 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePASTO: Strategic Parameter Optimization in Recommendation Systems -- Probabilistic is Better than Deterministic
Aug 20, 2021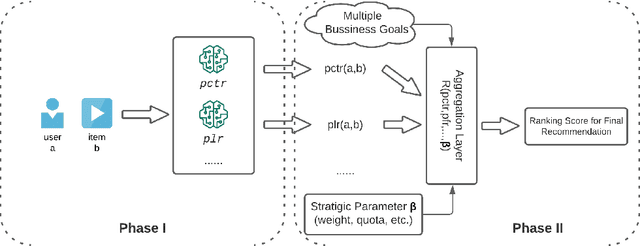
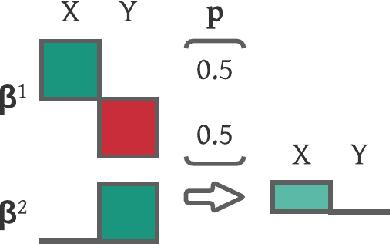

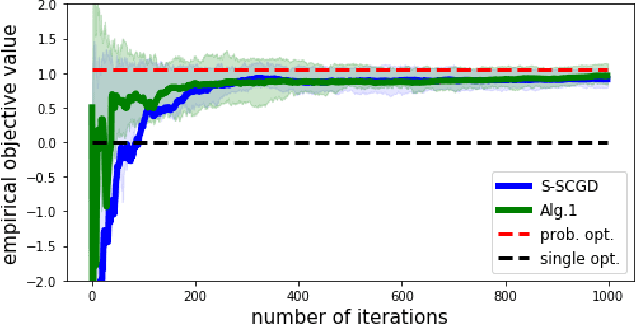
Real-world recommendation systems often consist of two phases. In the first phase, multiple predictive models produce the probability of different immediate user actions. In the second phase, these predictions are aggregated according to a set of 'strategic parameters' to meet a diverse set of business goals, such as longer user engagement, higher revenue potential, or more community/network interactions. In addition to building accurate predictive models, it is also crucial to optimize this set of 'strategic parameters' so that primary goals are optimized while secondary guardrails are not hurt. In this setting with multiple and constrained goals, this paper discovers that a probabilistic strategic parameter regime can achieve better value compared to the standard regime of finding a single deterministic parameter. The new probabilistic regime is to learn the best distribution over strategic parameter choices and sample one strategic parameter from the distribution when each user visits the platform. To pursue the optimal probabilistic solution, we formulate the problem into a stochastic compositional optimization problem, in which the unbiased stochastic gradient is unavailable. Our approach is applied in a popular social network platform with hundreds of millions of daily users and achieves +0.22% lift of user engagement in a recommendation task and +1.7% lift in revenue in an advertising optimization scenario comparing to using the best deterministic parameter strategy.
Short Video-based Advertisements Evaluation System: Self-Organizing Learning Approach
Oct 23, 2020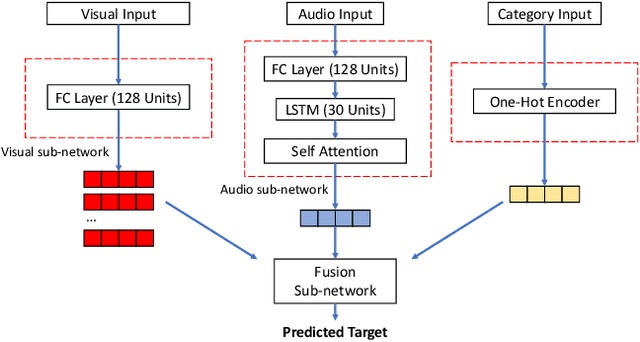
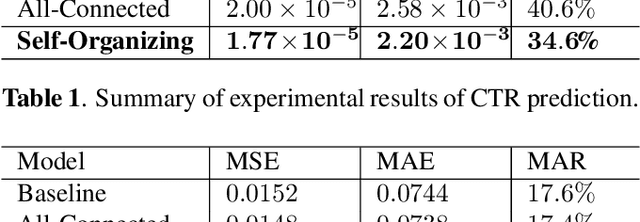
