 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA study on performance limitations in Federated Learning
Jan 07, 2025



Increasing privacy concerns and unrestricted access to data lead to the development of a novel machine learning paradigm called Federated Learning (FL). FL borrows many of the ideas from distributed machine learning, however, the challenges associated with federated learning makes it an interesting engineering problem since the models are trained on edge devices. It was introduced in 2016 by Google, and since then active research is being carried out in different areas within FL such as federated optimization algorithms, model and update compression, differential privacy, robustness, and attacks, federated GANs and privacy preserved personalization. There are many open challenges in the development of such federated machine learning systems and this project will be focusing on the communication bottleneck and data Non IID-ness, and its effect on the performance of the models. These issues are characterized on a baseline model, model performance is evaluated, and discussions are made to overcome these issues.
Embedding-based Approaches to Hyperpartisan News Detection
Jan 02, 2025


In this paper, we describe our systems in which the objective is to determine whether a given news article could be considered as hyperpartisan. Hyperpartisan news is news that takes an extremely polarized political standpoint with an intention of creating political divide among the public. We attempted several approaches, including n-grams, sentiment analysis, as well as sentence and document representation using pre-tained ELMo. Our best system using pre-trained ELMo with Bidirectional LSTM achieved an accuracy of 83% through 10-fold cross-validation without much hyperparameter tuning.
KANs for Computer Vision: An Experimental Study
Nov 28, 2024



This paper presents an experimental study of Kolmogorov-Arnold Networks (KANs) applied to computer vision tasks, particularly image classification. KANs introduce learnable activation functions on edges, offering flexible non-linear transformations compared to traditional pre-fixed activation functions with specific neural work like Multi-Layer Perceptrons (MLPs) and Convolutional Neural Networks (CNNs). While KANs have shown promise mostly in simplified or small-scale datasets, their effectiveness for more complex real-world tasks such as computer vision tasks remains less explored. To fill this gap, this experimental study aims to provide extended observations and insights into the strengths and limitations of KANs. We reveal that although KANs can perform well in specific vision tasks, they face significant challenges, including increased hyperparameter sensitivity and higher computational costs. These limitations suggest that KANs require architectural adaptations, such as integration with other architectures, to be practical for large-scale vision problems. This study focuses on empirical findings rather than proposing new methods, aiming to inform future research on optimizing KANs, in particular computer vision applications or alike.
Best Practices for Data-Efficient Modeling in NLG:How to Train Production-Ready Neural Models with Less Data
Nov 08, 2020Natural language generation (NLG) is a critical component in conversational systems, owing to its role of formulating a correct and natural text response. Traditionally, NLG components have been deployed using template-based solutions. Although neural network solutions recently developed in the research community have been shown to provide several benefits, deployment of such model-based solutions has been challenging due to high latency, correctness issues, and high data needs. In this paper, we present approaches that have helped us deploy data-efficient neural solutions for NLG in conversational systems to production. We describe a family of sampling and modeling techniques to attain production quality with light-weight neural network models using only a fraction of the data that would be necessary otherwise, and show a thorough comparison between each. Our results show that domain complexity dictates the appropriate approach to achieve high data efficiency. Finally, we distill the lessons from our experimental findings into a list of best practices for production-level NLG model development, and present them in a brief runbook. Importantly, the end products of all of the techniques are small sequence-to-sequence models (2Mb) that we can reliably deploy in production.
Learning Graphical Models With Hubs
Aug 09, 2014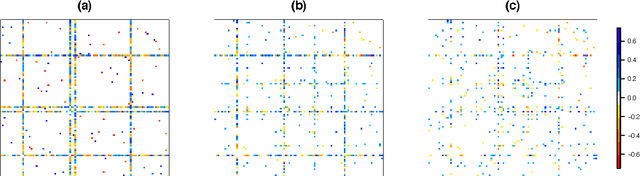
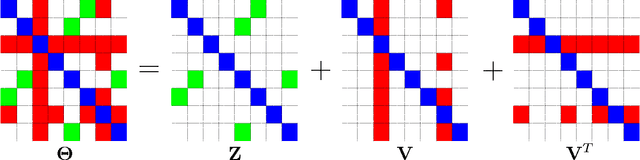
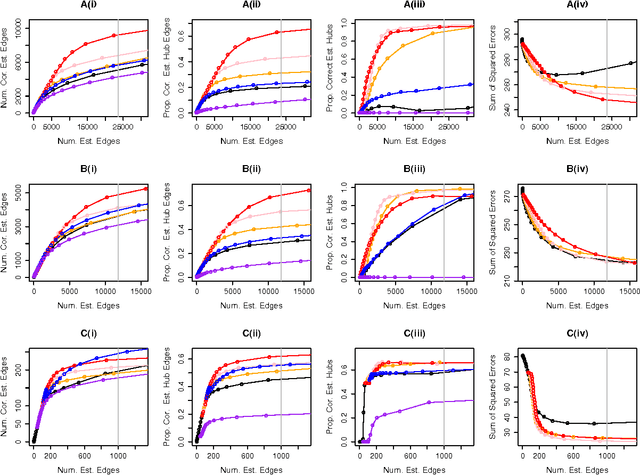
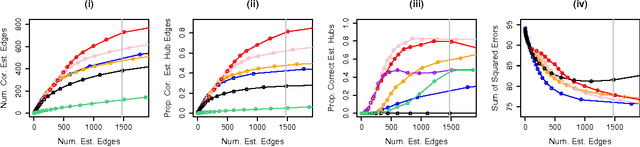
We consider the problem of learning a high-dimensional graphical model in which certain hub nodes are highly-connected to many other nodes. Many authors have studied the use of an l1 penalty in order to learn a sparse graph in high-dimensional setting. However, the l1 penalty implicitly assumes that each edge is equally likely and independent of all other edges. We propose a general framework to accommodate more realistic networks with hub nodes, using a convex formulation that involves a row-column overlap norm penalty. We apply this general framework to three widely-used probabilistic graphical models: the Gaussian graphical model, the covariance graph model, and the binary Ising model. An alternating direction method of multipliers algorithm is used to solve the corresponding convex optimization problems. On synthetic data, we demonstrate that our proposed framework outperforms competitors that do not explicitly model hub nodes. We illustrate our proposal on a webpage data set and a gene expression data set.
Node-Based Learning of Multiple Gaussian Graphical Models
Jan 22, 2014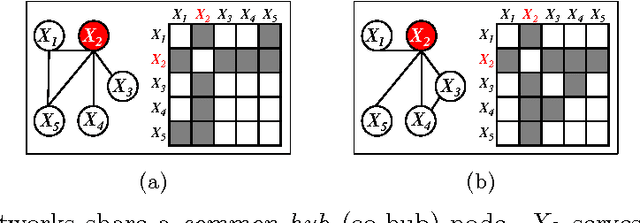

