 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Boosting with SVM as Week Learners Help?
Apr 22, 2016Object recognition in images involves identifying objects with partial occlusions, viewpoint changes, varying illumination, cluttered backgrounds. Recent work in object recognition uses machine learning techniques SVM-KNN, Local Ensemble Kernel Learning, Multiple Kernel Learning. In this paper, we want to utilize SVM as week learners in AdaBoost. Experiments are done with classifiers like near- est neighbor, k-nearest neighbor, Support vector machines, Local learning(SVM- KNN) and AdaBoost. Models use Scale-Invariant descriptors and Pyramid his- togram of gradient descriptors. AdaBoost is trained with set of week classifier as SVMs, each with kernel distance function on different descriptors. Results shows AdaBoost with SVM outperform other methods for Object Categorization dataset.
Thesis: Multiple Kernel Learning for Object Categorization
Apr 12, 2016
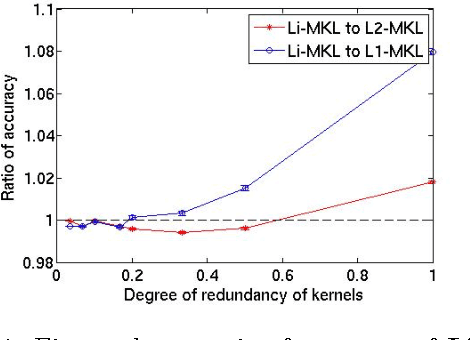


Object Categorization is a challenging problem, especially when the images have clutter background, occlusions or different lighting conditions. In the past, many descriptors have been proposed which aid object categorization even in such adverse conditions. Each descriptor has its own merits and de-merits. Some descriptors are invariant to transformations while the others are more discriminative. Past research has shown that, employing multiple descriptors rather than any single descriptor leads to better recognition. The problem of learning the optimal combination of the available descriptors for a particular classification task is studied. Multiple Kernel Learning (MKL) framework has been developed for learning an optimal combination of descriptors for object categorization. Existing MKL formulations often employ block l-1 norm regularization which is equivalent to selecting a single kernel from a library of kernels. Since essentially a single descriptor is selected, the existing formulations maybe sub- optimal for object categorization. A MKL formulation based on block l-infinity norm regularization has been developed, which chooses an optimal combination of kernels as opposed to selecting a single kernel. A Composite Multiple Kernel Learning(CKL) formulation based on mixed l-infinity and l-1 norm regularization has been developed. These formulations end in Second Order Cone Programs(SOCP). Other efficient alter- native algorithms for these formulation have been implemented. Empirical results on benchmark datasets show significant improvement using these new MKL formulations.
Modeling Attractiveness and Multiple Clicks in Sponsored Search Results
Jan 01, 2014
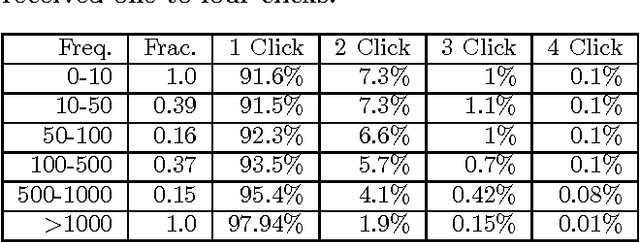

