 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-based Radio Resource Management and Trajectory Design for PD-NOMA Communication in IRS-UAV Assisted Networks
Nov 06, 2021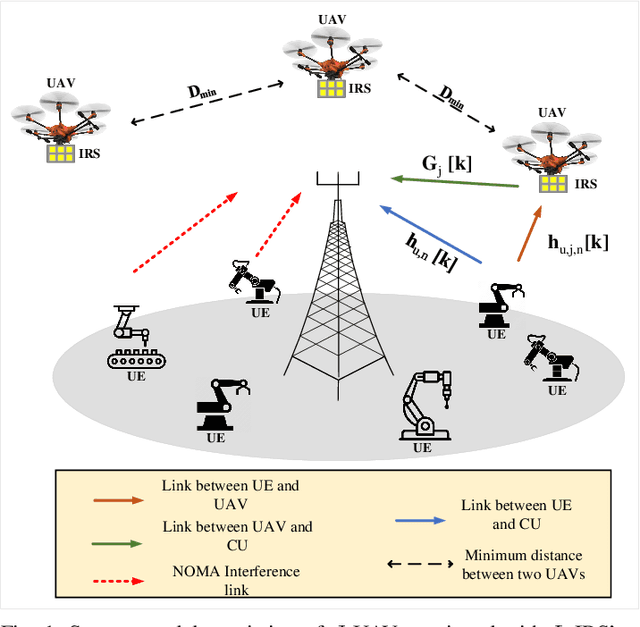
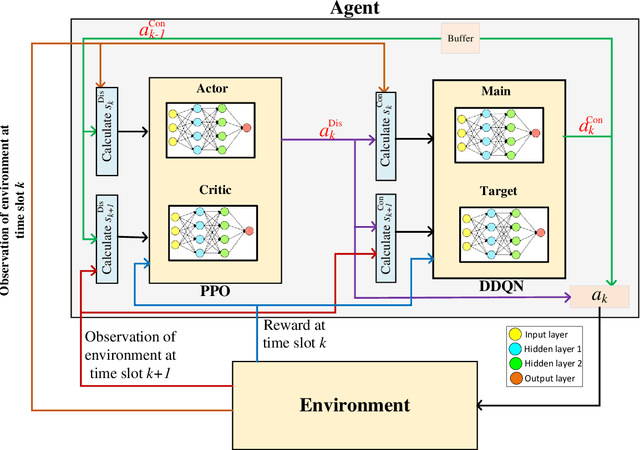
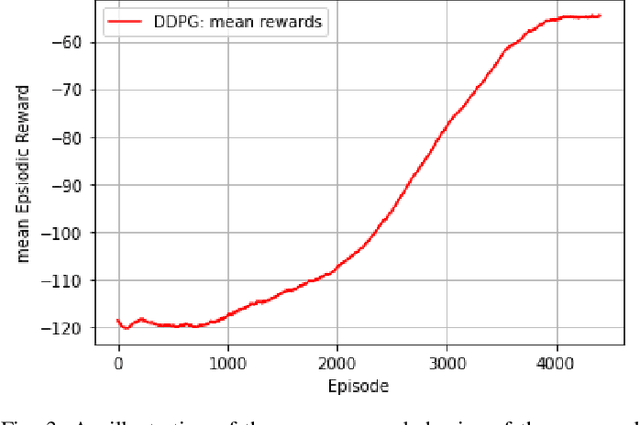

In this paper, we consider that the unmanned aerial vehicles (UAVs) with attached intelligent reflecting surfaces (IRSs) play the role of flying reflectors that reflect the signal of users to the destination, and utilize the power-domain non-orthogonal multiple access (PD-NOMA) scheme in the uplink. We investigate the benefits of the UAV-IRS on the internet of things (IoT) networks that improve the freshness of collected data of the IoT devices via optimizing power, sub-carrier, and trajectory variables, as well as, the phase shift matrix elements. We consider minimizing the average age-of-information (AAoI) of users subject to the maximum transmit power limitations, PD-NOMA-related restriction, and the constraints related to UAV's movement. The optimization problem consists of discrete and continuous variables. Hence, we divide the resource allocation problem into two sub-problems and use two different reinforcement learning (RL) based algorithms to solve them, namely the double deep Qnetwork (DDQN) and a proximal policy optimization (PPO). Our numerical results illustrate the performance gains that can be achieved for IRS enabled UAV communication systems. Moreover, we compare our deep RL (DRL) based algorithm with matching algorithm and random trajectory, showing the combination of DDQN and PPO algorithm proposed in this paper performs 10% and 15% better than matching algorithm and random-trajectory algorithm, respectively.
