 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDReason: Algorithm-Hardware Codesign for Hyperdimensional Knowledge Graph Reasoning
Mar 09, 2024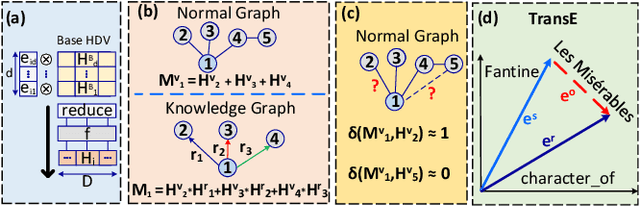
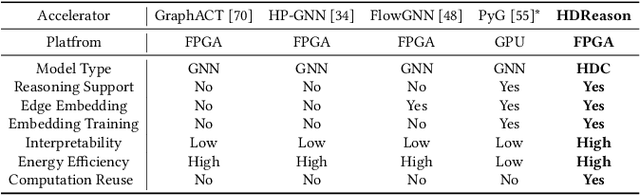

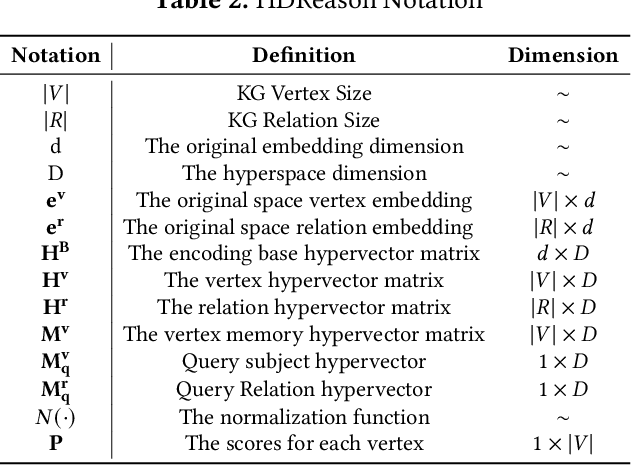
In recent times, a plethora of hardware accelerators have been put forth for graph learning applications such as vertex classification and graph classification. However, previous works have paid little attention to Knowledge Graph Completion (KGC), a task that is well-known for its significantly higher algorithm complexity. The state-of-the-art KGC solutions based on graph convolution neural network (GCN) involve extensive vertex/relation embedding updates and complicated score functions, which are inherently cumbersome for acceleration. As a result, existing accelerator designs are no longer optimal, and a novel algorithm-hardware co-design for KG reasoning is needed. Recently, brain-inspired HyperDimensional Computing (HDC) has been introduced as a promising solution for lightweight machine learning, particularly for graph learning applications. In this paper, we leverage HDC for an intrinsically more efficient and acceleration-friendly KGC algorithm. We also co-design an acceleration framework named HDReason targeting FPGA platforms. On the algorithm level, HDReason achieves a balance between high reasoning accuracy, strong model interpretability, and less computation complexity. In terms of architecture, HDReason offers reconfigurability, high training throughput, and low energy consumption. When compared with NVIDIA RTX 4090 GPU, the proposed accelerator achieves an average 10.6x speedup and 65x energy efficiency improvement. When conducting cross-models and cross-platforms comparison, HDReason yields an average 4.2x higher performance and 3.4x better energy efficiency with similar accuracy versus the state-of-the-art FPGA-based GCN training platform.
Always-Sparse Training by Growing Connections with Guided Stochastic Exploration
Jan 12, 2024The excessive computational requirements of modern artificial neural networks (ANNs) are posing limitations on the machines that can run them. Sparsification of ANNs is often motivated by time, memory and energy savings only during model inference, yielding no benefits during training. A growing body of work is now focusing on providing the benefits of model sparsification also during training. While these methods greatly improve the training efficiency, the training algorithms yielding the most accurate models still materialize the dense weights, or compute dense gradients during training. We propose an efficient, always-sparse training algorithm with excellent scaling to larger and sparser models, supported by its linear time complexity with respect to the model width during training and inference. Moreover, our guided stochastic exploration algorithm improves over the accuracy of previous sparse training methods. We evaluate our method on CIFAR-10/100 and ImageNet using ResNet, VGG, and ViT models, and compare it against a range of sparsification methods.
