 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Transformer-Based Near- and Far-Field THz Wideband Channel Estimation for UM-MIMO
May 12, 2026The integration of terahertz communications and ultra-massive multiple-input multiple-output (UM-MIMO) systems in 6G networks is motivated by their ability to enable unprecedented data rates, mitigate spectrum congestion, and enhance overall network performance. However, the enlarged antenna apertures and higher carrier frequencies in these systems increase the Rayleigh distance, causing users to span both the near-field and conventional far-field regions. Accurate spatial precoding thus requires exact channel estimation at the base station - a task made more challenging by the hybrid coexistence of near- and far-field effects and the limited number of digital chains available in hybrid beamforming architectures. In this paper, we propose a block recurrent transformer model to address this challenge. We demonstrate that a single transformer block equipped with state memory can be trained once and then iteratively applied for hybrid-field channel estimation. Furthermore, we train the model such that it generalizes to wireless channels with varying scatterer distances, different numbers of propagation paths, and wideband operation. Simulation results show that the proposed method achieves performance gains of approximately 5 dB and 7.5 dB in normalized mean squared error (NMSE) over state-of-the-art solutions in narrowband and wideband scenarios, respectively.
* 15 pages, 15 figures
Secure and Robust Beamforming Design for STAR-RIS-aided MU-MIMO ISAC Systems
Mar 08, 2026Simultaneous transmitting and reflecting reconfigurable intelligent surfaces (STAR-RIS) offer a transformative approach for integrated sensing and communication (ISAC) systems, particularly for enhancing physical layer security (PLS). This paper investigates a robust, secure downlink transmission framework for a STAR-RIS empowered multi-user (MU) multiple-input multiple-output (MU-MIMO) system, where a multi-antenna dual-function radar and communication base station (DFRC-BS) that simultaneously transmits confidential messages to multiple intended users (IUs) and performs target sensing in the presence of malicious eavesdroppers. To optimize system security, we formulate a worst-case robust beamforming problem to maximize the secrecy rate. This formulation jointly designs the active transmit beamforming at the BS and the passive reflection, transmission coefficients at the STAR-RIS, adheres to transmit power budgets, user quality-of-service (QoS) thresholds, sensing signal-to-interference-plus-noise ratio (SINR) requirements, maximum tolerable eavesdropping leakage, and practical phase shifts constraints. To efficiently tackle the formulated problem, we develop an alternating optimization (AO) algorithm. Specifically, the S-procedure is employed to solve semi-infinite channel uncertainty constraints, while semidefinite relaxation (SDR) and penalty convex-concave programming (CCP) are applied to obtain tractable suboptimal solutions. Extensive simulation results validate the efficacy of the proposed framework and demonstrate significant improvement in spectral efficiency compared to conventional reflecting-only RIS (R-RIS) systems under stringent sensing conditions.
Secrecy Rate Maximization in RIS-Assisted MIMO Systems Using a Practical Hardware Model
Feb 19, 2026This study investigates a robust reconfigurable intelligent surface (RIS)-assisted multiple-input multiple-output (MIMO) system for secure wireless communication, in which a multi-antenna transmitter (Alice) sends confidential messages to a multi-antenna receiver (Bob) in the presence of an eavesdropper (Eve). Unlike idealized models, the reflecting elements (REs) of the RIS are assumed to possess inherent electrical resistance, introducing a practical non-ideal effect often neglected in prior research. The aim of the study is to maximize the secrecy rate of the MIMO system under perfect knowledge of the channel state information (CSI). To achieve this, the secrecy rate maximization problem is formulated and solved using a low-complexity joint optimization framework based on an adaptive projected gradient method (PGM), which simultaneously updates both the transmit precoding matrix and the RIS phase shifts. Solving the exact problem is computationally complex. Thus, a simplified variant is further introduced that maximizes the channel power difference rather than the exact secrecy rate. The simulation results show that this approximation yields a secrecy rate close to the true optimum while significantly reducing the computational cost. In addition, the proposed PGM with an adaptive step size initialization and control mechanism substantially improves the secrecy rate and reduces the computational time compared to the conventional fixed step size PGM. Overall, the simulation results confirm the effectiveness of the proposed PGM and demonstrate that adopting a practical RIS model is essential for establishing secure RIS-assisted MIMO communication links, especially under varying RE resistance values.
SplitEE: Early Exit in Deep Neural Networks with Split Computing
Sep 17, 2023
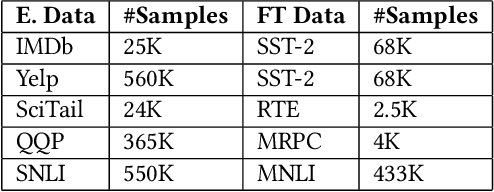
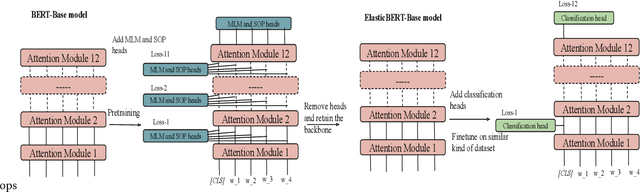
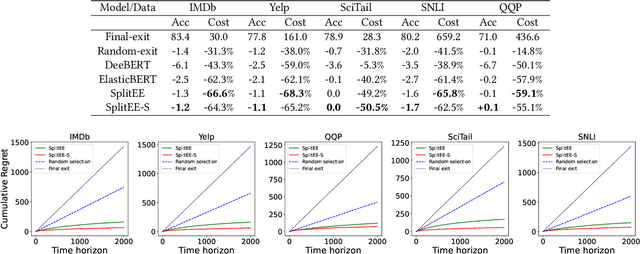
Deep Neural Networks (DNNs) have drawn attention because of their outstanding performance on various tasks. However, deploying full-fledged DNNs in resource-constrained devices (edge, mobile, IoT) is difficult due to their large size. To overcome the issue, various approaches are considered, like offloading part of the computation to the cloud for final inference (split computing) or performing the inference at an intermediary layer without passing through all layers (early exits). In this work, we propose combining both approaches by using early exits in split computing. In our approach, we decide up to what depth of DNNs computation to perform on the device (splitting layer) and whether a sample can exit from this layer or need to be offloaded. The decisions are based on a weighted combination of accuracy, computational, and communication costs. We develop an algorithm named SplitEE to learn an optimal policy. Since pre-trained DNNs are often deployed in new domains where the ground truths may be unavailable and samples arrive in a streaming fashion, SplitEE works in an online and unsupervised setup. We extensively perform experiments on five different datasets. SplitEE achieves a significant cost reduction ($>50\%$) with a slight drop in accuracy ($<2\%$) as compared to the case when all samples are inferred at the final layer. The anonymized source code is available at \url{https://anonymous.4open.science/r/SplitEE_M-B989/README.md}.
UB3: Best Beam Identification in Millimeter Wave Systems via Pure Exploration Unimodal Bandits
Dec 26, 2022Millimeter wave (mmWave) communications have a broad spectrum and can support data rates in the order of gigabits per second, as envisioned in 5G systems. However, they cannot be used for long distances due to their sensitivity to attenuation loss. To enable their use in the 5G network, it requires that the transmission energy be focused in sharp pencil beams. As any misalignment between the transmitter and receiver beam pair can reduce the data rate significantly, it is important that they are aligned as much as possible. To find the best transmit-receive beam pair, recent beam alignment (BA) techniques examine the entire beam space, which might result in a large amount of BA latency. Recent works propose to adaptively select the beams such that the cumulative reward measured in terms of received signal strength or throughput is maximized. In this paper, we develop an algorithm that exploits the unimodal structure of the received signal strengths of the beams to identify the best beam in a finite time using pure exploration strategies. Strategies that identify the best beam in a fixed time slot are more suitable for wireless network protocol design than cumulative reward maximization strategies that continuously perform exploration and exploitation. Our algorithm is named Unimodal Bandit for Best Beam (UB3) and identifies the best beam with a high probability in a few rounds. We prove that the error exponent in the probability does not depend on the number of beams and show that this is indeed the case by establishing a lower bound for the unimodal bandits. We demonstrate that UB3 outperforms the state-of-the-art algorithms through extensive simulations. Moreover, our algorithm is simple to implement and has lower computational complexity.
Unsupervised Early Exit in DNNs with Multiple Exits
Sep 20, 2022