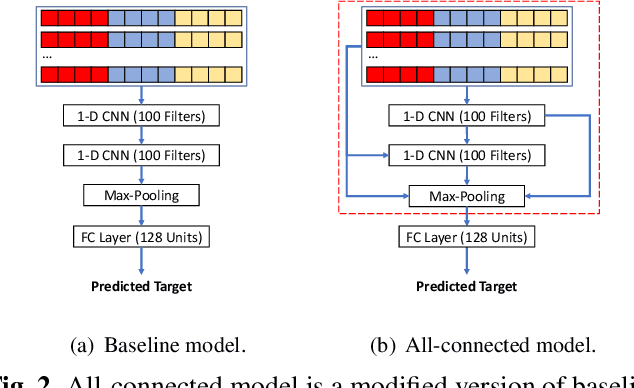
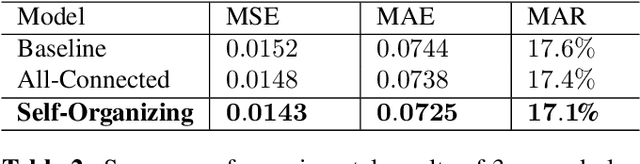
With the rising of short video apps, such as TikTok, Snapchat and Kwai, advertisement in short-term user-generated videos (UGVs) has become a trending form of advertising. Prediction of user behavior without specific user profile is required by advertisers, as they expect to acquire advertisement performance in advance in the scenario of cold start. Current recommender system do not take raw videos as input; additionally, most previous work of Multi-Modal Machine Learning may not deal with unconstrained videos like UGVs. In this paper, we proposed a novel end-to-end self-organizing framework for user behavior prediction. Our model is able to learn the optimal topology of neural network architecture, as well as optimal weights, through training data. We evaluate our proposed method on our in-house dataset. The experimental results reveal that our model achieves the best performance in all our experiments.
Matrix Completion via Factorizing Polynomials
Feb 14, 2018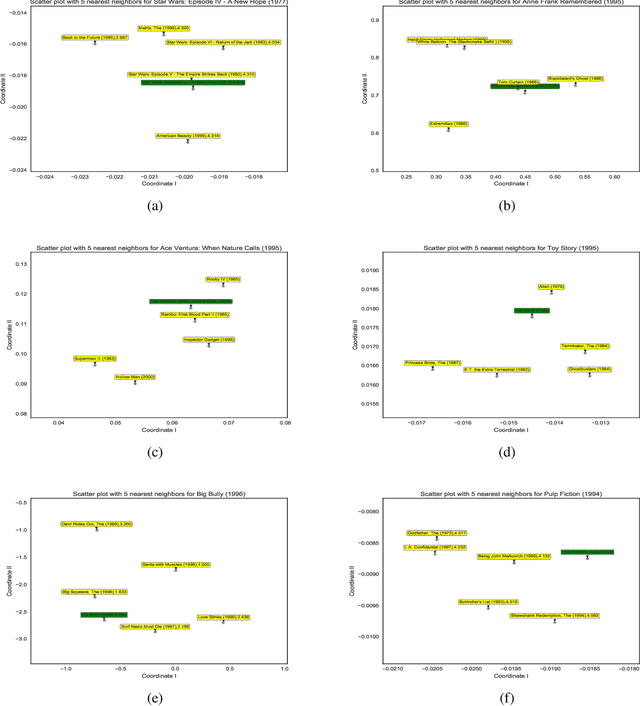

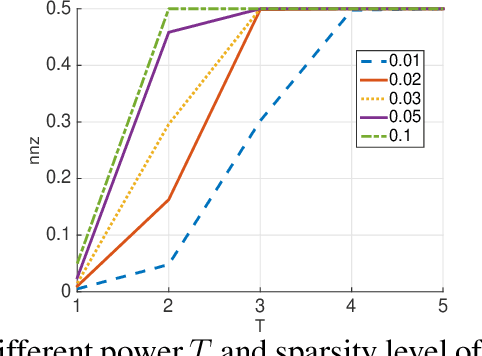
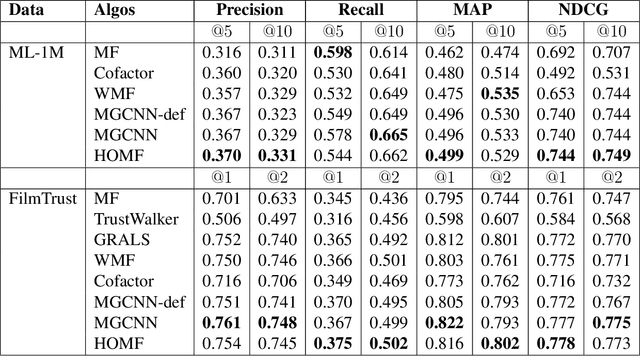
Predicting unobserved entries of a partially observed matrix has found wide applicability in several areas, such as recommender systems, computational biology, and computer vision. Many scalable methods with rigorous theoretical guarantees have been developed for algorithms where the matrix is factored into low-rank components, and embeddings are learned for the row and column entities. While there has been recent research on incorporating explicit side information in the low-rank matrix factorization setting, often implicit information can be gleaned from the data, via higher-order interactions among entities. Such implicit information is especially useful in cases where the data is very sparse, as is often the case in real-world datasets. In this paper, we design a method to