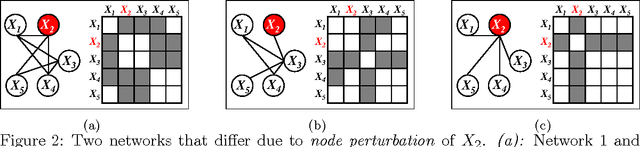

We consider the problem of estimating high-dimensional Gaussian graphical models corresponding to a single set of variables under several distinct conditions. This problem is motivated by the task of recovering transcriptional regulatory networks on the basis of gene expression data {containing heterogeneous samples, such as different disease states, multiple species, or different developmental stages}. We assume that most aspects of the conditional dependence networks are shared, but that there are some structured differences between them. Rather than assuming that similarities and differences between networks are driven by individual edges, we take a node-based approach, which in many cases provides a more intuitive interpretation of the network differences. We consider estimation under two distinct assumptions: (1) differences between the K networks are due to individual nodes that are perturbed across conditions, or (2) similarities among the K networks are due to the presence of common hub nodes that are shared across all K networks. Using a row-column overlap norm penalty function, we formulate two convex optimization problems that correspond to these two assumptions. We solve these problems using an alternating direction method of multipliers algorithm, and we derive a set of necessary and sufficient conditions that allows us to decompose the problem into independent subproblems so that our algorithm can be scaled to high-dimensional settings. Our proposal is illustrated on synthetic data, a webpage data set, and a brain cancer gene expression data set.
ADMM Algorithm for Graphical Lasso with an $\ell_{\infty}$ Element-wise Norm Constraint
Nov 28, 2013We consider the problem of Graphical lasso with an additional $\ell_{\infty}$ element-wise norm constraint on the precision matrix. This problem has applications in high-dimensional covariance decomposition such as in \citep{Janzamin-12}. We propose an ADMM algorithm to solve this problem. We also use a continuation strategy on the penalty parameter to have a fast implemenation of the algorithm.