Deep Neural Networks (DNNs) are generally designed as sequentially cascaded differentiable blocks/layers with a prediction module connected only to its last layer. DNNs can be attached with prediction modules at multiple points along the backbone where inference can stop at an intermediary stage without passing through all the modules. The last exit point may offer a better prediction error but also involves more computational resources and latency. An exit point that is `optimal' in terms of both prediction error and cost is desirable. The optimal exit point may depend on the latent distribution of the tasks and may change from one task type to another. During neural inference, the ground truth of instances may not be available and error rates at each exit point cannot be estimated. Hence one is faced with the problem of selecting the optimal exit in an unsupervised setting. Prior works tackled this problem in an offline supervised setting assuming that enough labeled data is available to estimate the error rate at each exit point and tune the parameters for better accuracy. However, pre-trained DNNs are often deployed in new domains for which a large amount of ground truth may not be available. We model the problem of exit selection as an unsupervised online learning problem and use bandit theory to identify the optimal exit point. Specifically, we focus on Elastic BERT, a pre-trained multi-exit DNN to demonstrate that it `nearly' satisfies the Strong Dominance (SD) property making it possible to learn the optimal exit in an online setup without knowing the ground truth labels. We develop upper confidence bound (UCB) based algorithm named UEE-UCB that provably achieves sub-linear regret under the SD property. Thus our method provides a means to adaptively learn domain-specific optimal exit points in multi-exit DNNs. We empirically validate our algorithm on IMDb and Yelp datasets.
Exploiting Side Information for Improved Online Learning Algorithms in Wireless Networks
Feb 16, 2022