learn embeddings in the context of recommendation systems, using the observation that higher powers of a graph transition probability matrix encode the probability that a random walker will hit that node in a given number of steps. We develop a coordinate descent algorithm to solve the resulting optimization, that makes explicit computation of the higher order powers of the matrix redundant, preserving sparsity and making computations efficient. Experiments on several datasets show that our method, that can use higher order information, outperforms methods that only use explicitly available side information, those that use only second-order implicit information and in some cases, methods based on deep neural networks as well.
Dynamic Word Embeddings for Evolving Semantic Discovery
Feb 13, 2018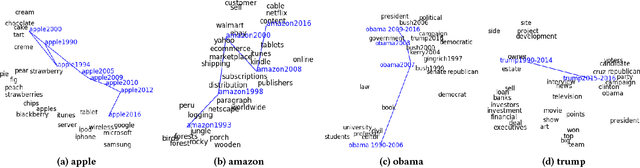
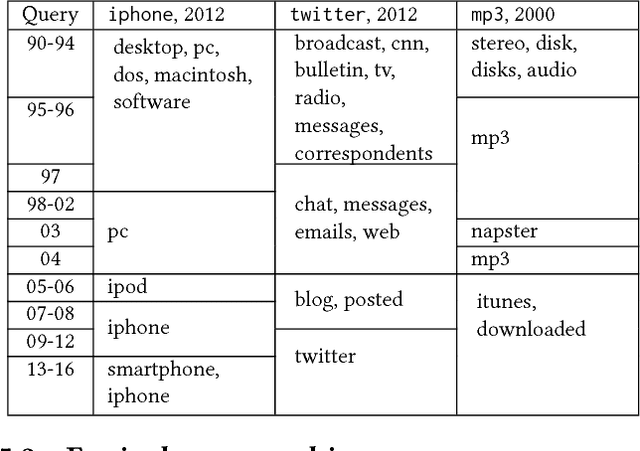
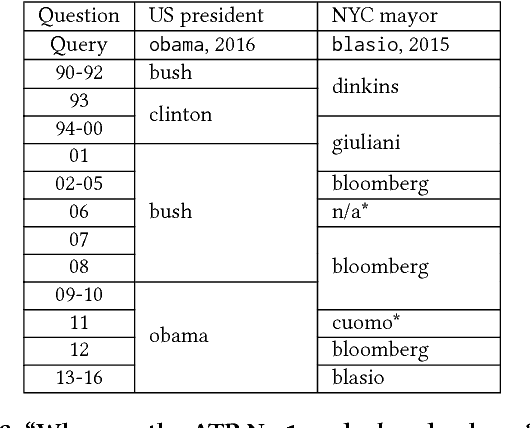
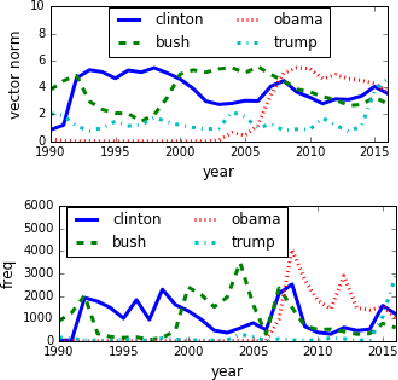
Word evolution refers to the changing meanings and associations of words throughout time, as a byproduct of human language evolution. By studying word evolution, we can infer social trends and language constructs over different periods of human history. However, traditional techniques such as word representation learning do not adequately capture the evolving language structure and vocabulary. In this paper, we develop a dynamic statistical model to learn time-aware word vector representation. We propose a model that simultaneously learns time-aware embeddings and solves the resulting "alignment problem". This model is trained on a crawled NYTimes dataset. Additionally, we develop multiple intuitive evaluation strategies of temporal word embeddings. Our qualitative and quantitative tests indicate that our method not only reliably captures this evolution over time, but also consistently outperforms state-of-the-art temporal embedding approaches on both semantic accuracy and alignment quality.
