 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parallelizable Acceleration Framework for Packing Linear Programs
Nov 17, 2017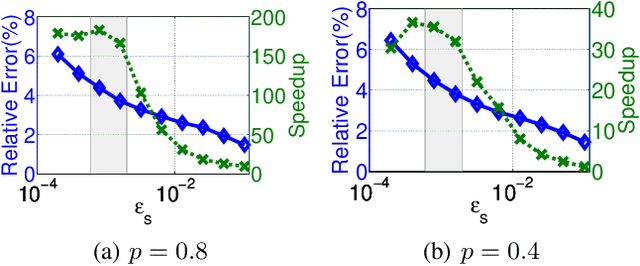
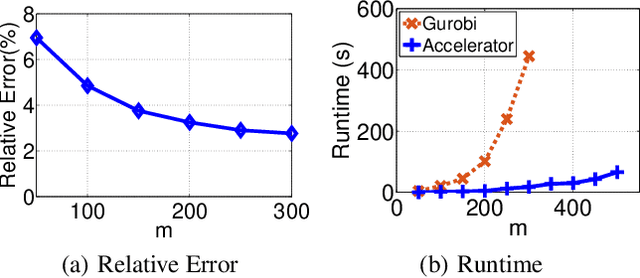
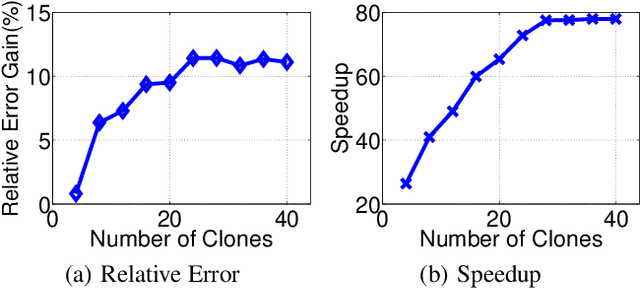
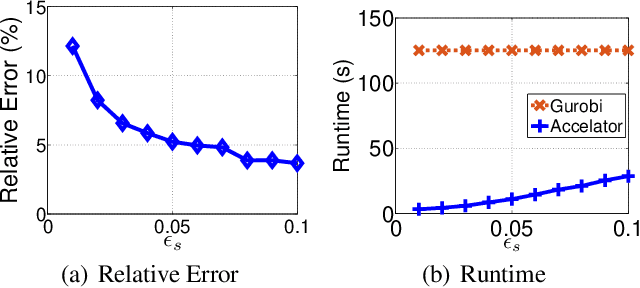
This paper presents an acceleration framework for packing linear programming problems where the amount of data available is limited, i.e., where the number of constraints m is small compared to the variable dimension n. The framework can be used as a black box to speed up linear programming solvers dramatically, by two orders of magnitude in our experiments. We present worst-case guarantees on the quality of the solution and the speedup provided by the algorithm, showing that the framework provides an approximately optimal solution while running the original solver on a much smaller problem. The framework can be used to accelerate exact solvers, approximate solvers, and parallel/distributed solvers. Further, it can be used for both linear programs and integer linear programs.