In wireless networks, the rate achieved depends on factors like level of interference, hardware impairments, and channel gain. Often, instantaneous values of some of these factors can be measured, and they provide useful information about the instantaneous rate achieved. For example, higher interference implies a lower rate. In this work, we treat any such measurable quality that has a non-zero correlation with the rate achieved as side-information and study how it can be exploited to quickly learn the channel that offers higher throughput (reward). When the mean value of the side-information is known, using control variate theory we develop algorithms that require fewer samples to learn the parameters and can improve the learning rate compared to cases where side-information is ignored. Specifically, we incorporate side-information in the classical Upper Confidence Bound (UCB) algorithm and quantify the gain achieved in the regret performance. We show that the gain is proportional to the amount of the correlation between the reward and associated side-information. We discuss in detail various side-information that can be exploited in cognitive radio and air-to-ground communication in $L-$band. We demonstrate that correlation between the reward and side-information is often strong in practice and exploiting it improves the throughput significantly.
Continuous Time Bandits With Sampling Costs
Jul 12, 2021

We consider a continuous-time multi-arm bandit problem (CTMAB), where the learner can sample arms any number of times in a given interval and obtain a random reward from each sample, however, increasing the frequency of sampling incurs an additive penalty/cost. Thus, there is a tradeoff between obtaining large reward and incurring sampling cost as a function of the sampling frequency. The goal is to design a learning algorithm that minimizes regret, that is defined as the difference of the payoff of the oracle policy and that of the learning algorithm. CTMAB is fundamentally different than the usual multi-arm bandit problem (MAB), e.g., even the single-arm case is non-trivial in CTMAB, since the optimal sampling frequency depends on the mean of the arm, which needs to be estimated. We first establish lower bounds on the regret achievable with any algorithm and then propose algorithms that achieve the lower bound up to logarithmic factors. For the single-arm case, we show that the lower bound on the regret is $\Omega((\log T)^2/\mu)$, where $\mu$ is the mean of the arm, and $T$ is the time horizon. For the multiple arms case, we show that the lower bound on the regret is $\Omega((\log T)^2 \mu/\Delta^2)$, where $\mu$ now represents the mean of the best arm, and $\Delta$ is the difference of the mean of the best and the second-best arm. We then propose an algorithm that achieves the bound up to constant terms.
Federated Learning for Intrusion Detection in IoT Security: A Hybrid Ensemble Approach
Jun 25, 2021
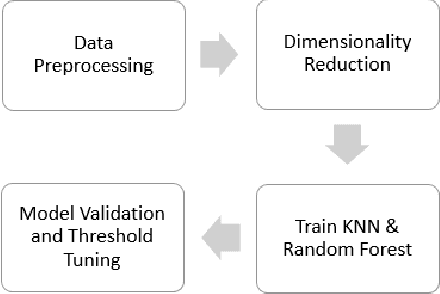

Critical role of Internet of Things (IoT) in various domains like smart city, healthcare, supply chain and transportation has made them the target of malicious attacks. Past works in this area focused on centralized Intrusion Detection System (IDS), assuming the existence of a central entity to perform data analysis and identify threats. However, such IDS may not always be feasible, mainly due to spread of data across multiple sources and gathering at central node can be costly. Also, the earlier works primarily focused on improving True Positive Rate (TPR) and ignored the False Positive Rate (FPR), which is also essential to avoid unnecessary downtime of the systems. In this paper, we first present an architecture for IDS based on hybrid ensemble model, named PHEC, which gives improved performance compared to state-of-the-art architectures. We then adapt this model to a federated learning framework that performs local training and aggregates only the model parameters. Next, we propose Noise-Tolerant PHEC in centralized and federated settings to address the label-noise problem. The proposed idea uses classifiers using weighted convex surrogate loss functions. Natural robustness of KNN classifier towards noisy data is also used in the proposed architecture. Experimental results on four benchmark datasets drawn from various security attacks show that our model achieves high TPR while keeping FPR low on noisy and clean data. Further, they also demonstrate that the hybrid ensemble models achieve performance in federated settings close to that of the centralized settings.
Stochastic Multi-Armed Bandits with Control Variates
May 09, 2021



This paper studies a new variant of the stochastic multi-armed bandits problem, where the learner has access to auxiliary information about the arms. The auxiliary information is correlated with the arm rewards, which we treat as control variates. In many applications, the arm rewards are a function of some exogenous values, whose mean value is known a priori from historical data and hence can be used as control variates. We use the control variates to obtain mean estimates with smaller variance and tighter confidence bounds. We then develop an algorithm named UCB-CV that uses improved estimates. We characterize the regret bounds in terms of the correlation between the rewards and control variates. The experiments on synthetic data validate the performance guarantees of our proposed algorithm.