 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControl-CLIP: Decoupling Category and Style Guidance in CLIP for Specific-Domain Generation
Feb 17, 2025Text-to-image diffusion models have shown remarkable capabilities of generating high-quality images closely aligned with textual inputs. However, the effectiveness of text guidance heavily relies on the CLIP text encoder, which is trained to pay more attention to general content but struggles to capture semantics in specific domains like styles. As a result, generation models tend to fail on prompts like "a photo of a cat in Pokemon style" in terms of simply producing images depicting "a photo of a cat". To fill this gap, we propose Control-CLIP, a novel decoupled CLIP fine-tuning framework that enables the CLIP model to learn the meaning of category and style in a complement manner. With specially designed fine-tuning tasks on minimal data and a modified cross-attention mechanism, Control-CLIP can precisely guide the diffusion model to a specific domain. Moreover, the parameters of the diffusion model remain unchanged at all, preserving the original generation performance and diversity. Experiments across multiple domains confirm the effectiveness of our approach, particularly highlighting its robust plug-and-play capability in generating content with various specific styles.
Semantic to Structure: Learning Structural Representations for Infringement Detection
Feb 11, 2025Structural information in images is crucial for aesthetic assessment, and it is widely recognized in the artistic field that imitating the structure of other works significantly infringes on creators' rights. The advancement of diffusion models has led to AI-generated content imitating artists' structural creations, yet effective detection methods are still lacking. In this paper, we define this phenomenon as "structural infringement" and propose a corresponding detection method. Additionally, we develop quantitative metrics and create manually annotated datasets for evaluation: the SIA dataset of synthesized data, and the SIR dataset of real data. Due to the current lack of datasets for structural infringement detection, we propose a new data synthesis strategy based on diffusion models and LLM, successfully training a structural infringement detection model. Experimental results show that our method can successfully detect structural infringements and achieve notable improvements on annotated test sets.
Face Forgery Detection by 3D Decomposition
Nov 19, 2020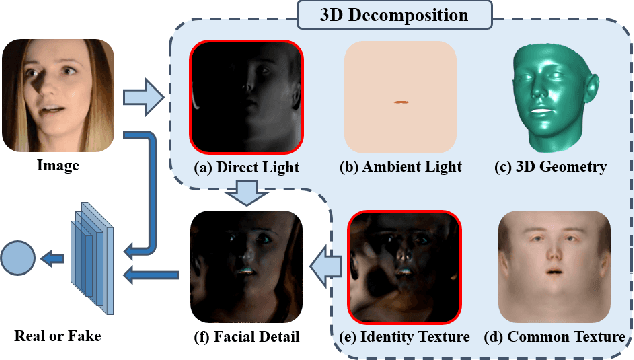


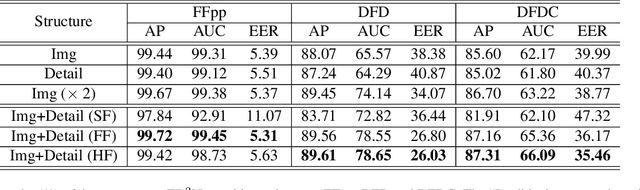
Detecting digital face manipulation has attracted extensive attention due to fake media's potential harms to the public. However, recent advances have been able to reduce the forgery signals to a low magnitude. Decomposition, which reversibly decomposes an image into several constituent elements, is a promising way to highlight the hidden forgery details. In this paper, we consider a face image as the production of the intervention of the underlying 3D geometry and the lighting environment, and decompose it in a computer graphics view. Specifically, by disentangling the face image into 3D shape, common texture, identity texture, ambient light, and direct light, we find the devil lies in the direct light and the identity texture. Based on this observation, we propose to utilize facial detail, which is the combination of direct light and identity texture, as the clue to detect the subtle forgery patterns. Besides, we highlight the manipulated region with a supervised attention mechanism and introduce a two-stream structure to exploit both face image and facial detail together as a multi-modality task. Extensive experiments indicate the effectiveness of the extra features extracted from the facial detail, and our method achieves the state-of-the-art performance.