A Simple Approach to Learn Polysemous Word Embeddings
Aug 14, 2017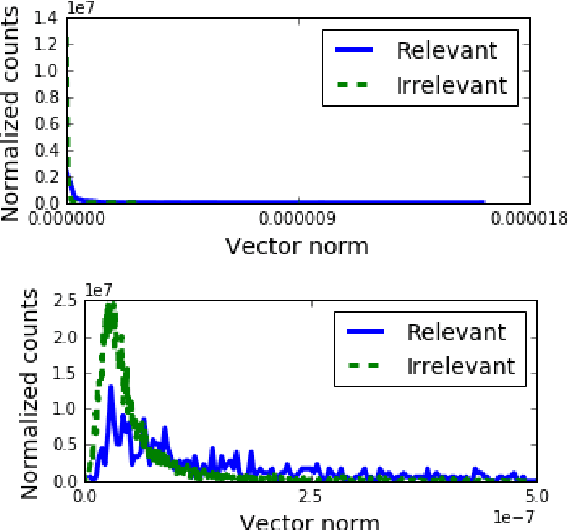
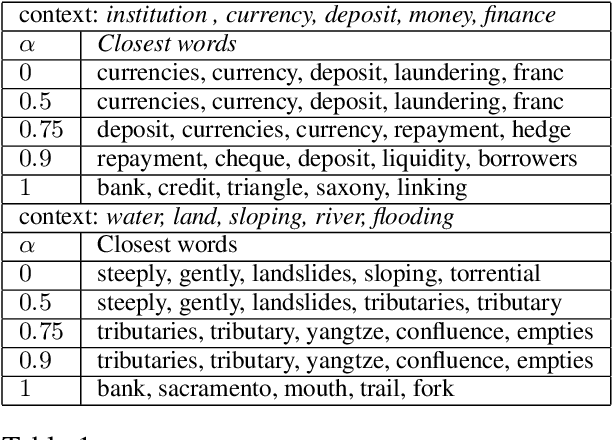
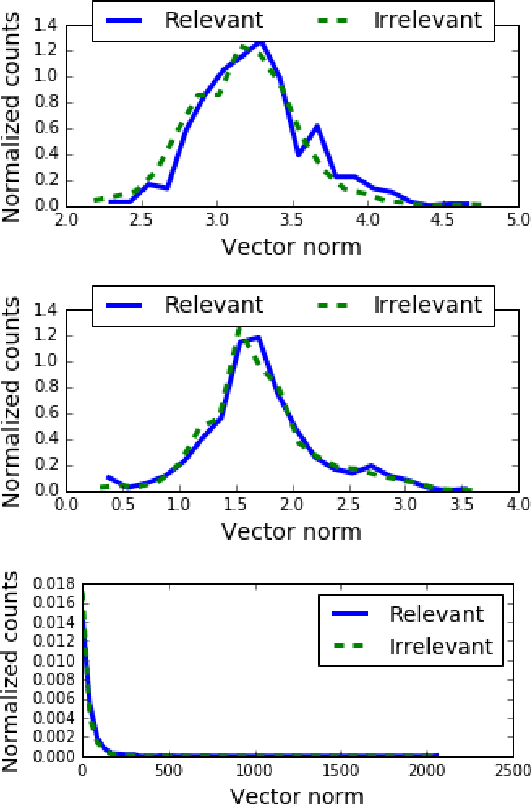
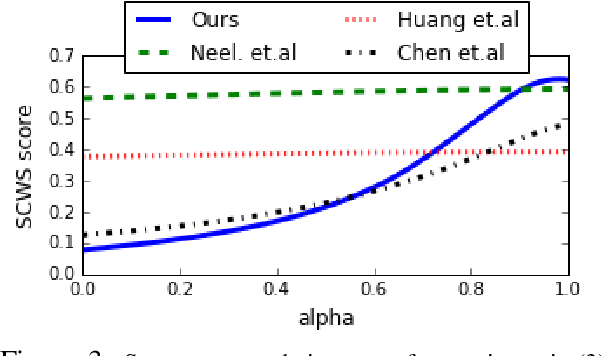
Many NLP applications require disambiguating polysemous words. Existing methods that learn polysemous word vector representations involve first detecting various senses and optimizing the sense-specific embeddings separately, which are invariably more involved than single sense learning methods such as word2vec. Evaluating these methods is also problematic, as rigorous quantitative evaluations in this space is limited, especially when compared with single-sense embeddings. In this paper, we propose a simple method to learn a word representation, given any context. Our method only requires learning the usual single sense representation, and coefficients that can be learnt via a single pass over the data. We propose several new test sets for evaluating word sense induction, relevance detection, and contextual word similarity, significantly supplementing the currently available tests. Results on these and other tests show that while our method is embarrassingly simple, it achieves excellent results when compared to the state of the art models for unsupervised polysemous word representation learning.
