 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Based and Mobility-Aware Energy Efficient Resource Allocation and Trajectory Design for NFV Enabled Aerial Networks
May 21, 2021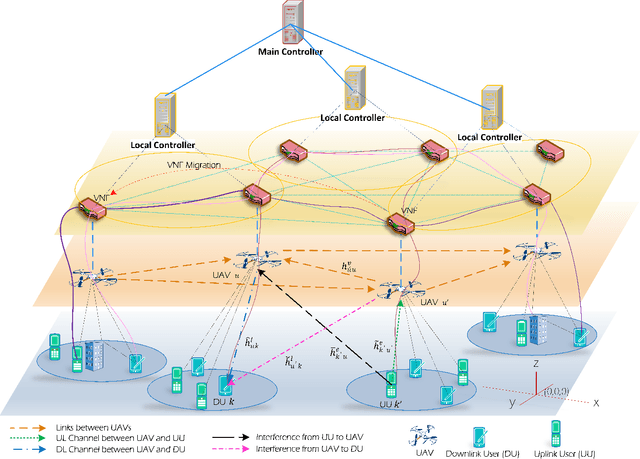
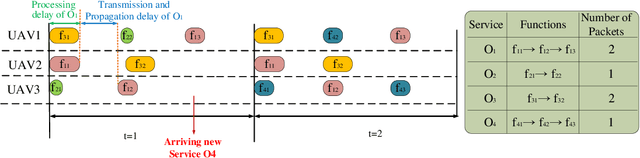
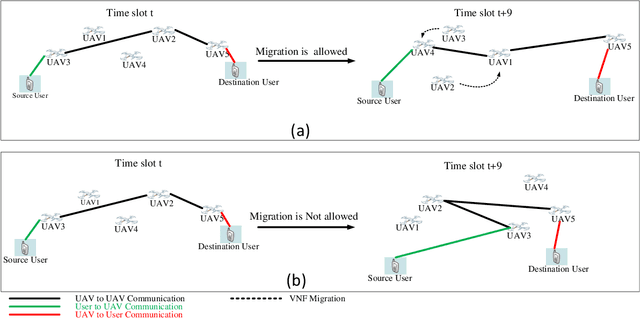
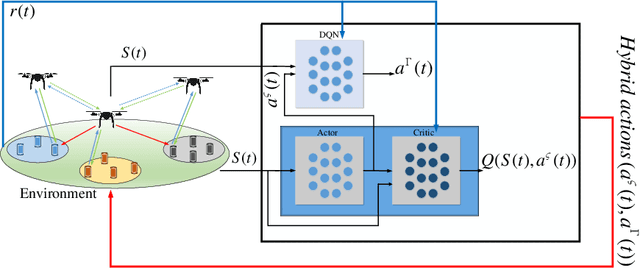
In this paper, we propose a novel joint intelligent trajectory design and resource allocation algorithm based on user's mobility and their requested services for unmanned aerial vehicles (UAVs) assisted networks, where UAVs act as nodes of a network function virtualization (NFV) enabled network. Our objective is to maximize energy efficiency and minimize the average delay on all services by allocating the limited radio and NFV resources. In addition, due to the traffic conditions and mobility of users, we let some Virtual Network Functions (VNFs) to migrate from their current locations to other locations to satisfy the Quality of Service requirements. We formulate our problem to find near-optimal locations of UAVs, transmit power, subcarrier assignment, placement, and scheduling the requested service's functions over the UAVs and perform suitable VNF migration. Then we propose a novel Hierarchical Hybrid Continuous and Discrete Action (HHCDA) deep reinforcement learning method to solve our problem. Finally, the convergence and computational complexity of the proposed algorithm and its performance analyzed for different parameters. Simulation results show that our proposed HHCDA method decreases the request reject rate and average delay by 31.5% and 20% and increases the energy efficiency by 40% compared to DDPG method.
