 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing Gaussians with Unknown Covariance
Sep 17, 2024



Common workflows in machine learning and statistics rely on the ability to partition the information in a data set into independent portions. Recent work has shown that this may be possible even when conventional sample splitting is not (e.g., when the number of samples $n=1$, or when observations are not independent and identically distributed). However, the approaches that are currently available to decompose multivariate Gaussian data require knowledge of the covariance matrix. In many important problems (such as in spatial or longitudinal data analysis, and graphical modeling), the covariance matrix may be unknown and even of primary interest. Thus, in this work we develop new approaches to decompose Gaussians with unknown covariance. First, we present a general algorithm that encompasses all previous decomposition approaches for Gaussian data as special cases, and can further handle the case of an unknown covariance. It yields a new and more flexible alternative to sample splitting when $n>1$. When $n=1$, we prove that it is impossible to partition the information in a multivariate Gaussian into independent portions without knowing the covariance matrix. Thus, we use the general algorithm to decompose a single multivariate Gaussian with unknown covariance into dependent parts with tractable conditional distributions, and demonstrate their use for inference and validation. The proposed decomposition strategy extends naturally to Gaussian processes. In simulation and on electroencephalography data, we apply these decompositions to the tasks of model selection and post-selection inference in settings where alternative strategies are unavailable.
Valid inference after prediction
Jun 23, 2023Recent work has focused on the very common practice of prediction-based inference: that is, (i) using a pre-trained machine learning model to predict an unobserved response variable, and then (ii) conducting inference on the association between that predicted response and some covariates. As pointed out by Wang et al. [2020], applying a standard inferential approach in (ii) does not accurately quantify the association between the unobserved (as opposed to the predicted) response and the covariates. In recent work, Wang et al. [2020] and Angelopoulos et al. [2023] propose corrections to step (ii) in order to enable valid inference on the association between the unobserved response and the covariates. Here, we show that the method proposed by Angelopoulos et al. [2023] successfully controls the type 1 error rate and provides confidence intervals with correct nominal coverage, regardless of the quality of the pre-trained machine learning model used to predict the unobserved response. However, the method proposed by Wang et al. [2020] provides valid inference only under very strong conditions that rarely hold in practice: for instance, if the machine learning model perfectly approximates the true regression function in the study population of interest.