Node Embedding via Word Embedding for Network Community Discovery
Jun 28, 2017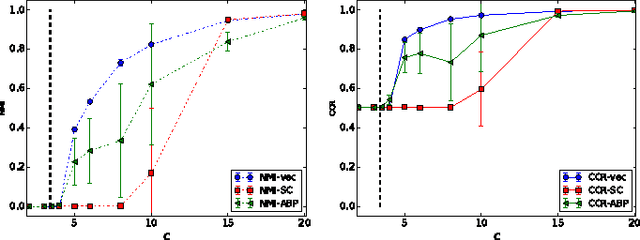
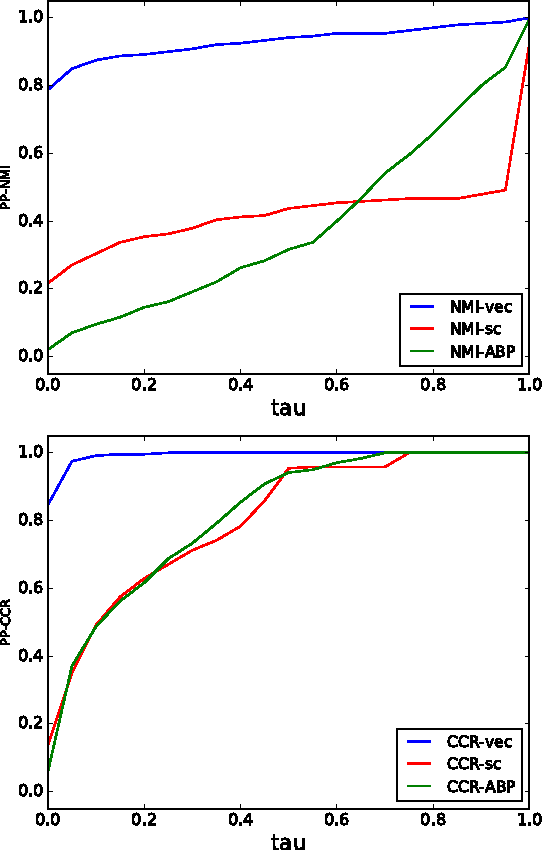
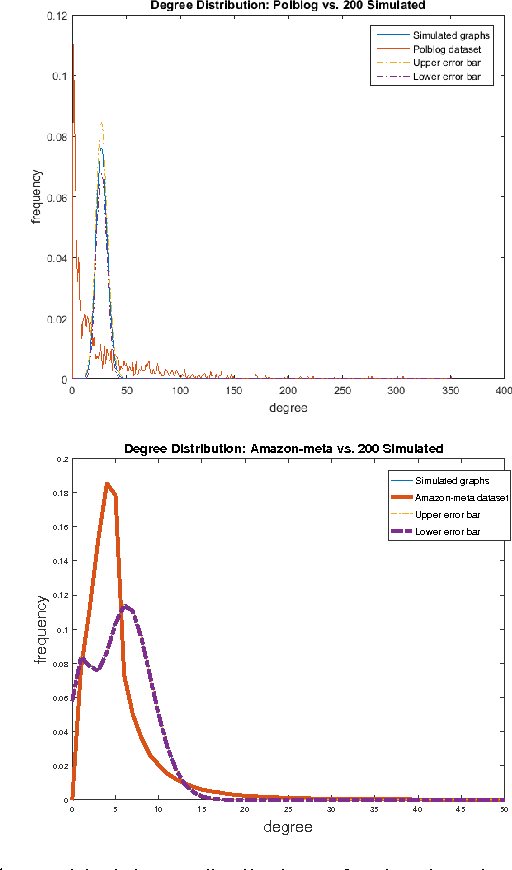
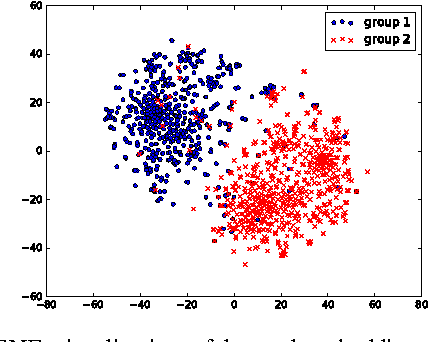
Neural node embeddings have recently emerged as a powerful representation for supervised learning tasks involving graph-structured data. We leverage this recent advance to develop a novel algorithm for unsupervised community discovery in graphs. Through extensive experimental studies on simulated and real-world data, we demonstrate that the proposed approach consistently improves over the current state-of-the-art. Specifically, our approach empirically attains the information-theoretic limits for community recovery under the benchmark Stochastic Block Models for graph generation and exhibits better stability and accuracy over both Spectral Clustering and Acyclic Belief Propagation in the community recovery limits.
Necessary and Sufficient Conditions and a Provably Efficient Algorithm for Separable Topic Discovery
Dec 04, 2015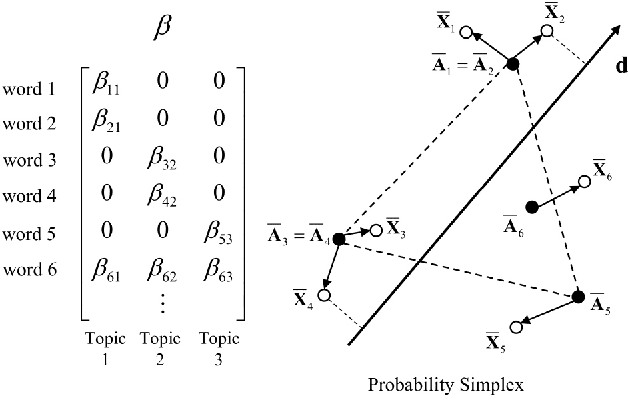
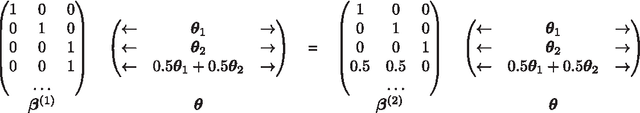
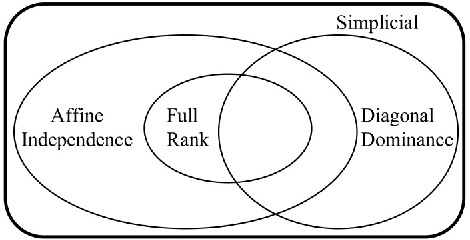
