 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Language Model for Interpretable and Fine-grained Detection of Safety Compliance in Diverse Workplaces
Aug 13, 2024Workplace accidents due to personal protective equipment (PPE) non-compliance raise serious safety concerns and lead to legal liabilities, financial penalties, and reputational damage. While object detection models have shown the capability to address this issue by identifying safety items, most existing models, such as YOLO, Faster R-CNN, and SSD, are limited in verifying the fine-grained attributes of PPE across diverse workplace scenarios. Vision language models (VLMs) are gaining traction for detection tasks by leveraging the synergy between visual and textual information, offering a promising solution to traditional object detection limitations in PPE recognition. Nonetheless, VLMs face challenges in consistently verifying PPE attributes due to the complexity and variability of workplace environments, requiring them to interpret context-specific language and visual cues simultaneously. We introduce Clip2Safety, an interpretable detection framework for diverse workplace safety compliance, which comprises four main modules: scene recognition, the visual prompt, safety items detection, and fine-grained verification. The scene recognition identifies the current scenario to determine the necessary safety gear. The visual prompt formulates the specific visual prompts needed for the detection process. The safety items detection identifies whether the required safety gear is being worn according to the specified scenario. Lastly, the fine-grained verification assesses whether the worn safety equipment meets the fine-grained attribute requirements. We conduct real-world case studies across six different scenarios. The results show that Clip2Safety not only demonstrates an accuracy improvement over state-of-the-art question-answering based VLMs but also achieves inference times two hundred times faster.
SPGNet: Spatial Projection Guided 3D Human Pose Estimation in Low Dimensional Space
Jun 04, 2022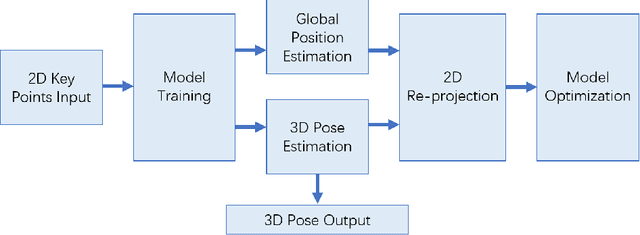
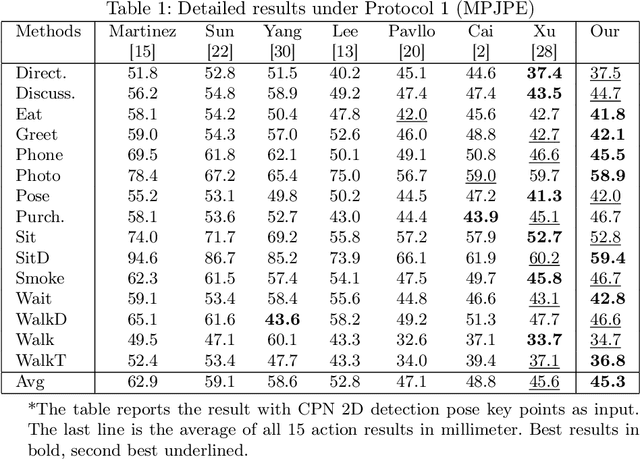
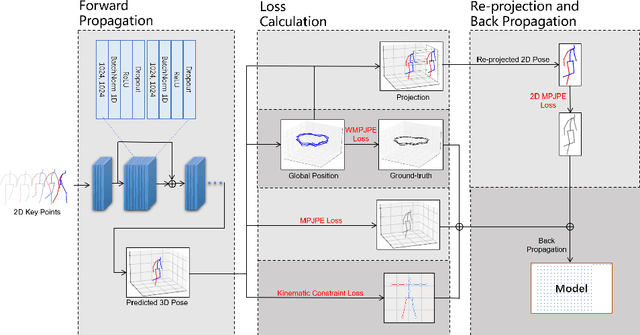

We propose a method SPGNet for 3D human pose estimation that mixes multi-dimensional re-projection into supervised learning. In this method, the 2D-to-3D-lifting network predicts the global position and coordinates of the 3D human pose. Then, we re-project the estimated 3D pose back to the 2D key points along with spatial adjustments. The loss functions compare the estimated 3D pose with the 3D pose ground truth, and re-projected 2D pose with the input 2D pose. In addition, we propose a kinematic constraint to restrict the predicted target with constant human bone length. Based on the estimation results for the dataset Human3.6M, our approach outperforms many state-of-the-art methods both qualitatively and quantitatively.