Generalized Data Thinning Using Sufficient Statistics
Mar 22, 2023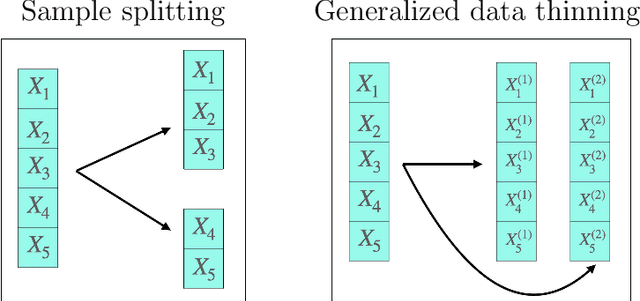
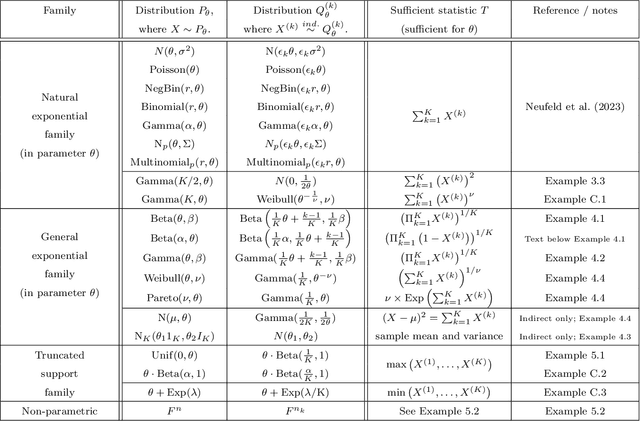
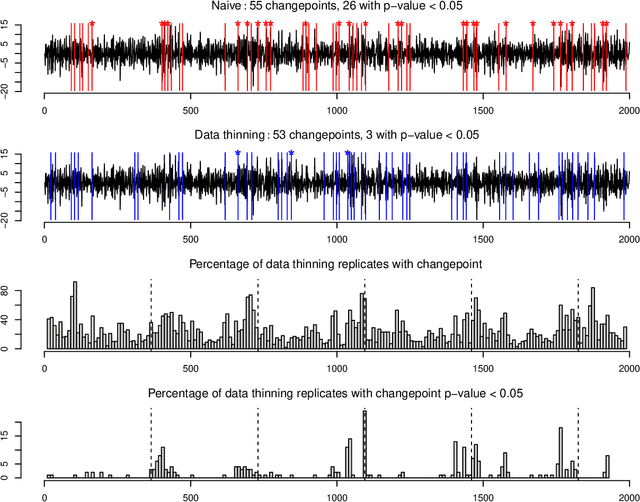
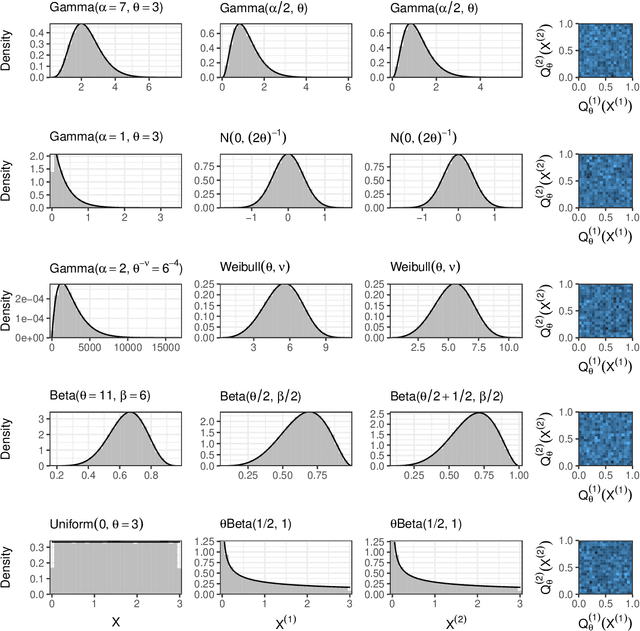
Our goal is to develop a general strategy to decompose a random variable $X$ into multiple independent random variables, without sacrificing any information about unknown parameters. A recent paper showed that for some well-known natural exponential families, $X$ can be "thinned" into independent random variables $X^{(1)}, \ldots, X^{(K)}$, such that $X = \sum_{k=1}^K X^{(k)}$. In this paper, we generalize their procedure by relaxing this summation requirement and simply asking that some known function of the independent random variables exactly reconstruct $X$. This generalization of the procedure serves two purposes. First, it greatly expands the families of distributions for which thinning can be performed. Second, it unifies sample splitting and data thinning, which on the surface seem to be very different, as applications of the same principle. This shared principle is sufficiency. We use this insight to perform generalized thinning operations for a diverse set of families.
Data thinning for convolution-closed distributions
Jan 18, 2023We propose data thinning, a new approach for splitting an observation into two or more independent parts that sum to the original observation, and that follow the same distribution as the original observation, up to a (known) scaling of a parameter. This proposal is very general, and can be applied to any observation drawn from a "convolution closed" distribution, a class that includes the Gaussian, Poisson, negative binomial, Gamma, and binomial distributions, among others. It is similar in spirit to -- but distinct from, and more easily applicable than -- a recent proposal known as data fission. Data thinning has a number of applications to model selection, evaluation, and inference. For instance, cross-validation via data thinning provides an attractive alternative to the "usual" approach of cross-validation via sample splitting, especially in unsupervised settings in which the latter is not applicable. In simulations and in an application to single-cell RNA-sequencing data, we show that data thinning can be used to validate the results of unsupervised learning approaches, such as k-means clustering and principal components analysis.