Age of Information Aware VNF Scheduling in Industrial IoT Using Deep Reinforcement Learning
May 10, 2021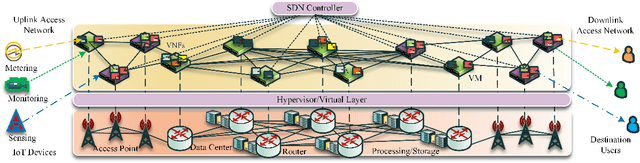
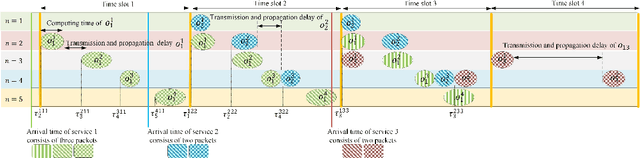
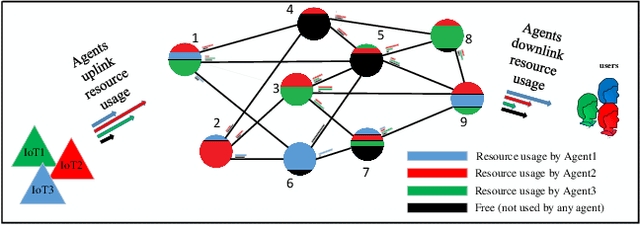
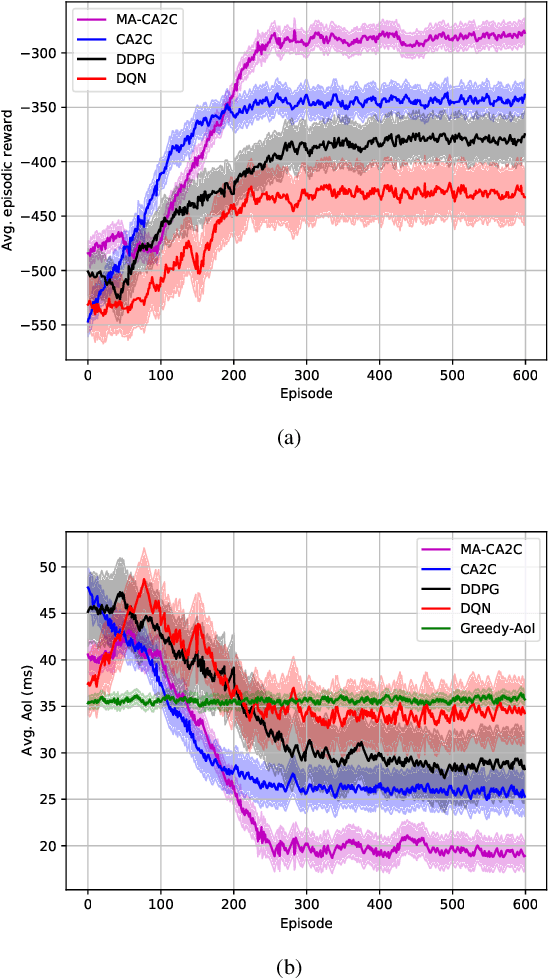
In delay-sensitive industrial internet of things (IIoT) applications, the age of information (AoI) is employed to characterize the freshness of information. Meanwhile, the emerging network function virtualization provides flexibility and agility for service providers to deliver a given network service using a sequence of virtual network functions (VNFs). However, suitable VNF placement and scheduling in these schemes is NP-hard and finding a globally optimal solution by traditional approaches is complex. Recently, deep reinforcement learning (DRL) has appeared as a viable way to solve such problems. In this paper, we first utilize single agent low-complex compound action actor-critic RL to cover both discrete and continuous actions and jointly minimize VNF cost and AoI in terms of network resources under end-to end Quality of Service constraints. To surmount the single-agent capacity limitation for learning, we then extend our solution to a multi-agent DRL scheme in which agents collaborate with each other. Simulation results demonstrate that single-agent schemes significantly outperform the greedy algorithm in terms of average network cost and AoI. Moreover, multi-agent solution decreases the average cost by dividing the tasks between the agents. However, it needs more iterations to be learned due to the requirement on the agents collaboration.