Click models are an important tool for leveraging user feedback, and are used by commercial search engines for surfacing relevant search results. However, existing click models are lacking in two aspects. First, they do not share information across search results when computing attractiveness. Second, they assume that users interact with the search results sequentially. Based on our analysis of the click logs of a commercial search engine, we observe that the sequential scan assumption does not always hold, especially for sponsored search results. To overcome the above two limitations, we propose a new click model. Our key insight is that sharing information across search results helps in identifying important words or key-phrases which can then be used to accurately compute attractiveness of a search result. Furthermore, we argue that the click probability of a position as well as its attractiveness changes during a user session and depends on the user's past click experience. Our model seamlessly incorporates the effect of externalities (quality of other search results displayed in response to a user query), user fatigue, as well as pre and post-click relevance of a sponsored search result. We propose an efficient one-pass inference scheme and empirically evaluate the performance of our model via extensive experiments using the click logs of a large commercial search engine.
Controlled Sparsity Kernel Learning
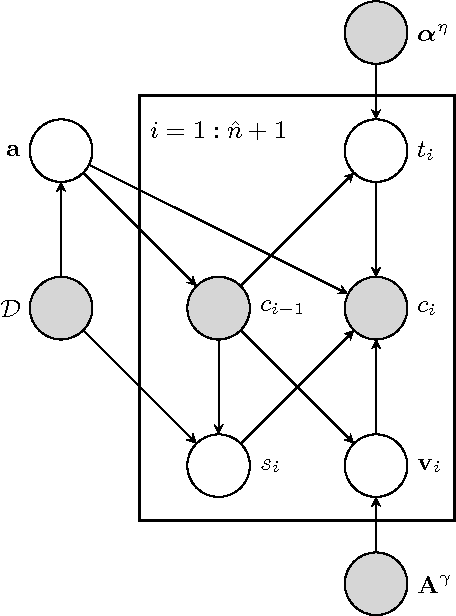
Dec 31, 2013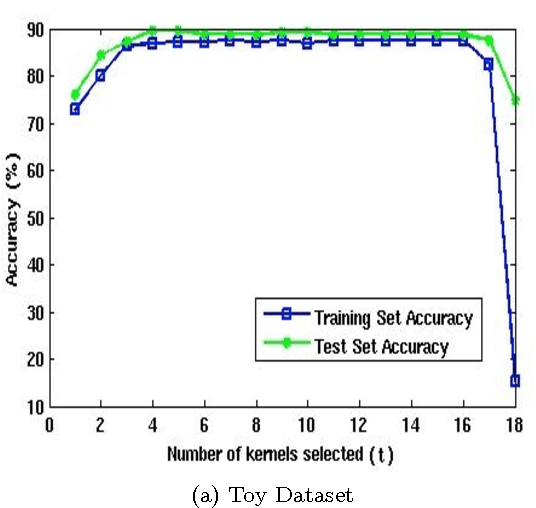
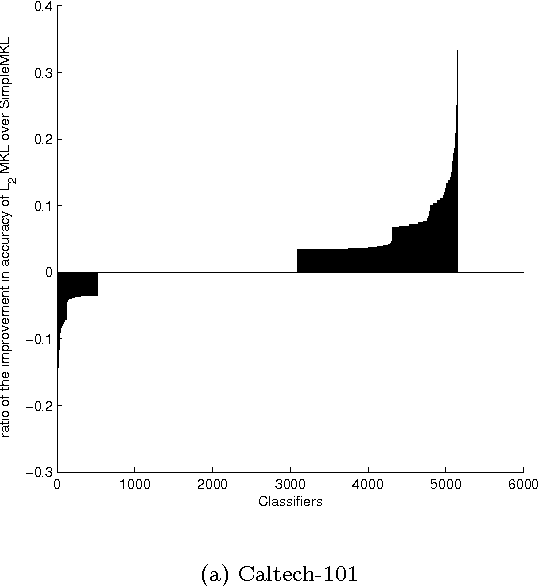
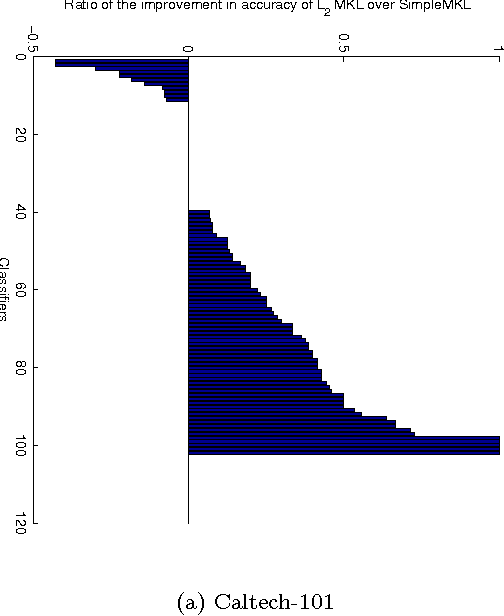

Multiple Kernel Learning(MKL) on Support Vector Machines(SVMs) has been a popular front of research in recent times due to its success in application problems like Object Categorization. This success is due to the fact that MKL has the ability to choose from a variety of feature kernels to identify the optimal kernel combination. But the initial formulation of MKL was only able to select the best of the features and misses out many other informative kernels presented. To overcome this, the Lp norm based formulation was proposed by Kloft et. al. This formulation is capable of choosing a non-sparse set of kernels through a control parameter p. Unfortunately, the parameter p does not have a direct meaning to the number of kernels selected. We have observed that stricter control over the number of kernels selected gives us an edge over these techniques in terms of accuracy of classification and also helps us to fine tune the algorithms to the time requirements at hand. In this work, we propose a Controlled Sparsity Kernel Learning (CSKL) formulation that can strictly control the number of kernels which we wish to select. The CSKL formulation introduces a parameter t which directly corresponds to the number of kernels selected. It is important to note that a search in t space is finite and fast as compared to p. We have also provided an efficient Reduced Gradient Descent based algorithm to solve the CSKL formulation, which is proven to converge. Through our experiments on the Caltech101 Object Categorization dataset, we have also shown that one can achieve better accuracies than the previous formulations through the right choice of t.