 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCensored Semi-Bandits for Resource Allocation
Apr 12, 2021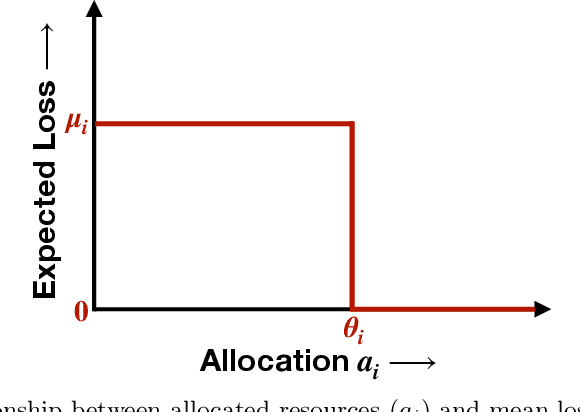

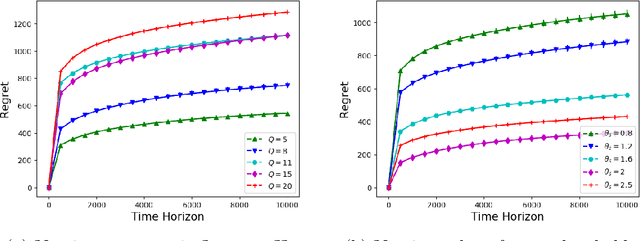
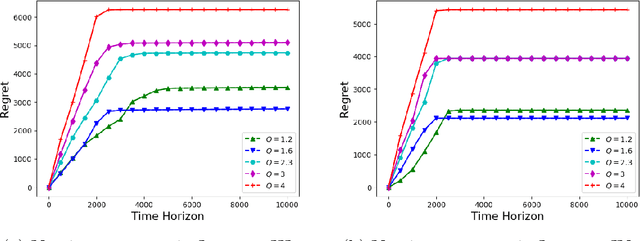
We consider the problem of sequentially allocating resources in a censored semi-bandits setup, where the learner allocates resources at each step to the arms and observes loss. The loss depends on two hidden parameters, one specific to the arm but independent of the resource allocation, and the other depends on the allocated resource. More specifically, the loss equals zero for an arm if the resource allocated to it exceeds a constant (but unknown) arm dependent threshold. The goal is to learn a resource allocation that minimizes the expected loss. The problem is challenging because the loss distribution and threshold value of each arm are unknown. We study this setting by establishing its `equivalence' to Multiple-Play Multi-Armed Bandits (MP-MAB) and Combinatorial Semi-Bandits. Exploiting these equivalences, we derive optimal algorithms for our problem setting using known algorithms for MP-MAB and Combinatorial Semi-Bandits. The experiments on synthetically generated data validate the performance guarantees of the proposed algorithms.
Censored Semi-Bandits: A Framework for Resource Allocation with Censored Feedback
Sep 04, 2019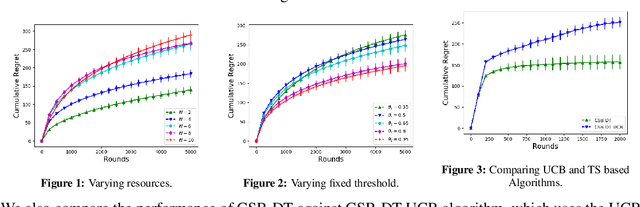
In this paper, we study Censored Semi-Bandits, a novel variant of the semi-bandits problem. The learner is assumed to have a fixed amount of resources, which it allocates to the arms at each time step. The loss observed from an arm is random and depends on the amount of resource allocated to it. More specifically, the loss equals zero if the allocation for the arm exceeds a constant (but unknown) threshold that can be dependent on the arm. Our goal is to learn a feasible allocation that minimizes the expected loss. The problem is challenging because the loss distribution and threshold value of each arm are unknown. We study this novel setting by establishing its `equivalence' to Multiple-Play Multi-Armed Bandits (MP-MAB) and Combinatorial Semi-Bandits. Exploiting these equivalences, we derive optimal algorithms for our setting using existing algorithms for MP-MAB and Combinatorial Semi-Bandits. Experiments on synthetically generated data validate performance guarantees of the proposed algorithms.