Inferring independent sets of Gaussian variables after thresholding correlations
Nov 02, 2022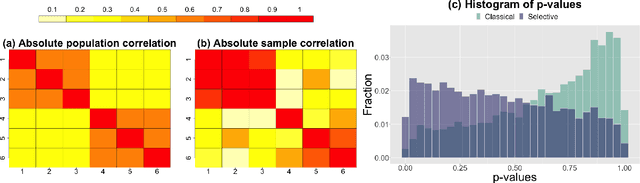



We consider testing whether a set of Gaussian variables, selected from the data, is independent of the remaining variables. We assume that this set is selected via a very simple approach that is commonly used across scientific disciplines: we select a set of variables for which the correlation with all variables outside the set falls below some threshold. Unlike other settings in selective inference, failure to account for the selection step leads, in this setting, to excessively conservative (as opposed to anti-conservative) results. Our proposed test properly accounts for the fact that the set of variables is selected from the data, and thus is not overly conservative. To develop our test, we condition on the event that the selection resulted in the set of variables in question. To achieve computational tractability, we develop a new characterization of the conditioning event in terms of the canonical correlation between the groups of random variables. In simulation studies and in the analysis of gene co-expression networks, we show that our approach has much higher power than a ``naive'' approach that ignores the effect of selection.
Selective Inference for Hierarchical Clustering
Dec 05, 2020
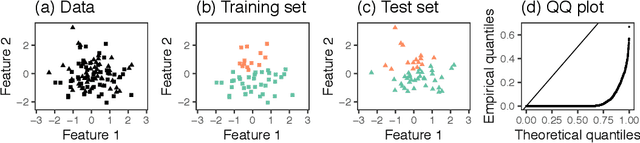

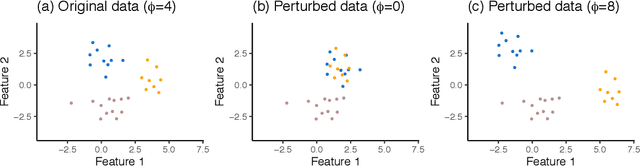
Testing for a difference in means between two groups is fundamental to answering research questions across virtually every scientific area. Classical tests control the Type I error rate when the groups are defined a priori. However, when the groups are instead defined via a clustering algorithm, then applying a classical test for a difference in means between the groups yields an extremely inflated Type I error rate. Notably, this problem persists even if two separate and independent data sets are used to define the groups and to test for a difference in their means. To address this problem, in this paper, we propose a selective inference approach to test for a difference in means between two clusters obtained from any clustering method. Our procedure controls the selective Type I error rate by accounting for the fact that the null hypothesis was generated from the data. We describe how to efficiently compute exact p-values for clusters obtained using agglomerative hierarchical clustering with many commonly used linkages. We apply our method to simulated data and to single-cell RNA-seq data.