AI-Based Secure NOMA and Cognitive Radio enabled Green Communications: Channel State Information and Battery Value Uncertainties
Jun 30, 2021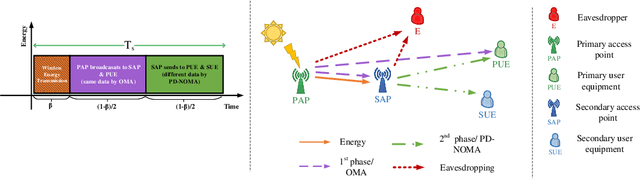
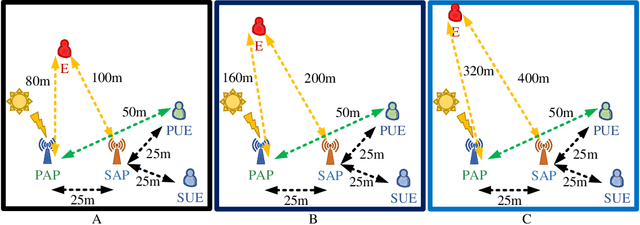
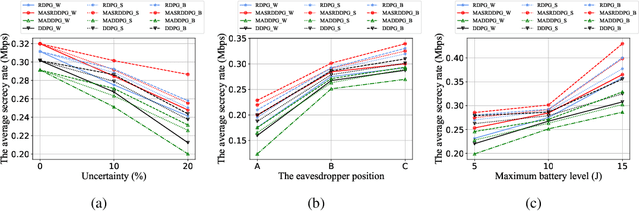
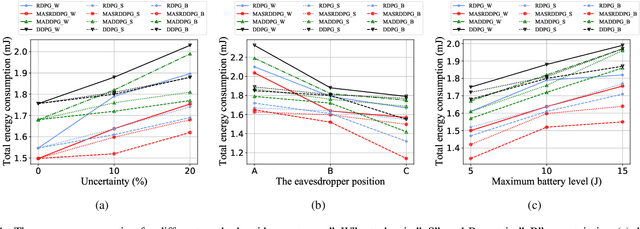
In this paper, the security-aware robust resource allocation in energy harvesting cognitive radio networks is considered with cooperation between two transmitters while there are uncertainties in channel gains and battery energy value. To be specific, the primary access point harvests energy from the green resource and uses time switching protocol to send the energy and data towards the secondary access point (SAP). Using power-domain non-orthogonal multiple access technique, the SAP helps the primary network to improve the security of data transmission by using the frequency band of the primary network. In this regard, we introduce the problem of maximizing the proportional-fair energy efficiency (PFEE) considering uncertainty in the channel gains and battery energy value subject to the practical constraints. Moreover, the channel gain of the eavesdropper is assumed to be unknown. Employing the decentralized partially observable Markov decision process, we investigate the solution of the corresponding resource allocation problem. We exploit multi-agent with single reward deep deterministic policy gradient (MASRDDPG) and recurrent deterministic policy gradient (RDPG) methods. These methods are compared with the state-of-the-art ones like multi-agent and single-agent DDPG. Simulation results show that both MASRDDPG and RDPG methods, outperform the state-of-the-art methods by providing more PFEE to the network.