective. Then, a novel resilient MTLLM fusion (R-MTLLMF) is proposed, which leverages insights about the LLM architecture and fine-tuning process to safeguard task vector aggregation under adversarial noise by realigning the MTLLM. The proposed R-MTLLMF is then compared for both worst-case and ideal transmission scenarios to study the impact of the wireless channel. Extensive model fusion experiments with vision LLMs demonstrate R-MTLLMF's effectiveness, achieving close-to-baseline performance across eight different tasks in ideal noise scenarios and significantly outperforming unprotected model fusion in worst-case scenarios. The results further advocate for additional physical layer protection for a holistic approach to resilience, from both a wireless and LLM perspective.
AI-Based Secure NOMA and Cognitive Radio enabled Green Communications: Channel State Information and Battery Value Uncertainties
Jun 30, 2021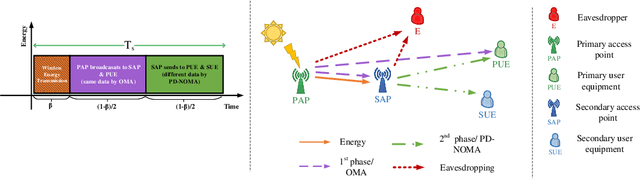
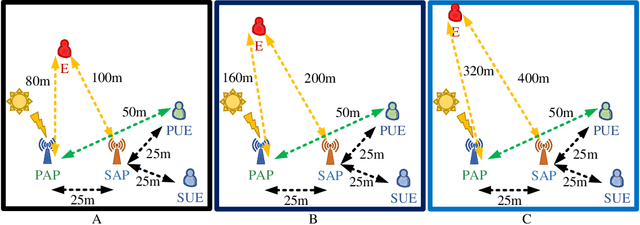
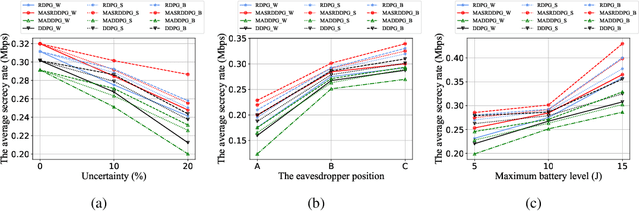
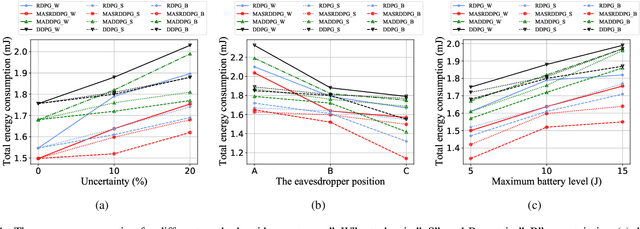
In this paper, the security-aware robust resource allocation in energy harvesting cognitive radio networks is considered with cooperation between two transmitters while there are uncertainties in channel gains and battery energy value. To be specific, the primary access point harvests energy from the green resource and uses time switching protocol to send the energy and data towards the secondary access point (SAP). Using power-domain non-orthogonal multiple access technique, the SAP helps the primary network to improve the security of data transmission by using the frequency band of the primary network. In this regard, we introduce the problem of maximizing the proportional-fair energy efficiency (PFEE) considering uncertainty in the channel gains and battery energy value subject to the practical constraints. Moreover, the channel gain of the eavesdropper is assumed to be unknown. Employing the decentralized partially observable Markov decision process, we investigate the solution of the corresponding resource allocation problem. We exploit multi-agent with single reward deep deterministic policy gradient (MASRDDPG) and recurrent deterministic policy gradient (RDPG) methods. These methods are compared with the state-of-the-art ones like multi-agent and single-agent DDPG. Simulation results show that both MASRDDPG and RDPG methods, outperform the state-of-the-art methods by providing more PFEE to the network.