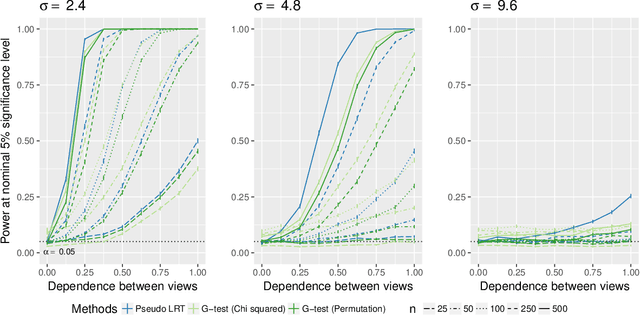
Testing for Association in Multi-View Network Data
Sep 25, 2019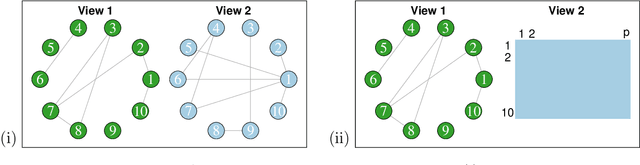
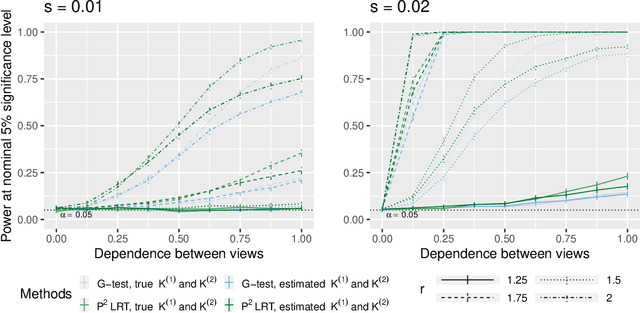
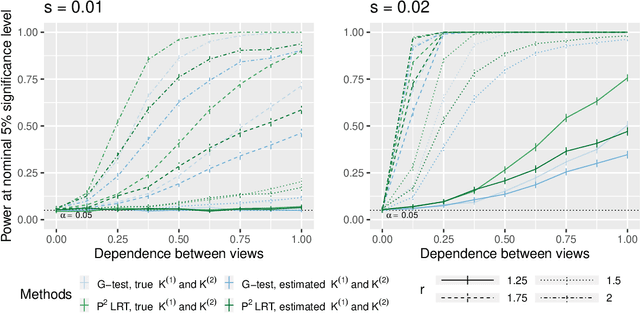
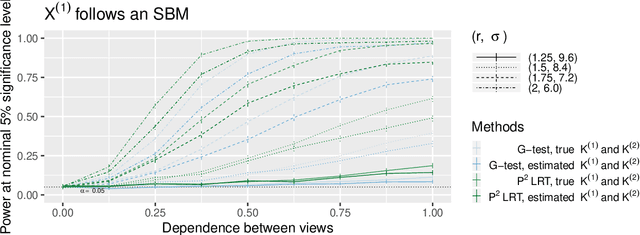
In this paper, we consider data consisting of multiple networks, each comprised of a different edge set on a common set of nodes. Many models have been proposed for such multi-view data, assuming that the data views are closely related. In this paper, we provide tools for evaluating the assumption that there is a relationship between the different views. In particular, we ask: is there an association between the latent community memberships of the nodes within each data view? To answer this question, we extend the stochastic block model for a single network view to two network views, and develop a new hypothesis test for the null hypothesis that the latent community structure within each data view is independent. We apply our test to protein-protein interaction data sets from the HINT database (Das & Yu 2012). We find evidence of a weak association between the latent community structure of proteins defined with respect to binary interaction data and with respect to co-complex association data. We also extend this proposal to the setting of a network with node covariates.
Are Clusterings of Multiple Data Views Independent?
Jan 12, 2019

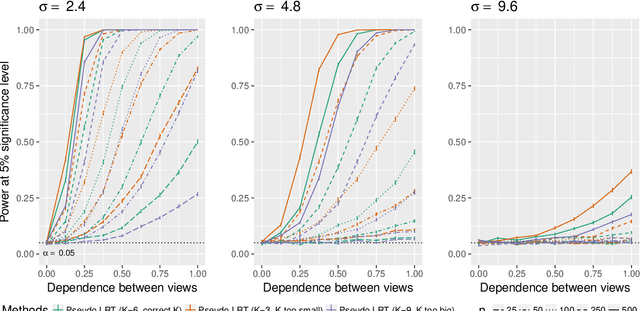
In the Pioneer 100 (P100) Wellness Project (Price and others, 2017), multiple types of data are collected on a single set of healthy participants at multiple timepoints in order to characterize and optimize wellness. One way to do this is to identify clusters, or subgroups, among the participants, and then to tailor personalized health recommendations to each subgroup. It is tempting to cluster the participants using all of the data types and timepoints, in order to fully exploit the available information. However, clustering the participants based on multiple data views implicitly assumes that a single underlying clustering of the participants is shared across all data views. If this assumption does not hold, then clustering the participants using multiple data views may lead to spurious results. In this paper, we seek to evaluate the assumption that there is some underlying relationship among the clusterings from the different data views, by asking the question: are the clusters within each data view dependent or independent? We develop a new test for answering this question, which we then apply to clinical, proteomic, and metabolomic data, across two distinct timepoints, from the P100 study. We find that while the subgroups of the participants defined with respect to any single data type seem to be dependent across time, the clustering among the participants based on one data type (e.g. proteomic data) appears not to be associated with the clustering based on another data type (e.g. clinical data).