Controlled Sparsity Kernel Learning
Dec 31, 2013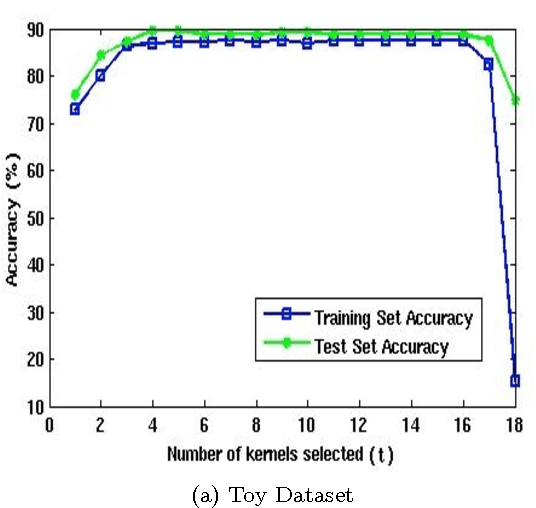
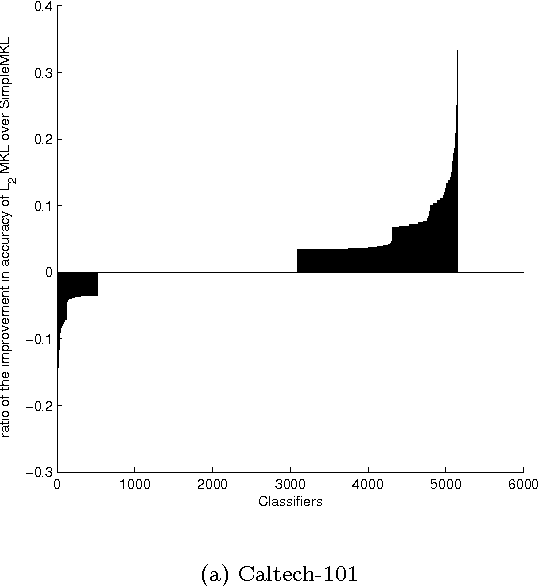
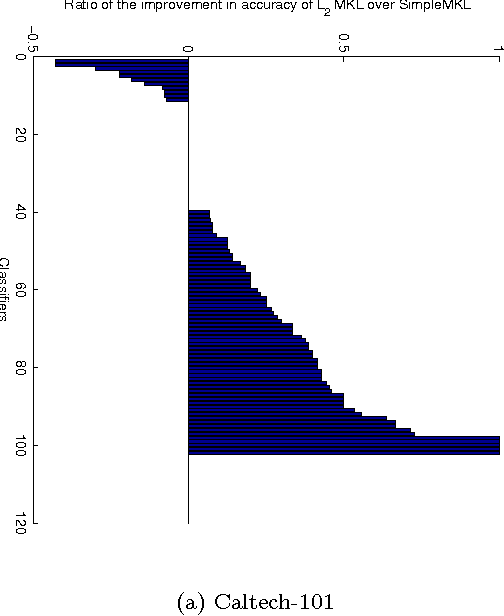

Multiple Kernel Learning(MKL) on Support Vector Machines(SVMs) has been a popular front of research in recent times due to its success in application problems like Object Categorization. This success is due to the fact that MKL has the ability to choose from a variety of feature kernels to identify the optimal kernel combination. But the initial formulation of MKL was only able to select the best of the features and misses out many other informative kernels presented. To overcome this, the Lp norm based formulation was proposed by Kloft et. al. This formulation is capable of choosing a non-sparse set of kernels through a control parameter p. Unfortunately, the parameter p does not have a direct meaning to the number of kernels selected. We have observed that stricter control over the number of kernels selected gives us an edge over these techniques in terms of accuracy of classification and also helps us to fine tune the algorithms to the time requirements at hand. In this work, we propose a Controlled Sparsity Kernel Learning (CSKL) formulation that can strictly control the number of kernels which we wish to select. The CSKL formulation introduces a parameter t which directly corresponds to the number of kernels selected. It is important to note that a search in t space is finite and fast as compared to p. We have also provided an efficient Reduced Gradient Descent based algorithm to solve the CSKL formulation, which is proven to converge. Through our experiments on the Caltech101 Object Categorization dataset, we have also shown that one can achieve better accuracies than the previous formulations through the right choice of t.