Low-Power Neuromorphic Hardware for Signal Processing Applications
Jan 11, 2019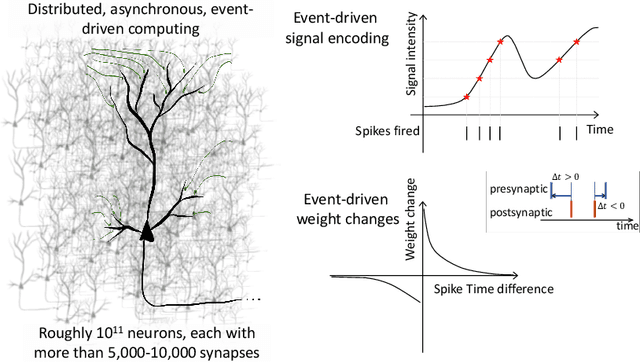
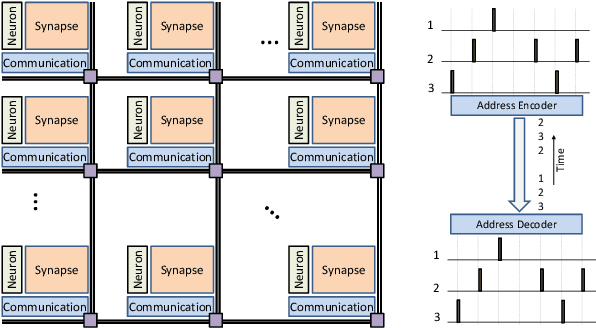
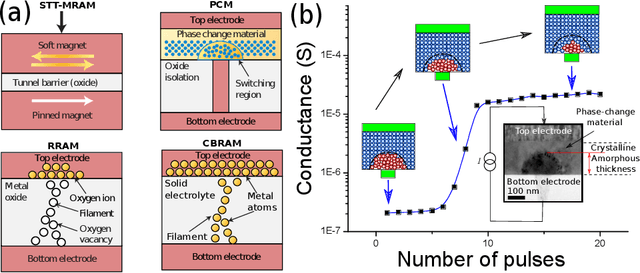
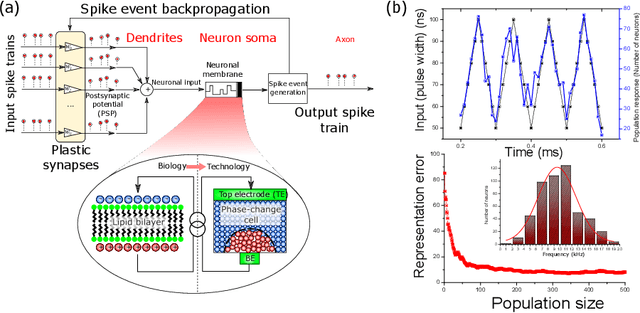
Machine learning has emerged as the dominant tool for implementing complex cognitive tasks that require supervised, unsupervised, and reinforcement learning. While the resulting machines have demonstrated in some cases even super-human performance, their energy consumption has often proved to be prohibitive in the absence of costly super-computers. Most state-of-the-art machine learning solutions are based on memory-less models of neurons. This is unlike the neurons in the human brain, which encode and process information using temporal information in spike events. The different computing principles underlying biological neurons and how they combine together to efficiently process information is believed to be a key factor behind their superior efficiency compared to current machine learning systems. Inspired by the time-encoding mechanism used by the brain, third generation spiking neural networks (SNNs) are being studied for building a new class of information processing engines. Modern computing systems based on the von Neumann architecture, however, are ill-suited for efficiently implementing SNNs, since their performance is limited by the need to constantly shuttle data between physically separated logic and memory units. Hence, novel computational architectures that address the von Neumann bottleneck are necessary in order to build systems that can implement SNNs with low energy budgets. In this paper, we review some of the architectural and system level design aspects involved in developing a new class of brain-inspired information processing engines that mimic the time-based information encoding and processing aspects of the brain.
Learning to Recognize Actions from Limited Training Examples Using a Recurrent Spiking Neural Model
Oct 19, 2017


A fundamental challenge in machine learning today is to build a model that can learn from few examples. Here, we describe a reservoir based spiking neural model for learning to recognize actions with a limited number of labeled videos. First, we propose a novel encoding, inspired by how microsaccades influence visual perception, to extract spike information from raw video data while preserving the temporal correlation across different frames. Using this encoding, we show that the reservoir generalizes its rich dynamical activity toward signature action/movements enabling it to learn from few training examples. We evaluate our approach on the UCF-101 dataset. Our experiments demonstrate that our proposed reservoir achieves 81.3%/87% Top-1/Top-5 accuracy, respectively, on the 101-class data while requiring just 8 video examples per class for training. Our results establish a new benchmark for action recognition from limited video examples for spiking neural models while yielding competetive accuracy with respect to state-of-the-art non-spiking neural models.