Distributionally Robust Reduced Rank Regression and Principal Component Analysis in High Dimensions
Oct 18, 2018
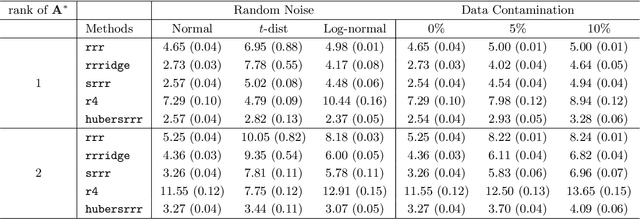
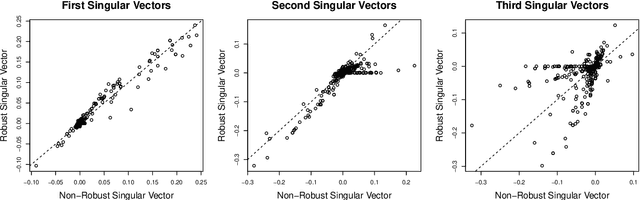
We propose robust sparse reduced rank regression and robust sparse principal component analysis for analyzing large and complex high-dimensional data with heavy-tailed random noise. The proposed methods are based on convex relaxations of rank-and sparsity-constrained non-convex optimization problems, which are solved using the alternating direction method of multipliers (ADMM) algorithm. For robust sparse reduced rank regression, we establish non-asymptotic estimation error bounds under both Frobenius and nuclear norms, while existing results focus mostly on rank-selection and prediction consistency. Our theoretical results quantify the tradeoff between heavy-tailedness of the random noise and statistical bias. For random noise with bounded $(1+\delta)$th moment with $\delta \in (0,1)$, the rate of convergence is a function of $\delta$, and is slower than the sub-Gaussian-type deviation bounds; for random noise with bounded second moment, we recover the results obtained under sub-Gaussian noise. Furthermore, the transition between the two regimes is smooth. For robust sparse principal component analysis, we propose to truncate the observed data, and show that this truncation will lead to consistent estimation of the eigenvectors. We then establish theoretical results similar to those of robust sparse reduced rank regression. We illustrate the performance of these methods via extensive numerical studies and two real data applications.
In Defense of the Indefensible: A Very Naive Approach to High-Dimensional Inference
Dec 07, 2017


In recent years, a great deal of interest has focused on conducting inference on the parameters in a linear model in the high-dimensional setting. In this paper, we consider a simple and very na\"{i}ve two-step procedure for this task, in which we (i) fit a lasso model in order to obtain a subset of the variables; and (ii) fit a least squares model on the lasso-selected set. Conventional statistical wisdom tells us that we cannot make use of the standard statistical inference tools for the resulting least squares model (such as confidence intervals and $p$-values), since we peeked at the data twice: once in running the lasso, and again in fitting the least squares model. However, in this paper, we show that under a certain set of assumptions, with high probability, the set of variables selected by the lasso is deterministic. Consequently, the na\"{i}ve two-step approach can yield confidence intervals that have asymptotically correct coverage, as well as p-values with proper Type-I error control. Furthermore, this two-step approach unifies two existing camps of work on high-dimensional inference: one camp has focused on inference based on a sub-model selected by the lasso, and the other has focused on inference using a debiased version of the lasso estimator.