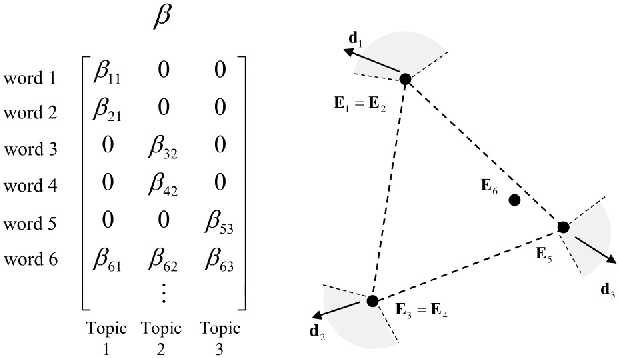
We develop necessary and sufficient conditions and a novel provably consistent and efficient algorithm for discovering topics (latent factors) from observations (documents) that are realized from a probabilistic mixture of shared latent factors that have certain properties. Our focus is on the class of topic models in which each shared latent factor contains a novel word that is unique to that factor, a property that has come to be known as separability. Our algorithm is based on the key insight that the novel words correspond to the extreme points of the convex hull formed by the row-vectors of a suitably normalized word co-occurrence matrix. We leverage this geometric insight to establish polynomial computation and sample complexity bounds based on a few isotropic random projections of the rows of the normalized word co-occurrence matrix. Our proposed random-projections-based algorithm is naturally amenable to an efficient distributed implementation and is attractive for modern web-scale distributed data mining applications.
Learning Mixed Membership Mallows Models from Pairwise Comparisons
Apr 03, 2015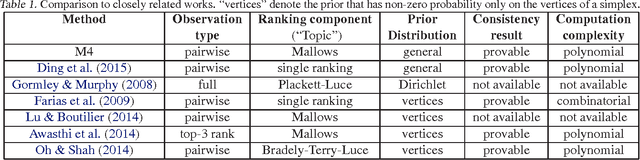
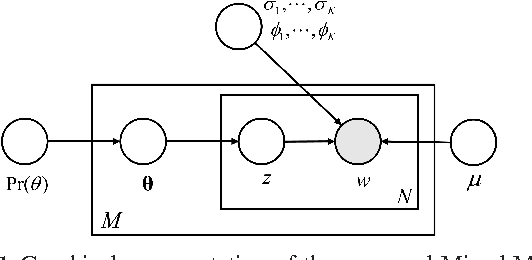