AI-Based and Mobility-Aware Energy Efficient Resource Allocation and Trajectory Design for NFV Enabled Aerial Networks
May 21, 2021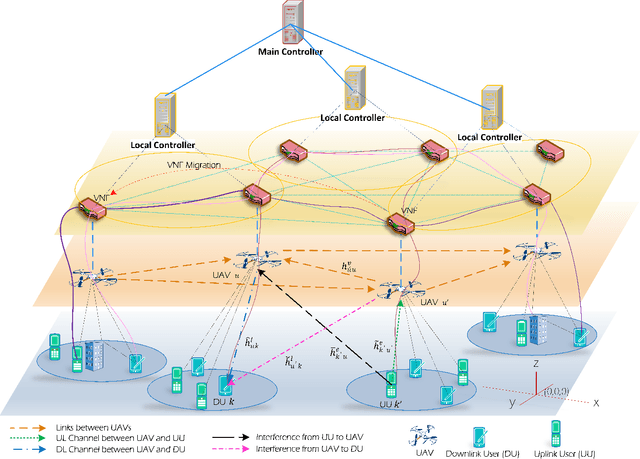
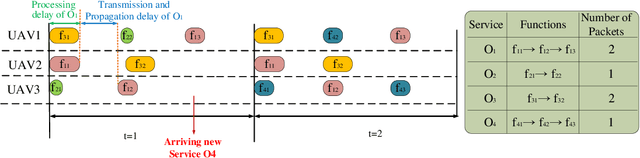
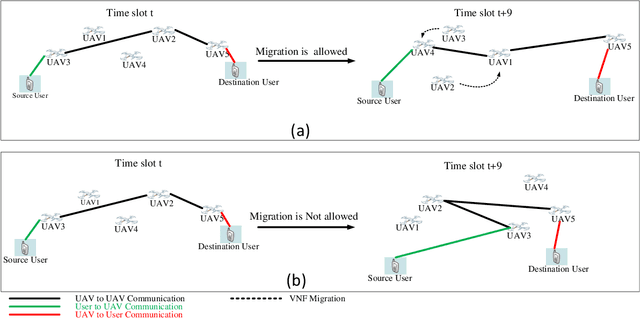
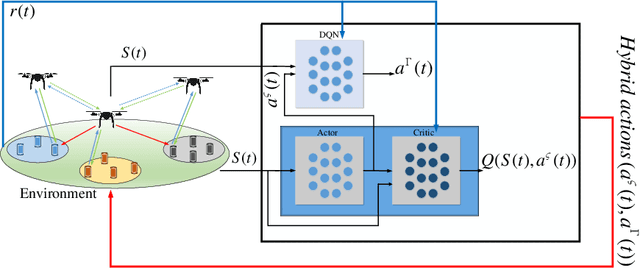
In this paper, we propose a novel joint intelligent trajectory design and resource allocation algorithm based on user's mobility and their requested services for unmanned aerial vehicles (UAVs) assisted networks, where UAVs act as nodes of a network function virtualization (NFV) enabled network. Our objective is to maximize energy efficiency and minimize the average delay on all services by allocating the limited radio and NFV resources. In addition, due to the traffic conditions and mobility of users, we let some Virtual Network Functions (VNFs) to migrate from their current locations to other locations to satisfy the Quality of Service requirements. We formulate our problem to find near-optimal locations of UAVs, transmit power, subcarrier assignment, placement, and scheduling the requested service's functions over the UAVs and perform suitable VNF migration. Then we propose a novel Hierarchical Hybrid Continuous and Discrete Action (HHCDA) deep reinforcement learning method to solve our problem. Finally, the convergence and computational complexity of the proposed algorithm and its performance analyzed for different parameters. Simulation results show that our proposed HHCDA method decreases the request reject rate and average delay by 31.5% and 20% and increases the energy efficiency by 40% compared to DDPG method.