Learning Graphical Models With Hubs
Aug 09, 2014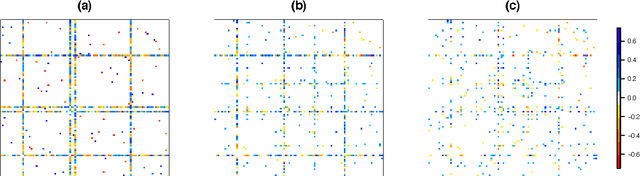
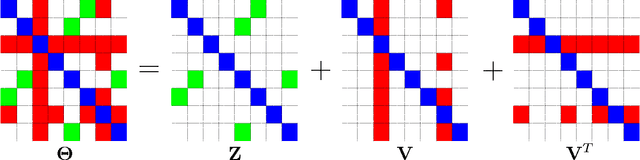
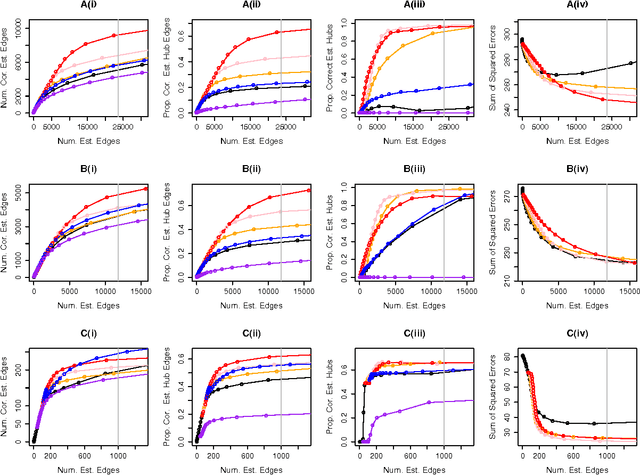
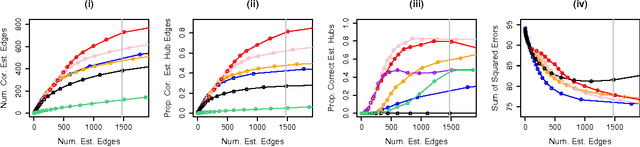
We consider the problem of learning a high-dimensional graphical model in which certain hub nodes are highly-connected to many other nodes. Many authors have studied the use of an l1 penalty in order to learn a sparse graph in high-dimensional setting. However, the l1 penalty implicitly assumes that each edge is equally likely and independent of all other edges. We propose a general framework to accommodate more realistic networks with hub nodes, using a convex formulation that involves a row-column overlap norm penalty. We apply this general framework to three widely-used probabilistic graphical models: the Gaussian graphical model, the covariance graph model, and the binary Ising model. An alternating direction method of multipliers algorithm is used to solve the corresponding convex optimization problems. On synthetic data, we demonstrate that our proposed framework outperforms competitors that do not explicitly model hub nodes. We illustrate our proposal on a webpage data set and a gene expression data set.
Node-Based Learning of Multiple Gaussian Graphical Models
Jan 22, 2014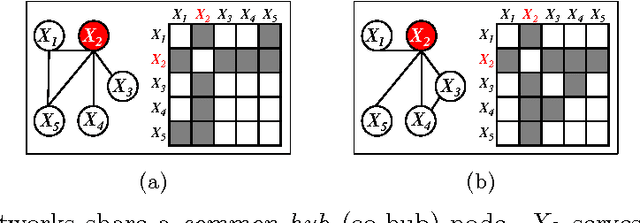

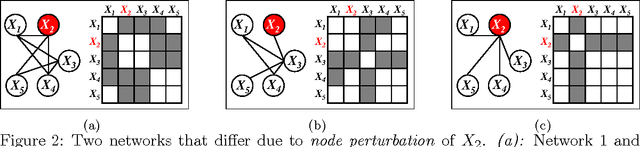

We consider the problem of estimating high-dimensional Gaussian graphical models corresponding to a single set of variables under several distinct conditions. This problem is motivated by the task of recovering transcriptional regulatory networks on the basis of gene expression data {containing heterogeneous samples, such as different disease states, multiple species, or different developmental stages}. We assume that most aspects of the conditional dependence networks are shared, but that there are some structured differences between them. Rather than assuming that similarities and differences between networks are driven by individual edges, we take a node-based approach, which in many cases provides a more intuitive interpretation of the network differences. We consider estimation under two distinct assumptions: (1) differences between the K networks are due to individual nodes that are perturbed across conditions, or (2) similarities among the K networks are due to the presence of common hub nodes that are shared across all K networks. Using a row-column overlap norm penalty function, we formulate two convex optimization problems that correspond to these two assumptions. We solve these problems using an alternating direction method of multipliers algorithm, and we derive a set of necessary and sufficient conditions that allows us to decompose the problem into independent subproblems so that our algorithm can be scaled to high-dimensional settings. Our proposal is illustrated on synthetic data, a webpage data set, and a brain cancer gene expression data set.