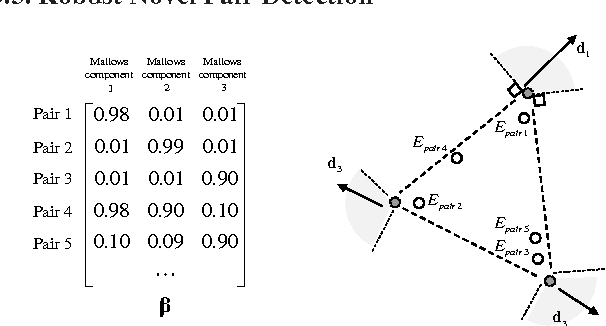
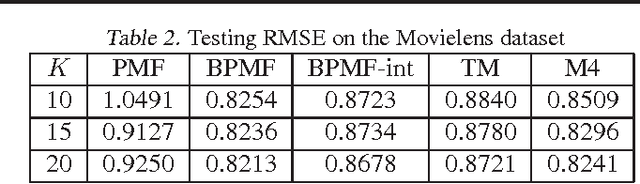
We propose a novel parameterized family of Mixed Membership Mallows Models (M4) to account for variability in pairwise comparisons generated by a heterogeneous population of noisy and inconsistent users. M4 models individual preferences as a user-specific probabilistic mixture of shared latent Mallows components. Our key algorithmic insight for estimation is to establish a statistical connection between M4 and topic models by viewing pairwise comparisons as words, and users as documents. This key insight leads us to explore Mallows components with a separable structure and leverage recent advances in separable topic discovery. While separability appears to be overly restrictive, we nevertheless show that it is an inevitable outcome of a relatively small number of latent Mallows components in a world of large number of items. We then develop an algorithm based on robust extreme-point identification of convex polygons to learn the reference rankings, and is provably consistent with polynomial sample complexity guarantees. We demonstrate that our new model is empirically competitive with the current state-of-the-art approaches in predicting real-world preferences.
