 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAD: A realistic Continual Learning benchmark for Autonomous Driving
Oct 07, 2022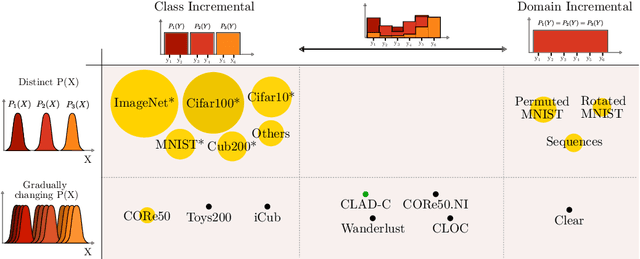

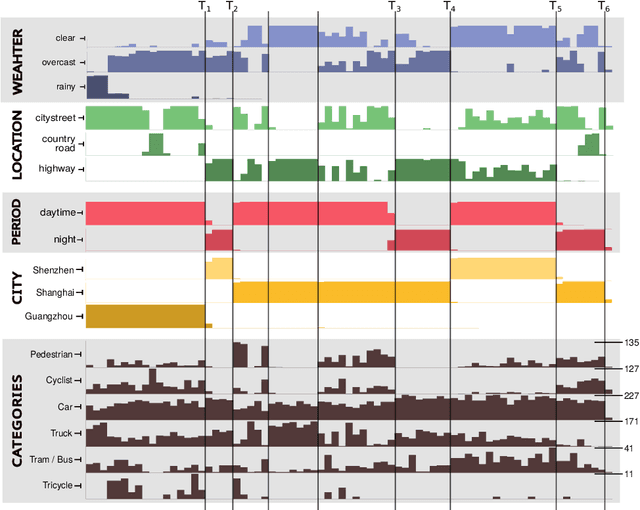
In this paper we describe the design and the ideas motivating a new Continual Learning benchmark for Autonomous Driving (CLAD), that focuses on the problems of object classification and object detection. The benchmark utilises SODA10M, a recently released large-scale dataset that concerns autonomous driving related problems. First, we review and discuss existing continual learning benchmarks, how they are related, and show that most are extreme cases of continual learning. To this end, we survey the benchmarks used in continual learning papers at three highly ranked computer vision conferences. Next, we introduce CLAD-C, an online classification benchmark realised through a chronological data stream that poses both class and domain incremental challenges; and CLAD-D, a domain incremental continual object detection benchmark. We examine the inherent difficulties and challenges posed by the benchmark, through a survey of the techniques and methods used by the top-3 participants in a CLAD-challenge workshop at ICCV 2021. We conclude with possible pathways to improve the current continual learning state of the art, and which directions we deem promising for future research.
Re-examining Distillation For Continual Object Detection
Apr 04, 2022
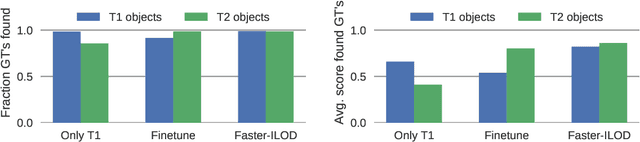


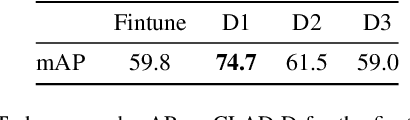
Training models continually to detect and classify objects, from new classes and new domains, remains an open problem. In this work, we conduct a thorough analysis of why and how object detection models forget catastrophically. We focus on distillation-based approaches in two-stage networks; the most-common strategy employed in contemporary continual object detection work.Distillation aims to transfer the knowledge of a model trained on previous tasks -- the teacher -- to a new model -- the student -- while it learns the new task. We show that this works well for the region proposal network, but that wrong, yet overly confident teacher predictions prevent student models from effective learning of the classification head. Our analysis provides a foundation that allows us to propose improvements for existing techniques by detecting incorrect teacher predictions, based on current ground-truth labels, and by employing an adaptive Huber loss as opposed to the mean squared error for the distillation loss in the classification heads. We evidence that our strategy works not only in a class incremental setting, but also in domain incremental settings, which constitute a realistic context, likely to be the setting of representative real-world problems.