 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Clusterings of Multiple Data Views Independent?
Paper and Code


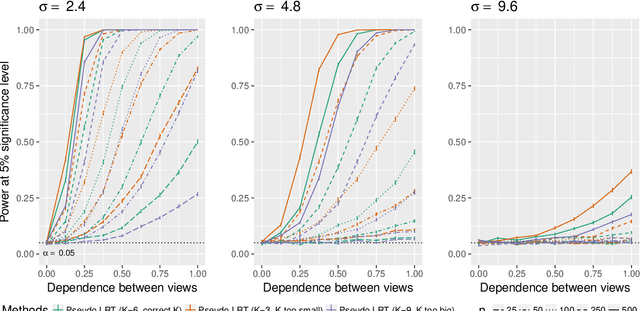
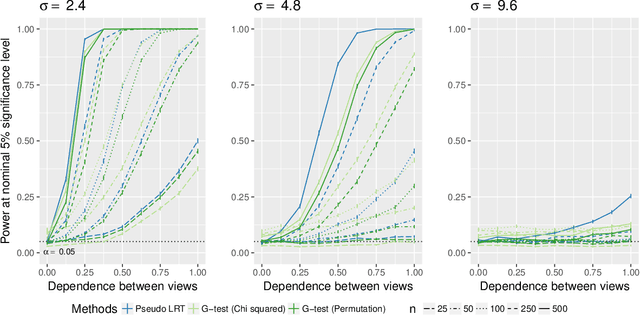
In the Pioneer 100 (P100) Wellness Project (Price and others, 2017), multiple types of data are collected on a single set of healthy participants at multiple timepoints in order to characterize and optimize wellness. One way to do this is to identify clusters, or subgroups, among the participants, and then to tailor personalized health recommendations to each subgroup. It is tempting to cluster the participants using all of the data types and timepoints, in order to fully exploit the available information. However, clustering the participants based on multiple data views implicitly assumes that a single underlying clustering of the participants is shared across all data views. If this assumption does not hold, then clustering the participants using multiple data views may lead to spurious results. In this paper, we seek to evaluate the assumption that there is some underlying relationship among the clusterings from the different data views, by asking the question: are the clusters within each data view dependent or independent? We develop a new test for answering this question, which we then apply to clinical, proteomic, and metabolomic data, across two distinct timepoints, from the P100 study. We find that while the subgroups of the participants defined with respect to any single data type seem to be dependent across time, the clustering among the participants based on one data type (e.g. proteomic data) appears not to be associated with the clustering based on another data type (e.g. clinical data).