A Topic Modeling Approach to Ranking
Jan 25, 2015
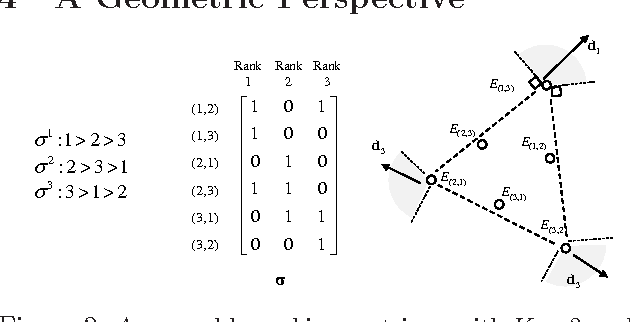
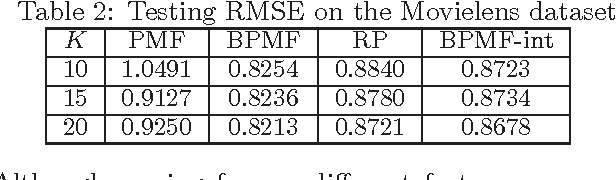
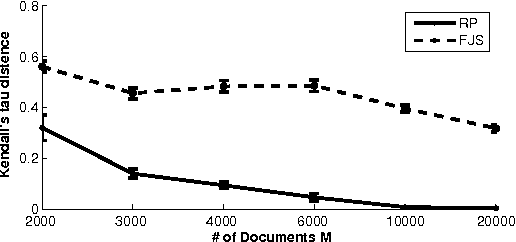
We propose a topic modeling approach to the prediction of preferences in pairwise comparisons. We develop a new generative model for pairwise comparisons that accounts for multiple shared latent rankings that are prevalent in a population of users. This new model also captures inconsistent user behavior in a natural way. We show how the estimation of latent rankings in the new generative model can be formally reduced to the estimation of topics in a statistically equivalent topic modeling problem. We leverage recent advances in the topic modeling literature to develop an algorithm that can learn shared latent rankings with provable consistency as well as sample and computational complexity guarantees. We demonstrate that the new approach is empirically competitive with the current state-of-the-art approaches in predicting preferences on some semi-synthetic and real world datasets.
Sensing-Aware Kernel SVM
Mar 13, 2014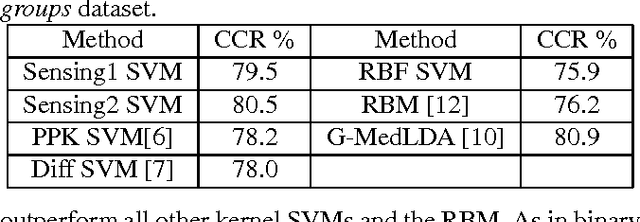
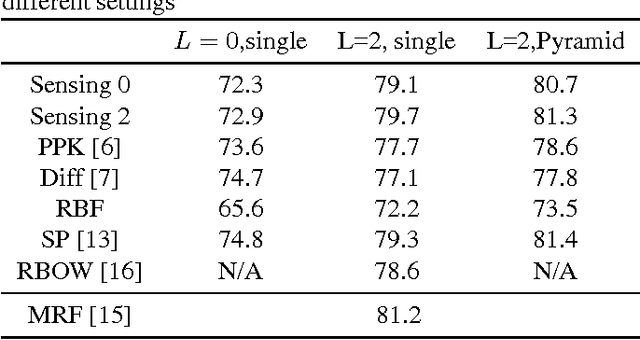
We propose a novel approach for designing kernels for support vector machines (SVMs) when the class label is linked to the observation through a latent state and the likelihood function of the observation given the state (the sensing model) is available. We show that the Bayes-optimum decision boundary is a hyperplane under a mapping defined by the likelihood function. Combining this with the maximum margin principle yields kernels for SVMs that leverage knowledge of the sensing model in an optimal way. We derive the optimum kernel for the bag-of-words (BoWs) sensing model and demonstrate its superior performance over other kernels in document and image classification tasks. These results indicate that such optimum sensing-aware kernel SVMs can match the performance of rather sophisticated state-of-the-art approaches.