Age of Information Aware VNF Scheduling in Industrial IoT Using Deep Reinforcement Learning
May 10, 2021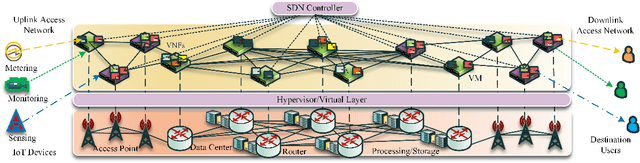
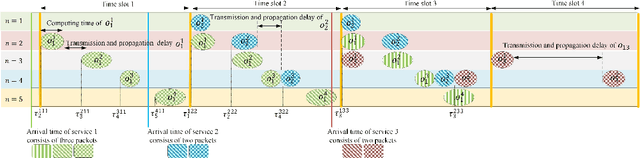
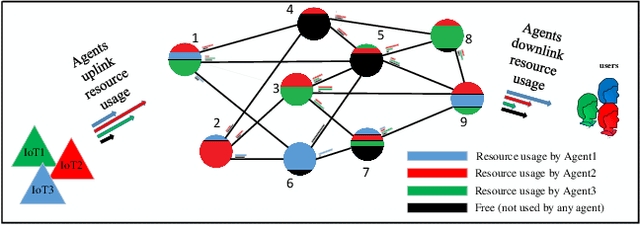
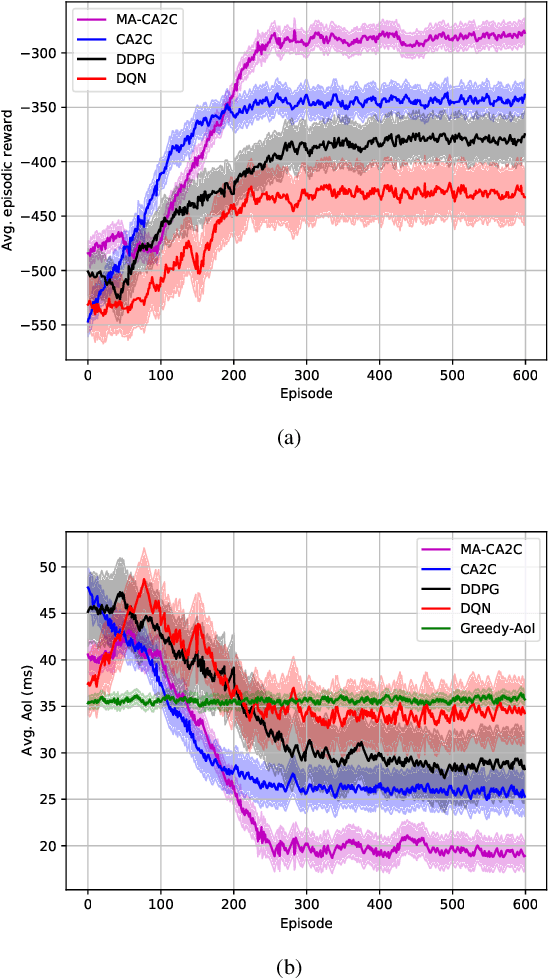
In delay-sensitive industrial internet of things (IIoT) applications, the age of information (AoI) is employed to characterize the freshness of information. Meanwhile, the emerging network function virtualization provides flexibility and agility for service providers to deliver a given network service using a sequence of virtual network functions (VNFs). However, suitable VNF placement and scheduling in these schemes is NP-hard and finding a globally optimal solution by traditional approaches is complex. Recently, deep reinforcement learning (DRL) has appeared as a viable way to solve such problems. In this paper, we first utilize single agent low-complex compound action actor-critic RL to cover both discrete and continuous actions and jointly minimize VNF cost and AoI in terms of network resources under end-to end Quality of Service constraints. To surmount the single-agent capacity limitation for learning, we then extend our solution to a multi-agent DRL scheme in which agents collaborate with each other. Simulation results demonstrate that single-agent schemes significantly outperform the greedy algorithm in terms of average network cost and AoI. Moreover, multi-agent solution decreases the average cost by dividing the tasks between the agents. However, it needs more iterations to be learned due to the requirement on the agents collaboration.